前言
图像分割在计算机视觉中是个重要的任务,在地理信息系统、医学影像、自动驾驶、机器人等领域都有着很重要的应用技术支持作用。本篇博客主要做了一个图像分割算法的综述,从两方面进行论述,一个是语义分割,在前面博客也提到相关的算法,详见Deeplab语义分割。另一方面是实例分割,详见实例分割综述,MaskRCNN。
语义分割
语义分割的目的是为了从像素级别理解图像的内容,并为图像中的每个像素分配一个对象类。语义分割的方法分别有Semantic Segmentation by Patch Classification,FCN for Semantic Segmentation,U-Net for medical engineering,SegNet,DeepLab,关于各个方法的思路和实现方式可以参考:Deeplab语义分割和一文读懂语义分割与实例分割。
实例分割
实例分割的目的是将输入图像中的目标检测出来,并且对目标的每个像素分配类别标签。实例分割能够对前景语义类别相同的不同实例进行区分。实例分割模型一般由三部分组成:图像输入、实例分割处理、分割结果输出。实例分割存在的问题以及难点如下:
- 小物体分割问题。这也是计算机视频普通的痛点难点
- 处理集合变换问题
- 处理遮挡问题
- 处理图像退化问题
技术路线
实例分割主要有两条技术路线,一个是自下而上基于语义分割的方法和自上而下基于检测的方法。这两种方法都是two-stage方法。
-
自上而下的实例分割方法
该类方法首先通过目标检测的找出实例所在的区域,然后在检测框进行语义分割,每个分割的结果都作为一个不同实例的输出。该类方法有FCIS,MaskRCNN,PANet,Mask Scoring R-CNN。自上而下的密集实例分割的开山鼻祖是DeepMask,该方法通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal,这个方法也存在明显的缺点:mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask;特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask;下采样(使用步长大于1的卷积)导致的位置信息丢失 -
自下而上的实例分割方法
将每个实例看成一个类别,然后按照聚类的思路,最大类间距,最小类内距,对每个像素做embedding,最后做grouping分出不同的实例。Grouping的方法一般bottom-up效果差于top-down。这种方法虽然保持了更好的底层特征,但是存在以下缺点对密集分割的质量要求很高,会导致非最优的分割;泛化能力较差,无法应对类别多的复杂场景;后处理方法繁琐。 -
单阶段实例分割
该类方法有两种思路,一种是受one-stage,anchor-base检测模型的启发研究得出的,如YOLOACT和SOLO;另一种是受到anchor-free检测模型启发,如PolarMask和AdaptIS。
综上所述,实例分割方法的发展历程主要脉络图如下:
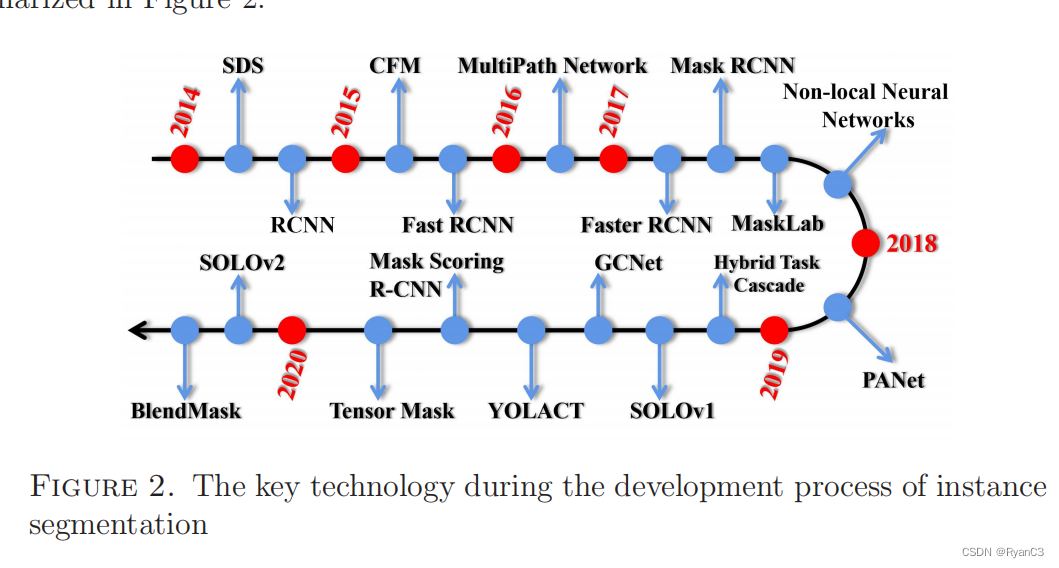
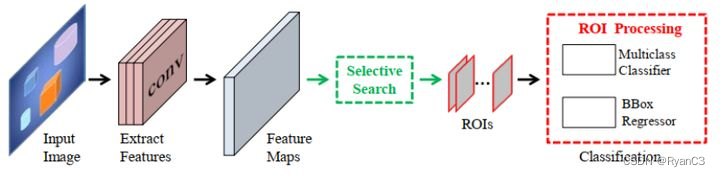
掩膜建议分类法
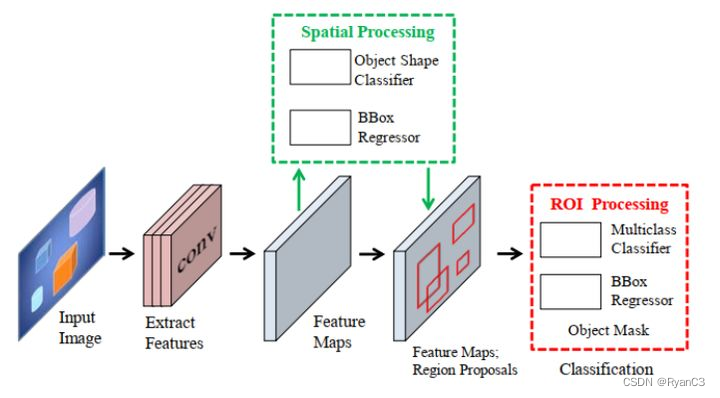
先检测再分割法
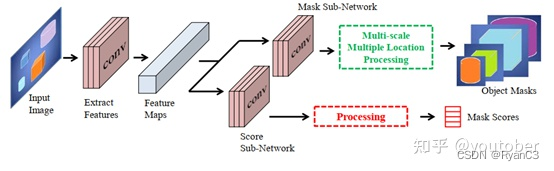
标记像素后聚类法

密集滑动窗口法
后面的方法可以查阅参考1或者各种方法对应的论文,这里就不做一一叙述了。