1 逻辑回归处理多分类的原理
对于数据集中存在多个类别的分类问题,我们可以采用一种叫做 One-vs-rest 的方法,将其转化成二元分类的问题,然后再进行解决。
前面的是对于二元分类问题,应该如何去处理其预测函数、代价函数和梯度下降算法。
但是多元的分类才是生活常见的情况。
例如对于邮件,我们可以分为工作、 朋友、家人、兴趣;
例如对于天气,我们可以分为晴朗、多云、下雨、有雪。
对于这样的多元分类,应该如何处理呢?
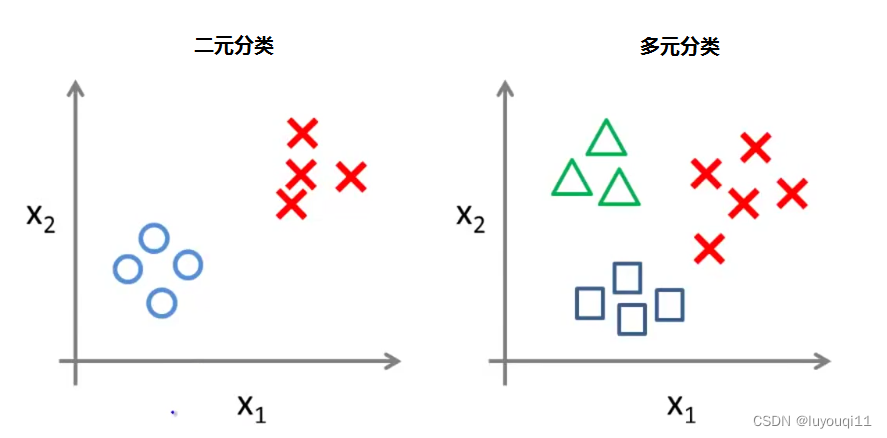
分类情况
其实很简单,把多元分类划分为多个二元分类就可以了:

这样我们就能将多元分类问题当成二元分类问题进行解决。
对于上面图片中的三种分类,可以列一下预测函数的公式:
- 分类1:


- 分类2:


- 分类3:


我们预测的时候,分别将x代入到三个公式中,计算三者的概率,其中概率最大的,就是我们的预测结果。
例如我们发现 P(y=1 | x; θ) 的概率最大,那么我们就预测这个图形是绿色的三角形。
把公式写得更加通用一点,如下:
y∈{0,1,…,n}
![]()
![]()
……
![]()
最后,如果给出一个新的值 x,用该模型进行预测,就需要分别使用三个分类器进行计算,找到最大的那个 ![]() ,x 就属于那个类别。即:
,x 就属于那个类别。即:
![]()
剩下的,就是二元分类模型需要做的事情了。
2 示例:【python】使用逻辑回归识别手写数字(从0到9)
样本数据ex3data1.mat
数据以.mat格式储存,mat格式是matlab的数据存储格式,按照矩阵保存,与numpy数据格式兼容,适合于各种数学运算,因此主要使用numpy进行运算。
ex3data1.mat中有5000个训练样例,其中每个训练样例是一个20像素×20像素灰度图像的数字,每个像素由一个浮点数表示,该浮点数表示该位置的灰度强度。每个20×20像素的网格被展开成一个400维的向量。这些每个训练样例都变成数据矩阵X中的一行。这就得到了一个5000×400矩阵X,其中每一行都是手写数字图像的训练样例。
训练集的第二部分是一个包含训练集标签的5000维向量y,“0”的数字标记为“10”,而“1”到“9”的数字按自然顺序标记为“1”到“9”。
Python代码
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
# 1 读入数据 :sio.loadmat 读取mat后,为dict类型
path = 'D:/dataAnalysis/MachineLearning/ex3data1.mat'
data = sio.loadmat(path)
#print(data)
print('数据的类型:',type(data))
print('数据中的键名:',data.keys())
raw_X = data['X']
raw_Y = data['y']
print('输入特征(5000个手写数字图片,每个图片20x20像素)的形状:',raw_X.shape) # (5000, 400)
print('输出特征(标明每个手写数字图片是和数字)的的形状:',raw_Y.shape) # (5000, 1)# 2 画出数据集里的数字图片
# 2.1 画出数据集里的1个随机数字图片
def plot_an_image(X):
pick_one = np.random.randint(5000) # 从数据集中随机选出1个图片
image = X[pick_one, :]
print('1个随机数字图片')
fig, ax = plt.subplots(figsize=(1, 1))#设置图片尺寸
ax.imshow(image.reshape(20, 20).T, cmap='gray_r')
plt.xticks([])
plt.yticks([])
plot_an_image(raw_X)
plt.show()
# 2.2 画出数据集里的100个随机数字图片
def plot_100_images(X):
sample_index = np.random.choice(len(X), 100)#随机选取数据集里100个数据
images = X[sample_index, :]
print('100个随机数字图片')
print(images.shape)
#定义10*10的子画布
fig, ax = plt.subplots(ncols=10, nrows=10, figsize=(8, 8), sharex=True, sharey=True)
#在每个子画布中画出一个数字
for r in range(10):#行
for c in range(10):#列
ax[r, c].imshow(images[10 * r + c].reshape(20, 20).T, cmap='gray_r')
#去掉坐标轴
plt.xticks([])
plt.yticks([])
plt.show()
plot_100_images(raw_X)
plt.show()# 3 损失函数 ,找出最小的损失函数
# 3.1 定义sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 3.2 损失函数计算
def Cost_Function(theta, X, y, lamda):
A = sigmoid(X @ theta)
first = y * np.log(A)
second = (1 - y) * np.log(1 - A)
reg = np.sum(np.power(theta[1:], 2)) * (lamda / (2 * len(X)))
return -np.sum(first + second) / len(X) + reg
# 3.3 梯度下降
def gradient_reg(theta, X, y, lamda):
reg = theta[1:] * (lamda / len(X))
reg = np.insert(reg, 0, values=0, axis=0)#插入第一行0
first = (X.T @ (sigmoid(X @ theta) - y)) / len(X)
return first + reg
# 4 数据处理
X = np.insert(raw_X, 0, values=1, axis=1) # 在输入特征最前面插一列全1
print(f'在输入特征最前面插一列全1后的形状:',X.shape) # (5000, 401)
y = raw_Y.flatten() # 展开输出特征矩阵
print(f'输出特征矩阵展开为数组后形状:',y.shape) # (5000,)
# 5 一对多分类
# 利用for循环对每种数字习得一个带正则的逻辑回归分类器,
# 然后将10个分类器的参数组成一个参数矩阵theta_all返回
# 利用内置函数求最优化
from scipy.optimize import minimize
# K为标签个数
def one_vs_all(X, y, lamda, K):
n = X.shape[1]#X的列数401
theta_all = np.zeros((K, n))#(10,401)
#第0列到第9列分别对应类别1到10
for i in range(1, K + 1):#遍历到k 1-k 对应1-10
theta_i = np.zeros(n, )#传入minimize的必须是一维(401,)
res = minimize(fun=Cost_Function,
x0=theta_i,
args=(X, y == i, lamda),
method='TNC',
jac=gradient_reg
)
theta_all[i - 1, :] = res.x #将字典中x(theta)的值赋给theta
#[i-1,:]与索引对应(0,9)
return theta_all
lamda = 1
K = 10
theta_final = one_vs_all(X, y, lamda, K)
print('最后的参数: ',theta_final)
# 6 预测
# 得到一个5000乘10的预测概率矩阵,找到每一行的概率最大的值位置,
# 得到预测的类别,再和期望值y比较得到精度。
def predict(X, theta_final):
# (5000,401) (10,401) => (5000,10)
h = sigmoid(X @ theta_final.T)#假设函数,输出h为1的概率
h_argmax = np.argmax(h, axis=1)#按行返回概率最大的数字索引
return h_argmax+1 #索引+1对应数字
y_pred = predict(X, theta_final)
acc = np.mean(y_pred == y)
# 0.9446
print('预测准确度:',acc)
执行结果如下:
