1. 问题和数据
自动手写数字识别在今天被广泛使用——从识别信封上的邮政编码(邮政编码)到识别银行支票上写的金额。这个练习将向您展示如何将您所学到的方法用于这个分类任务。在本练习中,您将使用逻辑回归和神经网络来识别手写数字(从0到9)。
我们将扩展我们在练习2中写的逻辑回归的实现,并将其应用于一对一的分类。
ex3data1.mat中有5000个训练示例。其中每个训练示例是一个20像素× 20像素的数字灰度图像。每个像素都由一个浮点数表示,该浮点数表示该位置的灰度强度。20 × 20像素网格被“展开”成400维向量。每个训练示例都成为数据矩阵X中的一行。这给了我们一个5000乘400的矩阵X,其中每一行都是一个手写数字图像的训练示例。

因为数据ex2data1.mat太多了,这次就不可能列出来了。但是我们依然可以打印看一下它的特征。
2. 数据导入与初步分析
导入包,numpy和pandas是做运算的库,matplotlib是画图的库。
数据集是在MATLAB的格式,所以要加载它在Python,我们需要使用一个SciPy工具。

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat # 让我们开始加载数据集。它是在MATLAB的本机格式,所以要加载它在Python,我们需要使用一个SciPy工具。
from scipy.optimize import minimize # 本次不用for循环迭代,太慢了,改用scipy 优化库自动优化得出minimize值
导入数据集 ,先读取数据打印出来观察一下
# 先读取数据打印出来观察一下
data = sio.loadmat('ex3data1.mat') # 加载数据
print(data) # 打印数据看一下
print(data.keys(), 'data.keys')
输出是一个字典,分别是’key’:‘键’
运行结果如下:
{
'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 16 13:09:09 2011', '__version__': '1.0', '__globals__': [], 'X': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]), 'y': array([[10],
[10],
[10],
...,
[ 9],
[ 9],
[ 9]], dtype=uint8)}
dict_keys(['__header__', '__version__', '__globals__', 'X', 'y']) data.keys
再取出X和y,打印出来看一看
raw_X = data['X']
raw_y = data['y']
print(raw_X.shape, "raw_X.shape") # 打印X的shape,看它有几行几列
print(raw_y.shape, "raw_y.shape") # 打印y的shape,看它有几行几列
输出结果:
(5000, 400) raw_X.shape
(5000, 1) raw_y.shape
现在,我们已经加载好了我们的数据。图像在martix X中表示为400维向量(其中有5,000个)。400维特征是原始20×20图像中每个像素的灰度强度,类标签在向量y中作为表示图像中数字的数字类。
其实X是相当于5000行一列(5000,1)的5000张图片排成一列的,只是每张图片又是20×20的像素,所以写成(5000,400);y也是(5000,1)。
先将样本图片打印出来看看
# 打印1张图片出来看看
def plot_an_image(X):
pick_one = np.random.randint(5000) # randint是随机选择整数类型,但只能选一个
image = X[pick_one, :]
fig, ax = plt.subplots(figsize=(1, 1))
ax.imshow(image.reshape(20, 20).T, cmap='gray_r') # 将随机选中的X由400reshape成20*20的格式,才是图片,再.T转置才是能看懂的图
plt.xticks([]) # 去掉横坐标值
plt.yticks([]) # 去掉纵坐标值
plt.show()
plot_an_image(raw_X)
输出显示结果:

打印100张图片出来看看
def plot_100_image(X):
sample_index = np.random.choice(len(X), 100) # choice可以随机选择很多个整数类型,lem(X)=5000,即5000里随机选100个
images = X[sample_index, :]
print(images.shape)
fig, ax = plt.subplots(ncols=10, nrows=10, figsize=(8, 8), sharex=True, sharey=True) # ncols为10列, nrows=10行;画布大
# 小8*8;共享x轴的刻度,共享y轴的刻度(原来是每个小格有一套x轴和y轴,现在是整体只有一个x轴和y轴
for r in range(10):
for c in range(10):
ax[r, c].imshow(images[10*r+c].reshape(20, 20).T, cmap='gray_r') # 将随机选中的X由400reshape成20*20的格式,才是图片,再.T转置才是我们
# 能看懂的图片; cmap='gray_r'是设置颜色
plt.xticks([]) # 然后再去掉横坐标值
plt.yticks([]) # 然后再去掉纵坐标值
plt.show()
plot_100_image(raw_X)
输出显示结果:

本次就不用for循环来进行梯度下降法了,(也可以用,不过太慢了,而且之前也学过),这次用个新方法,用scipy库来自动优化求解,scipy.optimize.minimize中的几个重要参数介绍如下:

矩阵相乘的一些易混淆的知识:

损失函数
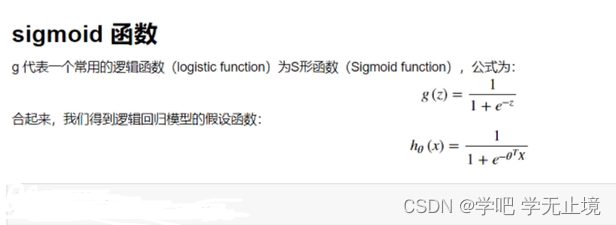
# 损失函数
def sigmoid(z):
return 1 / (1+np.exp(-z))
代价函数:

# 实现逻辑回归的代价函数,两个部分,-y(log(hx)和-(1-y)log(1-hx)
def costFunction(theta, X, y, lamda):
A = sigmoid(X@theta)
first = y*np.log(A)
second = (1-y) * np.log(1-A)
reg = theta[1:] @ theta[1:] * (lamda / (2*len(X))) # 因为j要>=1,所以theta[1:]是去掉列表中第一个元素(下标为0),对后面的元素
# 进行操作;两个一维theta相乘,就是对应元素相乘再相加,其实就是内积了,相当于公式中的sum符号,最后结果是个数
return -np.sum(first + second) / len(X) + reg
梯度下降函数
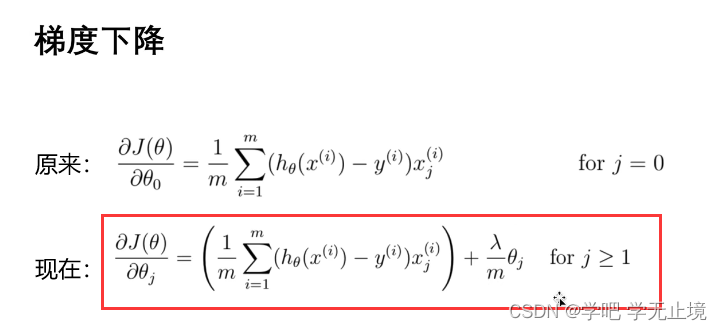
def gradient_reg(theta, X, y, lamda): # 不需要学习率和迭代次数了,之后用scipy函数会自动帮我们优化的
reg = theta[1:] * (lamda / len(X)) # 因为j要>=1,所以从第二个theta开始迭代,theta[1:]
reg = np.insert(reg, 0, values=0, axis=0) # 第一个theta虽然不参与计算,但也不能少,就默认插入0
first = (X.T @ (sigmoid(X@theta)-y)) / len(X)
return first + reg
调整X和y的维度,主要还是为了让上面costFunction和gradient_reg中涉及到y的计算不会因为数组格式出错
X = np.insert(raw_X, 0, values=1, axis=1) # 对X添加一列loc为0(在最前面),全为1的值
y = raw_y.flatten() # 把y去掉一个维度,原本是y=([[1],[2],[3]...]).T的5000行1列的的样式,现在变成了y=([1,2,3....])的数组样式,从2维到1维
print('X.shape:', X.shape)
print('y.shape:', y.shape)
对y.shape=(5000,)的理解可以看这个——“python中reshape(100,)和reshape(100,1)有什么区别”
分类原理,从0~9共有10个特征值(分类器),依次竖着排列;
共有401个待分类样本,对每一个样本都分别计算出它与10个特征值(分类器)的相似概率;
这样一共得到一个10行,每行有401个概率值(10,401)的矩阵;
每一列的最大概率值对应的特征值(分类器),就算作该样本识别出它是哪个数。

运用scipy开始优化,迭代;
def one_vs_all(X, y, lamda, K): # for i in range(n)与for i in range(1, n)是不一样的
n = X.shape[1] # n是个数,X.shape[1]是X的列数,X.shape[0]是X的行数
theta_all = np.zeros((K, n)) # theta初始为一个K行n列的矩阵
for i in range(1, K+1):
# print('i:', i) # 遍历时候是从1到K,1 2 3..10
theta_i = np.zeros(n,) # 一维数组,由n个0组成
res = minimize(fun=costFunction, # 要优化的函数
x0=theta_i, # 参数初始值,theta_i一开始是零数组
args=(X, y == i, lamda), # 判断X是属于哪个y分类
method='TNC', # 选择‘TNC’的优化方法,好像是牛顿迭代法,具体原理不用管
jac=gradient_reg) # 梯度向量
theta_all[i-1, :] = res.x # 将结果res的x,也就是当前分类器下最优的theta;因为遍历时候是从1到10,存入时候是从1到9,所以要依次减1
return theta_all
设置lamda和K的值;
lamda = 1
K = 10
打印每一次迭代的theta;
theta_final = one_vs_all(X, y, lamda, K)
print(theta_final)
输出打印结果:
[[-2.38187334e+00 0.00000000e+00 0.00000000e+00 ... 1.30433279e-03
-7.29580949e-10 0.00000000e+00]
[-3.18303389e+00 0.00000000e+00 0.00000000e+00 ... 4.46340729e-03
-5.08870029e-04 0.00000000e+00]
[-4.79638233e+00 0.00000000e+00 0.00000000e+00 ... -2.87468695e-05
-2.47395863e-07 0.00000000e+00]
...
[-7.98700752e+00 0.00000000e+00 0.00000000e+00 ... -8.94576566e-05
7.21256372e-06 0.00000000e+00]
[-4.57358931e+00 0.00000000e+00 0.00000000e+00 ... -1.33390955e-03
9.96868542e-05 0.00000000e+00]
[-5.40542751e+00 0.00000000e+00 0.00000000e+00 ... -1.16613537e-04
7.88124085e-06 0.00000000e+00]]
theta_final.shape: (10, 401)
把最优的theta带回目标函数
def predict(X, theta_final):
h = sigmoid(X@theta_final.T) # 把最优的theta带回目标函数,(5000,401)@(10,401).T=> (5000,10),得到5000行10列的矩阵,选择每行
# 中最大的值,对应的分类就是他的预测值
h_argmax = np.argmax(h, axis=1) # arg是np中的比较函数,max是选大的意思;axis=0是行,axis=1就是将对同一行的每一列去比较,哪一个比较
# 大我们就将它的索引返回回来,比如第一个位置的结果最大,就返回它的索引,但结果是0,所以要对返回的索引加1
return h_argmax + 1
求准确率
y_pred = predict(X, theta_final)
acc = np.mean(y_pred == y) # 计算准确率accuracy; 求预测值y_pred等于真实值y的个数,再求平均值
print('acc:', acc)
输出的准确率挺高的:
acc: 0.9446
参考文献:
[1] https://www.bilibili.com/video/BV1mt411p7kG?p=1