顾名思义,分类是将事物“分类”为子类别的任务。但是,通过机器!如果这听起来并不多,想象一下您的计算机能够区分您和陌生人。在土豆和西红柿之间。介于 A 级和 F 级之间。现在,这听起来很有趣。在机器学习和统计中,分类是根据包含观察的训练数据集及其类别成员资格来识别新观察属于一组类别(子群体)中的哪一个的问题。
分类类型
分类分为两种:
- 二元分类:当我们必须将给定数据分类为 2 个不同的类时。示例——根据一个人的特定健康状况,我们必须确定该人是否患有某种疾病。
- 多类分类:类的数量超过2。例如——根据不同种类的花的数据,我们必须确定我们的观察属于哪个种类。
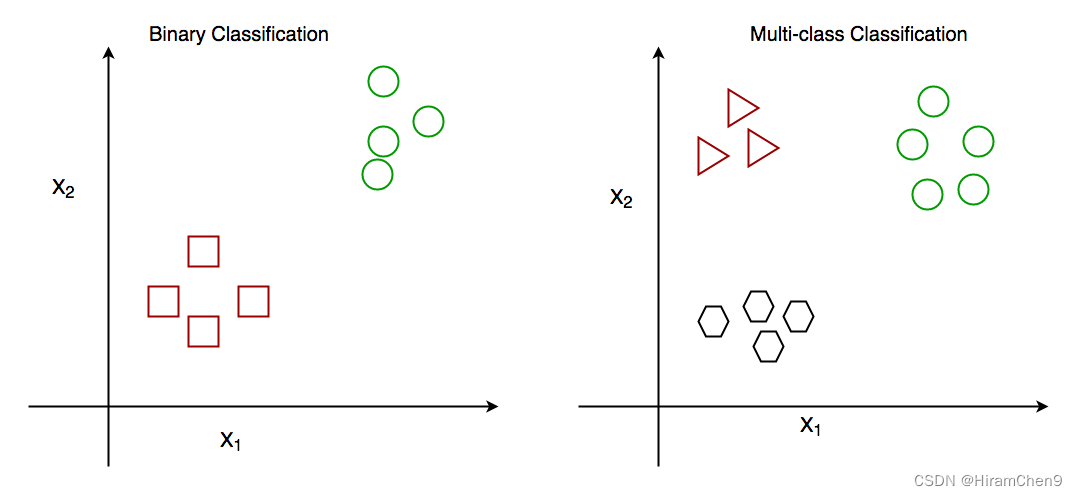
图:二元和多类分类。这里 x1 和 x2 是预测类的变量。
分类是如何工作的?
假设我们必须根据称为特征的 3 个变量来预测给定患者是否患有某种疾病。
这意味着有两种可能的结果:
- 患者患有上述疾病。基本上,结果标记为“是”或“真”。
- 患者无病。标有“否”或“假”的结果。
这是一个二元分类问题。
我们有一组称为训练数据集的观察结果,其中包含具有实际分类结果的样本数据。我们在这个数据集上训练了一个模型,称为分类器,并使用该模型来预测某个患者是否会患病。
因此,结果现在取决于:
- 这些功能如何“映射”到结果
- 我们数据集的质量。我所说的质量是指统计和数学的质量。
- 我们的分类器在多大程度上概括了特征和结果之间的这种关系。
- x1 和 x2 的值。
以下是分类任务的通用框图。
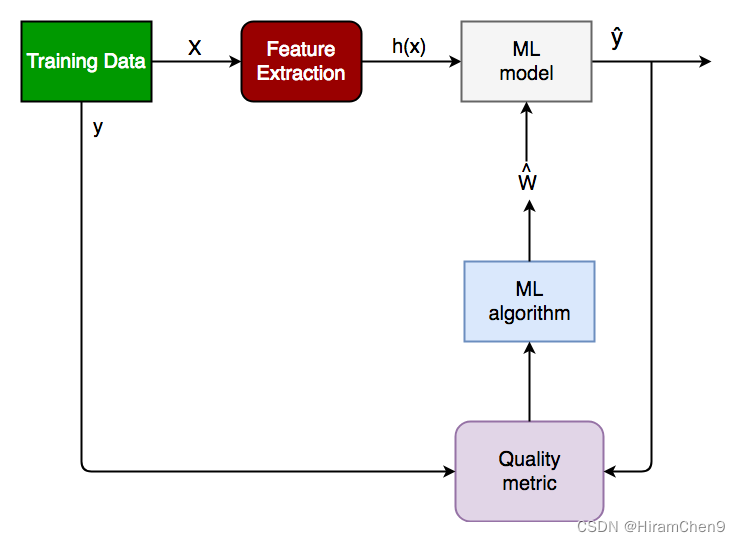
广义分类框图
- X:预分类数据,N*M矩阵形式。N 是编号。的观察和 M 是特征的数量
- y:一个 Nd 向量,对应于 N 个观测值中的每一个的预测类别。
- 特征提取:使用一系列变换从输入 X 中提取有价值的信息。
- ML 模型:我们将训练的“分类器”。
- y’:分类器预测的标签。
- 质量指标:用于衡量模型性能的指标。
- ML 算法:用于更新权重 w’ 的算法,它更新模型并迭代地“学习”。
分类器的类型(算法)
有各种类型的分类器。他们之中有一些是 :
- 线性分类器:逻辑回归
- 基于树的分类器:决策树分类器
- 支持向量机
- 人工神经网络
- 贝叶斯回归
- 高斯朴素贝叶斯分类器
- 随机梯度下降 (SGD) 分类器
- 集成方法:随机森林、AdaBoost、Bagging 分类器、投票分类器、ExtraTrees 分类器
这些方法的详细描述超出了一篇文章!
分类的实际应用
- 谷歌的自动驾驶汽车使用支持深度学习的分类技术,使其能够检测和分类障碍物。
- 垃圾邮件过滤是分类技术最广泛和公认的用途之一。
- 检测健康问题、面部识别、语音识别、物体检测、情感分析都以分类为核心。
代码:
# Python program to perform classification on Iris dataset
# Run this program on your local Python interpreter
# provided you have installed the required libraries
# Importing the required libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import datasets
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
# import the iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# splitting X and y into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1)
# GAUSSIAN NAIVE BAYES
gnb = GaussianNB()
# train the model
gnb.fit(X_train, y_train)
# make predcitions
gnb_pred = gnb.predict(X_test)
# print the accuracy
print("Accuracy of Gaussian Naive Bayes: ", accuracy_score(y_test, gnb_pred))
# DECISION TREE CLASSIFIER
dt = DecisionTreeClassifier(random_state=0)
# train the model
dt.fit(X_train, y_train)
# make predcitions
dt_pred = dt.predict(X_test)
# print the accuracy
print("Accuracy of Decision Tree Classifier: ", accuracy_score(y_test, dt_pred))
# SUPPORT VECTOR MACHINE
svm_clf = svm.SVC(kernel='linear') # Linear Kernel
# train the model
svm_clf.fit(X_train, y_train)
# make predcitions
svm_clf_pred = svm_clf.predict(X_test)
# print the accuracy
print("Accuracy of Support Vector Machine: ",
accuracy_score(y_test, svm_clf_pred))