

第一次看到神经隐式表达这个概念就是通过这篇文章,NICE-SLAM这个名称不仅看着很nice,实际的效果也很nice,最近精读了一下这篇文章,在这里和大家分享一下。
总体介绍
现有基于NeRF方法的缺陷:
- 场景重建过于平滑(NeRF使用MLP倾向于学习低频数据,从而容易忽略高频信息)
- 难以应用到大型场景(MLP网络在不断接收新的数据进行训练,面临着遗忘的问题)
主要原因:NeRF原文中只使用一个MLP,并没有针对位置做一些处理,这对于看重追踪和定位的SLAM来说就不太行了。
主要思想:提出一个实时RGB-D稠密SLAM系统 NICE-SLAM,通过引入基于特征网格的分层场景表达(hierarchical scene representation)嵌入多层位置信息,并使用预训练几何先验实现对大尺度室内场景的重建。相较于最近的NeRF-Based SLAM系统,本文方法尺度可扩展,而且更加高效鲁棒,在各个数据集上都展现出较好的效果。
相关工作:NICE-SLAM的前身是iMAP,他继承了iMAP的整体框架,iMAP的整个系统分为追踪线程tracking process和建图线程mapping process,在追踪的时候输入的RGB-D经过NeRF的神经网络获得位姿,通过位姿选择关键帧,关键帧会用于联合优化获得准确的相机位姿,有了准确位姿之后就可以用NeRF建图了。

iMAP的缺陷在于他只有一个MLP,难以预测复杂的几何或者大型的场景,且重建效果一般,有空洞,追踪也不鲁棒。NICE-SLAM在此基础上把单个MLP改为多个MLP,并且引入了多层特征网格,提升了系统性能。
具体方法
pipeline:
首先整个pipeline的输入是RGB-D数据,输出是相机位姿和一个用多层特征网格表示的场景。
从右往左看,蓝色和黄色框可以看作是一个基于NeRF的生成器,输入相机位姿,渲染出RGB和深度图。
从左往右看,输入RGB-D数据流和刚才生成的RGB-D数据在绿色区域进行对比去,求重建损失。深度图计算出Depth Loss深度误差,RGB图计算出Photometric Loss光度误差。整个系统要做的工作是最小化这个Loss。
作者在图中用了一个很大的积分号表示用了可微渲染操作,这样一来Loss就可以反向传播,用这个Loss去更新基于NeRF的多层特征网格(也就是建图),用Loss对相机位姿进行优化和更新就是追踪,这样就实现了SLAM。
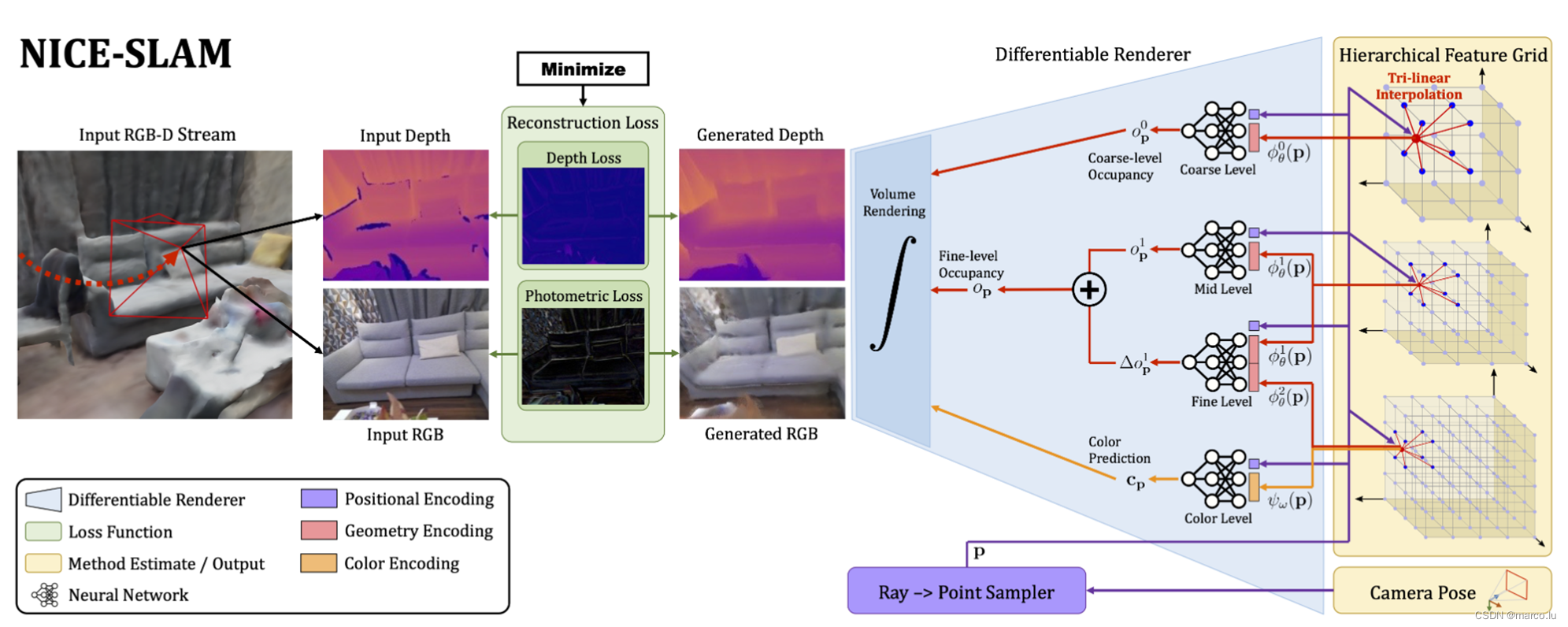
多层场景表达:
NICE-SLAM一共用了四层MLP,从上到下依次是coarse level、mid level、fine level、color level,上边三层特征网格的分辨率依次提高(fine-16cm\mid-32cm\coarse-2m),用来预测occupancy probability,相当于NeRF中的volume density(体密度、几何信息),通过红色箭头传递到左边的可微渲染器,最下边的color预测颜色信息,黄色箭头传入可微渲染器,同时这几个MLP并不是简单的在不同尺度上堆叠起来,都有各自的功能,通过一些组合来发挥作用。
Fine level同时读入mid和fine的特征,输出一个偏置offset,也就是图中的,他和mid level的输出求和送入渲染器,这两个level用的MLP是预训练的解码器都固定了参数,不会被loss更新,在优化过程中只优化特征网格,这样有助有稳定的优化和学习连续的几何特征。
Color level的参数是可学习的,这就面临着一个遗忘的问题,它储存的场景只能局部连续,也就是说在SLAM的过程中他更倾向于学习后来的数据,前边的场景表达随着参数更新被遗忘了。
前三个MLP都是在CovONet上进行训练的,它包含了一个CNN的编码器和一个MLP的解码器,训练完之后只取MLP解码器来用,MLP的结构都是五个包含32个神经元的全连接层,用的位置编码都是可学习的高斯位置编码。
这个可微渲染器和NeRF一样,给定相机外参,计算视线方向,根据不同分辨率在视线上进行采样,NICE-SLAM还会在深度值附近再均匀地多采样几个点。
Mapping&Tracking:

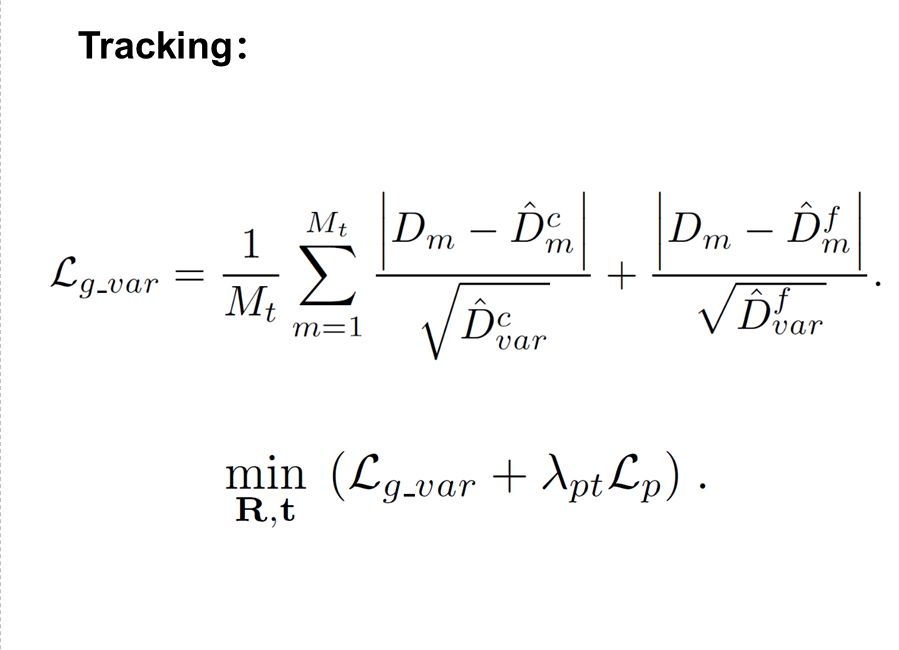
Mapping:第一个公式求深度Dm和预测深度之间的L1 LOSS,M是采样点个数,对所有采样点深度L1 LOSS求和,这个公式分别用在c&f level(这个是geometric loss);第二个公式是光度误差,通过计算M个采样点的RGB值和L1误差求和;把这几个loss求和,在光度误差前加一个权重,更新场景表达,让loss最小化。
NICE-SLAM的整个系统分为三个线程,第一个是coarse level的建图;第二个是Mid和fine的几何优化,在这个线程里首先用fine的几何误差优化mid的特征,然后再用它共同优化mid和fine,最后用bundle adjustment联合优化所有特征,这样多阶段的优化策略在分辨率高的时候更容易收敛,因为fine level的优化可以依赖已经优化过一次的mid level的特征网格。
第三个线程是追踪 Camera Tracking: 这个loss和mapping里求几何误差的公式很像,它除了计算深度之间的L1误差还在分母上加了方差,这个方差是在渲染深度的时候求出来的,加在这里用来控制不确定的深度值的权重,当一个采样点m处的方差大的时候,表示这一点的深度置信度很低,用这种方式避免刚开始特征网络表达能力弱的时候对优化造成的影响。
由于Coarse level能够在一定程度上预测几何信息,所以当相机进入到陌生环境的时候或者面对丢帧、相机快速运动的时候也能保证不追丢。这里有一个值得注意的地方,NICE-SLAM对动态环境具有一定的鲁棒性,当求出来某一点的深度或者颜色误差比较大的时候,就认为这个点是动态点会被剃除,实际在运行的时候,这个值取的是当前帧所有采样点loss中值的十倍,如何在动态环境中联合优化相机参数和场景表达,这也是一个有意思的工作,作者在这并没深入。
实验结果
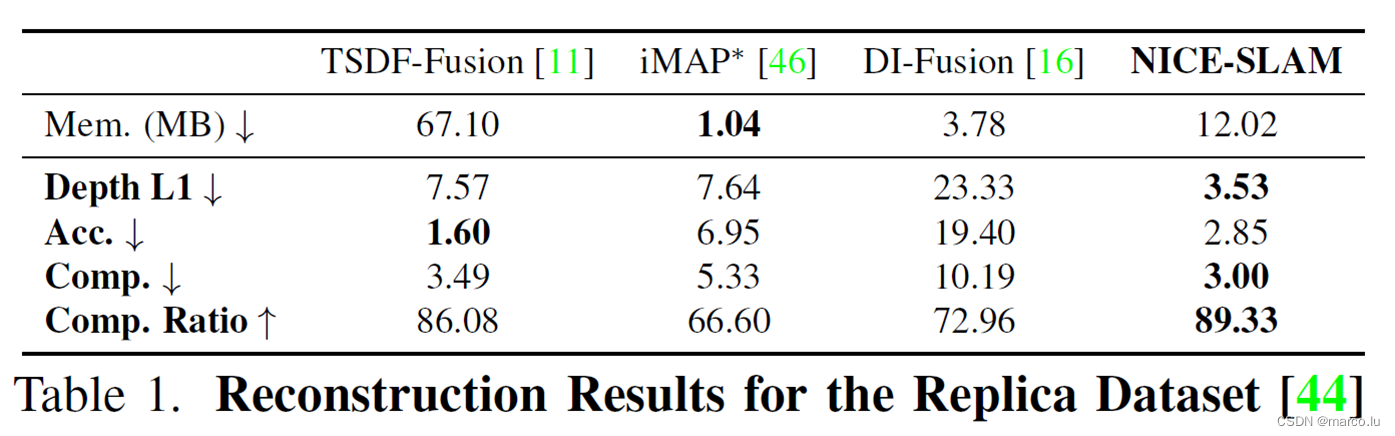
定性结果-Replica数据集

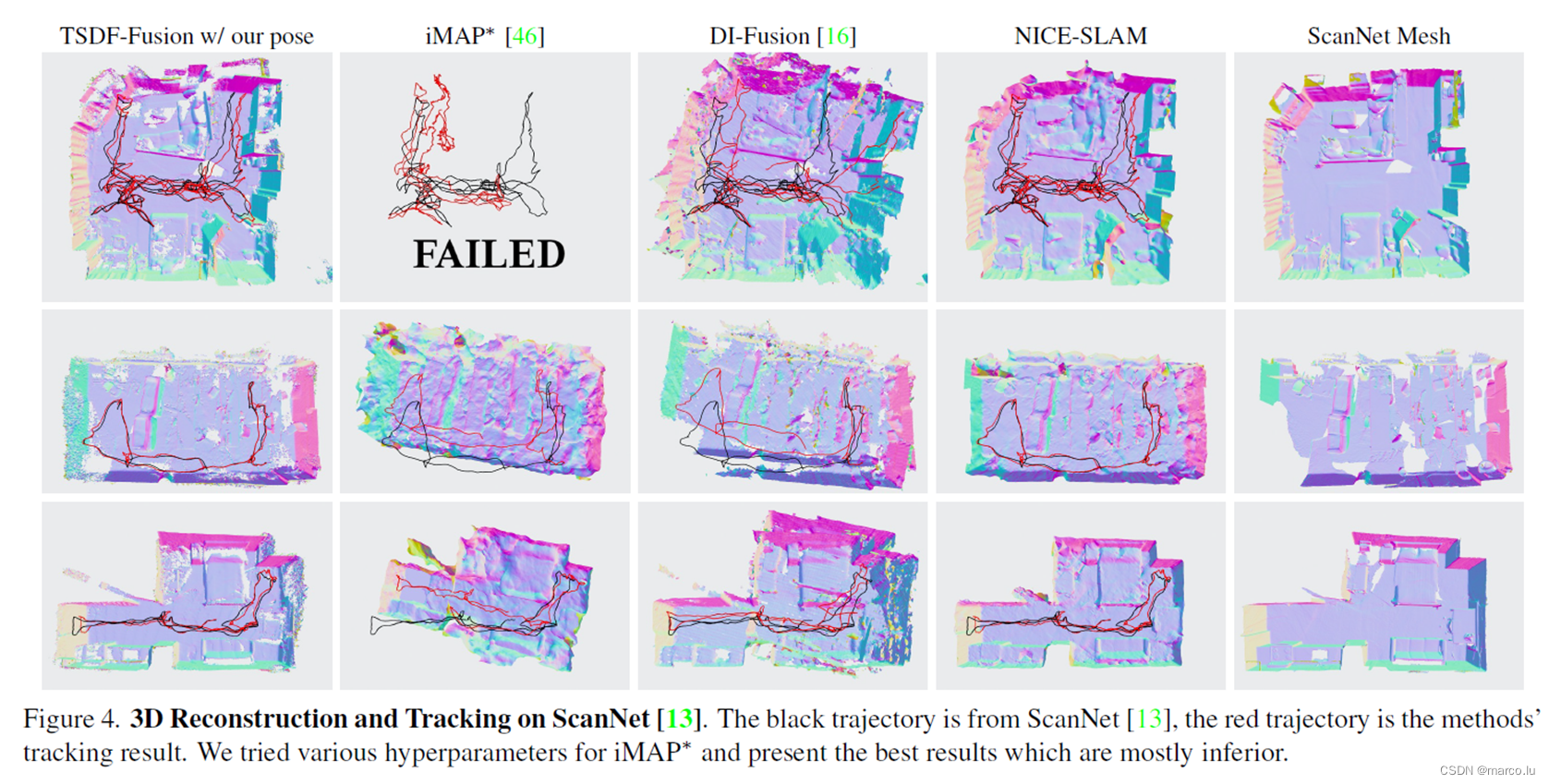
定性结果-ScanNet数据集
定性结果-多房间
 定性结果-动态场景
定性结果-动态场景

定性结果-预测能力

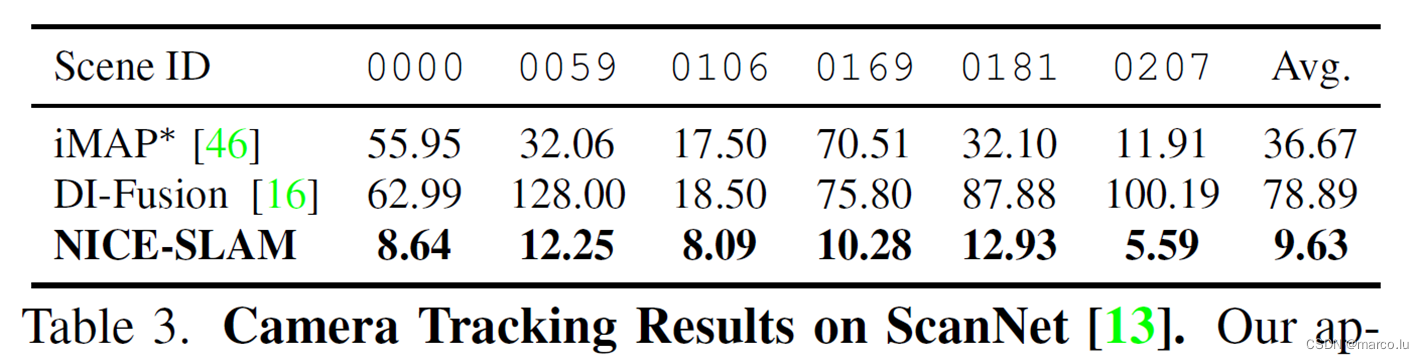
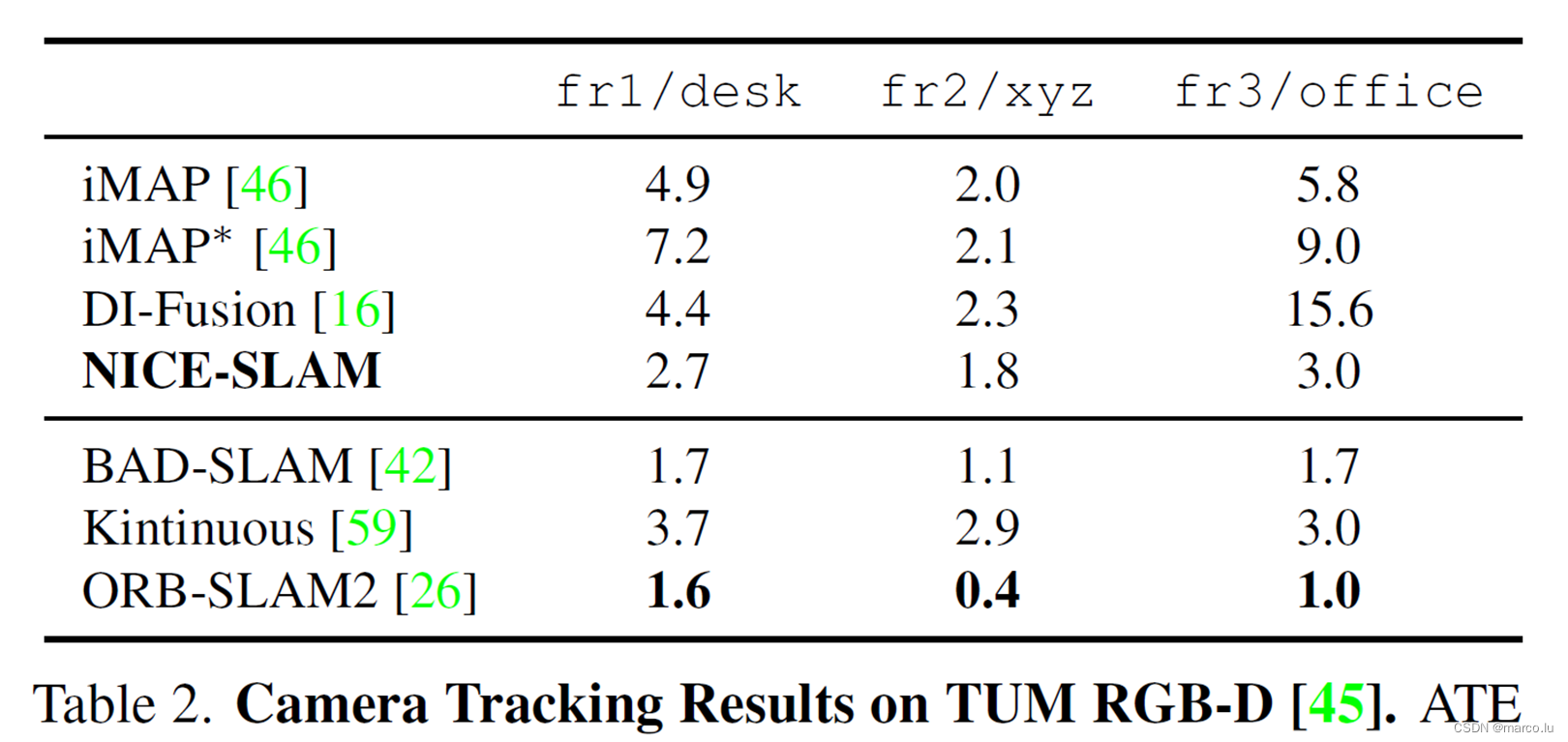
定量结果
总结与展望
-
本文提出了NICE-SLAM,一个RGB-D稠密视觉SLAM方法,结合了神经隐式表达和多层特征网格场景表达。
-
相较于用一个传统的巨大的MLP表示场景,我们采用的小MLP加上多分辨率特征网格的表达方法,使得地图可以局部更新,不仅保证了精细的地图细节和高质量的渲染精度,还获得了更快的速度和更小的计算消耗。
-
除此之外,NICE SLAM还能够填补小的空洞并且外推到没见过的区域,这保证了稳定的相机追踪。
本文方法的缺陷:
1 NICE-SLAM的预测能力受限于Coarse Level的尺度;
2 没有回环检测;
3 基于学习的SLAM方法和传统SLAM方法仍然有不小的差距。