Abstract
- 多层感知器(MLP)已被证明是有效的场景编码器,当与输入的高维映射相结合时,通常被称为位置编码。然而,具有宽频谱的场景仍然是一个挑战:选择高频进行位置编码会在低结构区域引入噪声,而低频会导致详细区域的拟合不佳。为了解决这个问题,我们提出了一种渐进的位置编码,将分层 MLP 结构暴露给频率编码的增量集。我们的模型精确地重建了宽频段的场景,并在没有显式的每级监督的情况下,在渐进的细节水平上学习场景表示。该体系结构是模块化的:每一层编码一个连续的隐式表示,可以分别用于其各自的分辨率,这意味着更小的网络用于更粗略的重建。在几个 2D 和 3D 数据集上的实验表明,与基线相比,重建精度、表示能力和训练速度都有所提高。
1. Introduction
-
神经隐式函数作为二维图像和三维形状表示的替代方法越来越受欢迎。使用一个简单的 MLP 编码器,这些网络在空间坐标和感兴趣的数量(如颜色、占用或SDF值)之间近似一个函数映射。它们已被证明在拟合自然图像[39,23]和3D形状[24,30,5]方面非常有效,并已应用于各种计算机视觉任务,包括新视图合成[28,25]和生成形状建模[6]。
-
然而,作为简单的MLP编码器,神经隐式函数存在频谱偏差[31,3],这使得它们无法学习信号中的高频细节。然而,将输入投影到包含高频分量的流形上,可以减小频谱偏置。最近的工作[25,46]已经通过实验证明了这一点,通过一组正弦函数(位置编码)映射输入。在并行的方法中,[38]使用周期性激活函数代替relu使mlp学习高频内容。[39]提出了一种基于傅里叶特征[32]的改进位置编码,并表明人们基本上可以通过位置编码中的频率来调整MLP可以学习的频率范围。然而,具有这些编码的mlp很难拟合具有宽频谱的信号:编码中的高频率可以拟合信号中的小细节,但在更平滑的区域引入噪声。为了改进这一点,[12]提出了一种基于空间掩码的训练方案,逐步将频率编码引入网络。在获得令人信服的结果的同时,该方法需要空间掩模,这不能很好地扩展并降低了训练速度,并且其展开频率的训练方案是不可微的,需要手动超参数调整。
-
我们展示了一个连续函数可以学习以一种渐进的方式在宽频率范围内重建信号(见图1):我们将表示划分为分层级别,每个级别接收位置编码的子集,因此与较高的层相比,较低的层处理较低的频率集。我们最终的重建是所有中间层次的简单组合。这将产生一个端到端可训练的模型,并且我们发现我们的架构自然地诱导较低层学习更粗糙的重建,而较高层则专注于向场景添加细节(参见图2),而没有显式的逐级监督。我们的方法提供了渐进的细节水平,同时产生同等或更好的重建质量基线。此外,我们的架构是模块化的——为了得到更粗糙的表示,人们可以放弃更高级别的mlp,只使用一小部分参数重建场景。总的来说,我们的方法提供:
- 一种基于层次隐式函数的多尺度表示,采用渐进式位置编码,提供递增级的细节。
- 提高了重建质量,特别是对于宽频谱场景。
- 端到端可训练模型,没有每个级别的监督。
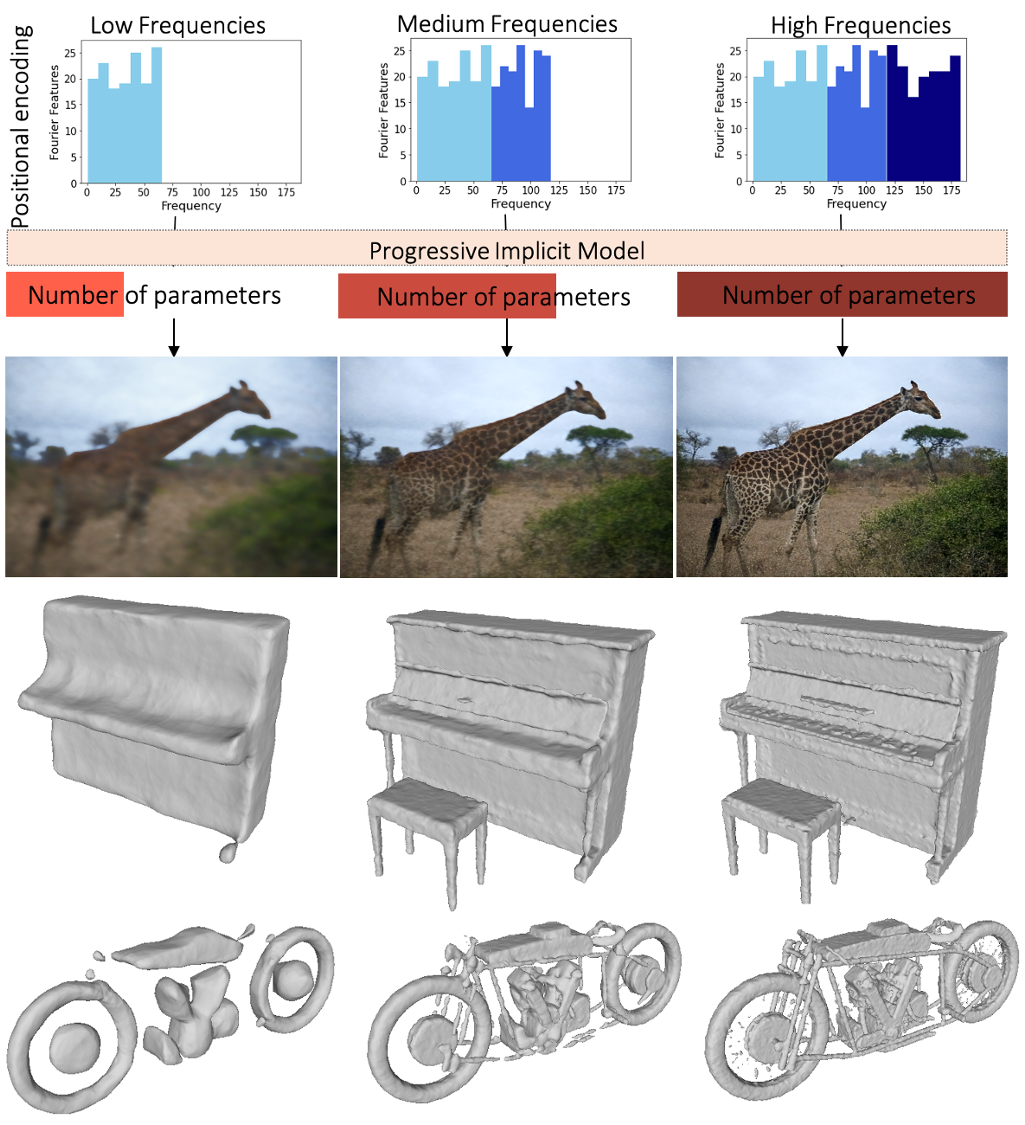
[图1: 方法概述。输入坐标由增量频率编码集(顶行)投影,并由分层MLP结构进行处理,该结构在逐级细化的情况下生成2D(第2行)和3D(第3行和第4行)重建。]

[图2: 2D重建示例。左:网络预测的图像残差右:结合基像c和各自图像残差得到的逐级重构水平。]
2. Related Work
神经内隐表示。作为占用[24]和SDFs[30]的新形状表示,神经隐式函数已经成为经典3D表示的流行替代品。一些工作将其用于单视图形状推断[36,22],形状分解[8]和实例感知SLAM系统[17]。它们被证明支持更大的场景表示[5,13],当组成表示局部细节的小隐式函数的体素网格时。[11]证明复合隐式函数也能提高较小形状的重建精度。最近的工作探索了它们在图像合成中作为对象特定的隐式字段[26]以及动态场景图[29]的使用。结合可微体绘制[27],神经隐式表示引起了新的视图合成方法[25]的爆炸。其他工作涉及泛化,将神经隐式表示用于从图像[45]中提取的特征或编码形状先验的潜能[37,14]。一些方法专注于提高训练和渲染速度[33,44]和表示本身:为了解决基于简单MLP的神经隐式表示的光谱偏差,提出了周期激活函数[38]和位置编码[31,39,12]。与Park et al[30]类似,我们的方法被设计为2D和3D的场景表示。我们没有使用单个MLP来表示场景,而是提出了一个小MLP的分层结构,在逐级的细节层次上组成场景。类似于Hertz等[12],我们使用傅里叶特征作为位置编码,但不是空间频率掩码,我们在这些编码的子集上对分层结构中的每个mlp进行条件处理。
多尺度神经隐式表征。最近的一些方法提出在神经隐式表示中添加层次结构或多尺度结构;它们可以分为使用空间划分形式的和使用基于频率的方法的。在空间划分方法中,大多数方法都利用八叉树,并以更有效的渲染或训练时间为主要目标[44,23,40]。Chen等人[7]提出的方法生成多尺度表示:特征编码器生成潜在代码网格的层次结构,这些网格在较低维度流形中以不同分辨率表示场景。为了在特定分辨率下重建场景,基于连续坐标样本对潜在网格进行插值,并使用神经隐式函数进行解码。基于频率分解的方法在连续函数空间中增加了多尺度结构:Wang等。[43]使用两个SIREN模型[38]的组合,将三维形状表示为隐式位移场:平滑的基面沿着基面的法线进行预测位移细化。Lindell等人[21]提出了一种基于乘法滤波网络(MFN)[10]的多尺度表示,[10]是应用于输入的傅里叶或Gabor小波函数的简单线性组合。为了在多个分辨率下重建,在MFN的不同深度添加线性层,以生成中间输出。这些输出,在监督下,生成越来越详细的重建。类似于Wang等人[43]和Lindell等人[21],我们在连续函数空间中建模我们的多尺度表示。然而,我们的架构是基于具有ReLU激活的mlp,允许多个细节级别,并且我们通过输入的傅里叶特征编码中的频率约束每个级别的表示。与Lindell等[21]相反,我们的中间层次构成了最终的重建,在训练期间不需要监督。
3. Preliminaries
神经隐式表示使用神经网络参数化在连续空间中编码信号。
它们通常被称为基于坐标的网络,定义为一个函数映射 f: x→V, x∈R1,2,3; V是兴趣的数量,如颜色或占用率。在3D中,曲面被建模为连续函数 f: f(x) = 0 的水平集。通过设计,该表示法一次预测信号域中的一个点,通过查询该表示法在对应的坐标集{x1…xN}。
位置编码是在自然语言处理[41]中首次引入的,它将有关单词标记的相对位置的信息注入到Transformer模型中。在神经隐式表示的背景下,位置编码是指输入(空间坐标)到高维空间P的投影:I R1,2,3→RN [25]。已经提出了几个函数映射,包括简单正弦映射来拟合神经辐射场[25]和重建三维蛋白质结构[46],非轴向傅立叶基函数:’ FourierFeatures '[39]和基于多尺度b样条的位置编码[42]。傅里叶特征已经成为快速核方法近似[18]的流行框架。该近似由Rahimi等人[32]首先提出,它基于Bochner定理[4],该定理表明任何连续移不变核都是正有界测度(谱测度)的傅里叶变换。Rahimi等人[32]提出的方法通过其蒙特卡罗估计,使用来自这个光谱测量的样本,近似于这样一个连续核:Fourier特征[18]。Tancik等人[39]将这种方法与应用于神经隐式函数输入的频率映射联系起来,并提出傅立叶特征作为位置编码的一种改进形式:一组傅立叶基F: {cos(ωix + bi)…cos(ωnx + bn},其中ω和b从参数分布中采样(例如N(µ= 0,σ))。作为一种位置编码,傅里叶特征将输入坐标映射到高维流形,如P: x∈ R1,2,3→F(x)∈Rn。我们选择一个傅立叶特征映射作为我们的渐进式隐式表示的位置编码,并在本文的其余部分中将其称为傅立叶特征(FF)。
4. Method
4.1. Progressive Fourier Feature encoding
我们将重建场景 S 的任务表述为一个基本分量 c 和一组残差 R 1 … L R_{1…L} R1…L 的组合:
S ( x ) = c + ∑ l = 1 L w l R l ( f l ( x ) ) , (1) S(x)=c+\sum_{l=1}^{L}w_lR_l(f_l(x)),\tag{1} S(x)=c+l=1∑LwlRl(fl(x)),(1)
其中 x 是坐标向量,每个残差 R l R_l Rl 由 MLP 参数化。 R l R_l Rl 对最终表示的贡献由 w l w_l wl 控制,c 是根据重构任务域确定的常数集。 R l R_l Rl 将傅里叶特征映射 F 的子集 f l ( x ) f_l(x) fl(x) 作为输入,F 的频率集合从高斯分布 F ∼ N ( 0 , σ ) F\sim N(0,σ) F∼N(0,σ) 采样。
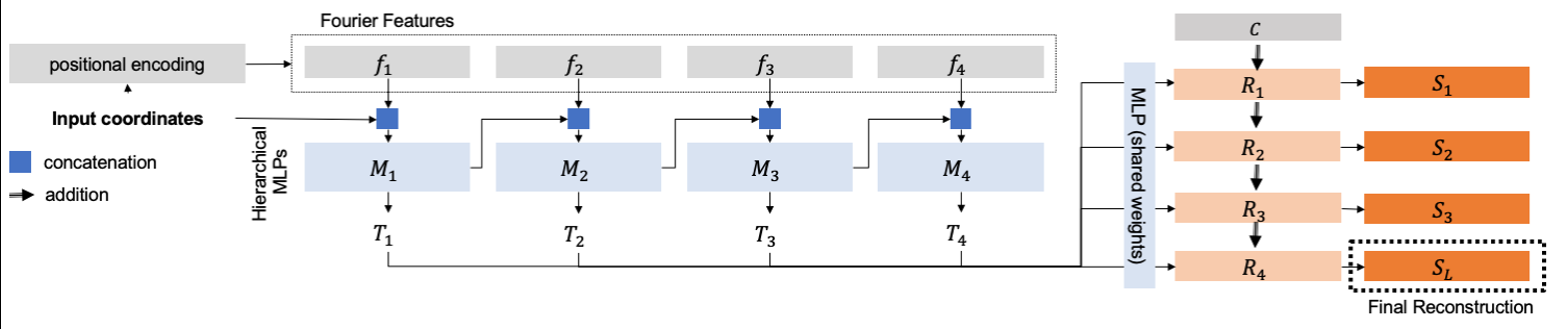
[图3:4个详细级别的模型体系结构。]
4.2. Architecture
我们的体系结构是由多个堆叠的小型 MLPs M 1 … L M_{1…L} M1…L,其中每个 MLP 接收作为输入的一组 FF 映射 f l ( x ) f_l(x) fl(x) 和前一个水平的输出(水平条件作用)。第一层接收作为输入的 f 1 ( x ) f_1(x) f1(x) 和原始坐标 x。每层的输出是一个特征张量 T l T_l Tl:
M l : f l ( x ) , T l − 1 → T l , l > 0 M l : f l ( x ) , x → T l , l = 0 (2) M_l:f_l(x),T_{l-1}\rightarrow T_l,l>0\\ M_l:f_l(x),x\rightarrow T_l,l=0\tag{2} Ml:fl(x),Tl−1→Tl,l>0Ml:fl(x),x→Tl,l=0(2)
然后,每个特征张量 T l T_l Tl 被另一个 MLP 映射到残差 R l R_l Rl,该 MLP 在每一级共享权重,并充当特征到域的映射。最后,根据公式1将网络输出组成最终重构。在每一层使用中间特征表示 T l T_l Tl 允许在级别条件反射期间将更有表现力的特征表示传递到下一层。我们尝试了每层域映射,但没有发现使用共享权重的单个 MLP 有明显的好处。虽然在训练前选择了层数 L 以及频率的数量和范围 F,但我们只对最终的重构 S 应用了一个损失,将如何将场景表示分解为递进的级别留给了网络:因此分解为细节级别的过程是不受监督的。直观地说,我们的体系结构通过限制每个特定于级别的 MLP 可以访问的频率范围来促进分解为逐步的细节级别。我们在消融研究中表明,在之前的 M l − 1 M_{l−1} Ml−1 水平上调节 M l M_l Ml 可获得更高的重建精度。每层模块化我们的体系结构设计允许在测试时独立使用每层重构。对于中等细节水平的重建 S l = 2 , M L P s M 3 … L S_{l=2}, MLPs M_{3…L} Sl=2,MLPsM3…L 可以去掉,重构计算为 S l = 2 ( x ) = ∑ l = 0 l = 2 ω l R l ( f l ( x ) ) S_{l=2}(x)=\sum_{l=0}^{l=2} ω_lR_l(f_l(x)) Sl=2(x)=∑l=0l=2ωlRl(fl(x))。我们的方法和体系结构的概述见图1和图3。
4.3. Loss
为了训练我们的模型,我们在最终的重构 S 处应用了一个重构损失 L r L_r Lr,以及一个正则化损失 L r e g L_{reg} Lreg,它鼓励中间层次的细节 S l ’ S_{l’} Sl’ 接近 ground truth scene S g S_g Sg:
L r e g = ∑ i = 1 N L r ( S L ( x ) , S g ) (3) L_{reg}=\sum_{i=1}^{N}L_r(S_L(x),S_g)\tag{3} Lreg=i=1∑NLr(SL(x),Sg)(3)
我们的最终损失定义为 L r + ω L r e g L_r + ω L_{reg} Lr+ωLreg,我们发现 ω = 0.01 的值对我们的实验很有效。我们对 L r L_r Lr 进行了简单的 L1 和 L2 规范的实验,以及基于 VGG 特征的感知损失。基于深度网络特征的感知损失必须使用 L1 或 L2 范数[15]进行正则化。我们发现,尽管感知损失在2D回归任务中产生了稍微更令人愉悦的视觉结果,但差异不足以显著到激发引入额外的超参数。因此,在我们最后的实验中,我们使用L2范数。