文章目录
前言
今天分享的是来自2022年arXiv上的关于图神经网络防御方面的文章,这篇文章主要突出了减小秩近似的GARNET方法在异质图和大型数据集两个方面的运用。
论文链接:https://arxiv.org/pdf/2201.12741v2.pdf
一、本文贡献
首先介绍一下本文的贡献:
- 使用谱图嵌入和概率图模型来提高GNN模型的鲁棒性
- 引入图概率模型,通过最大似然估计来判别图中重要的边构建基础图G_base
- 本文所提到的降秩拓扑学习的方法具有近似线性的时间和空间复杂度,从而可以使其使用在大型数据集中
二、GARNET是什么?
那么作者为什么会提出GARNET这种方法呢?GARNET到底对于之前以前提出的方法有什么样的改进和优势。目前来看我们所知道的是图卷积算法对于图网络攻击时很容易被攻击的,表现是十分脆弱的。从攻击角度来看,为了使攻击的扰动不被注意到,设计出了高秩的攻击方法,比如图对抗攻击中比较有名的方法:目标攻击Nettack方法和非目标攻击Metattack方法。Nettack攻击的本质是改变奇异值很小的部分,那么对于这种情况,从防御来说,我们只需要把奇异值大的部分保留着,进行网络重构,使用TSVD去除噪声,就还原网络真实情况。
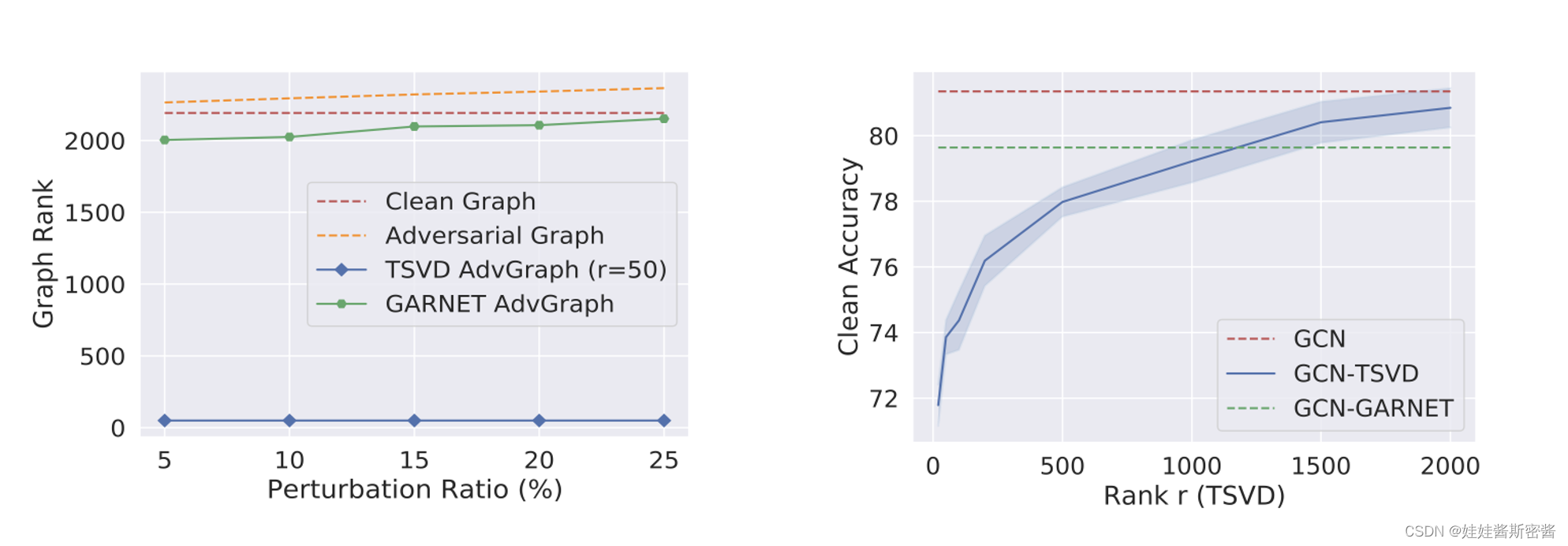
对于上面的两张图,我做简单的分析。我们可以看到左边这张图,红色虚线代表的干净图的秩在2000~2500之间;通过高秩的攻击方法生成的黄色虚线对抗图的秩是比干净图的秩高一些;通过TSVD也就是截断奇异值分解形成的蓝色实现的对抗图的秩只有50左右,很明显如此低的秩不可避免的会损害干净图中的重要结构信息,这也就相应的会影响重构图的整体质量,并且进而影响GNN的训练性能。这也体现了通过TSVD形成的对抗图的一些弊端。右边这张图说明了一个什么问题呢?我们可以看到,通过设定TSVD中不同的截断参数,随着秩的增加,蓝色实线所代表的精度越来越高,这也进一步说明了太低的秩会影响重要的信息。然而,本文提出的GARNET不管设定这样的的截断参数,其干净图的精度保持不变。下面,我就重点介绍一下GARNET方法的实现过程。
三、GARNET具体实现过程
1.三个阶段
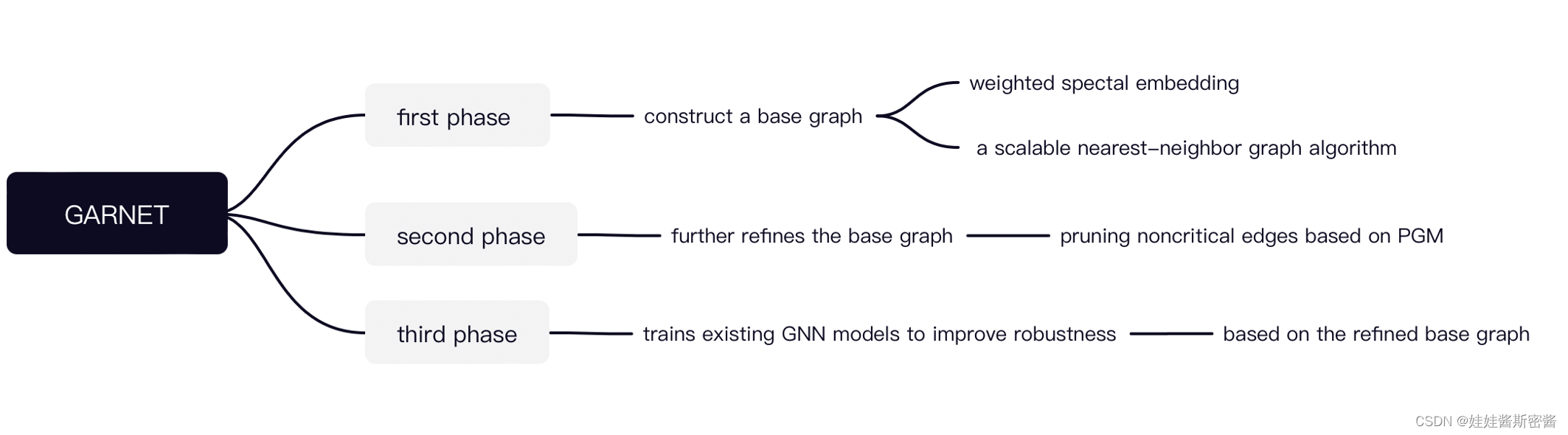
第一阶段:通过加权谱嵌入和K近邻算法构建一个基础图
第二阶段:通过概率图模型修建不重要的边进一步定义干净基础图G_base
第三阶段:在阶段二的G_base基础上训练GNN模型以此来提高鲁棒性
2.总体模型图
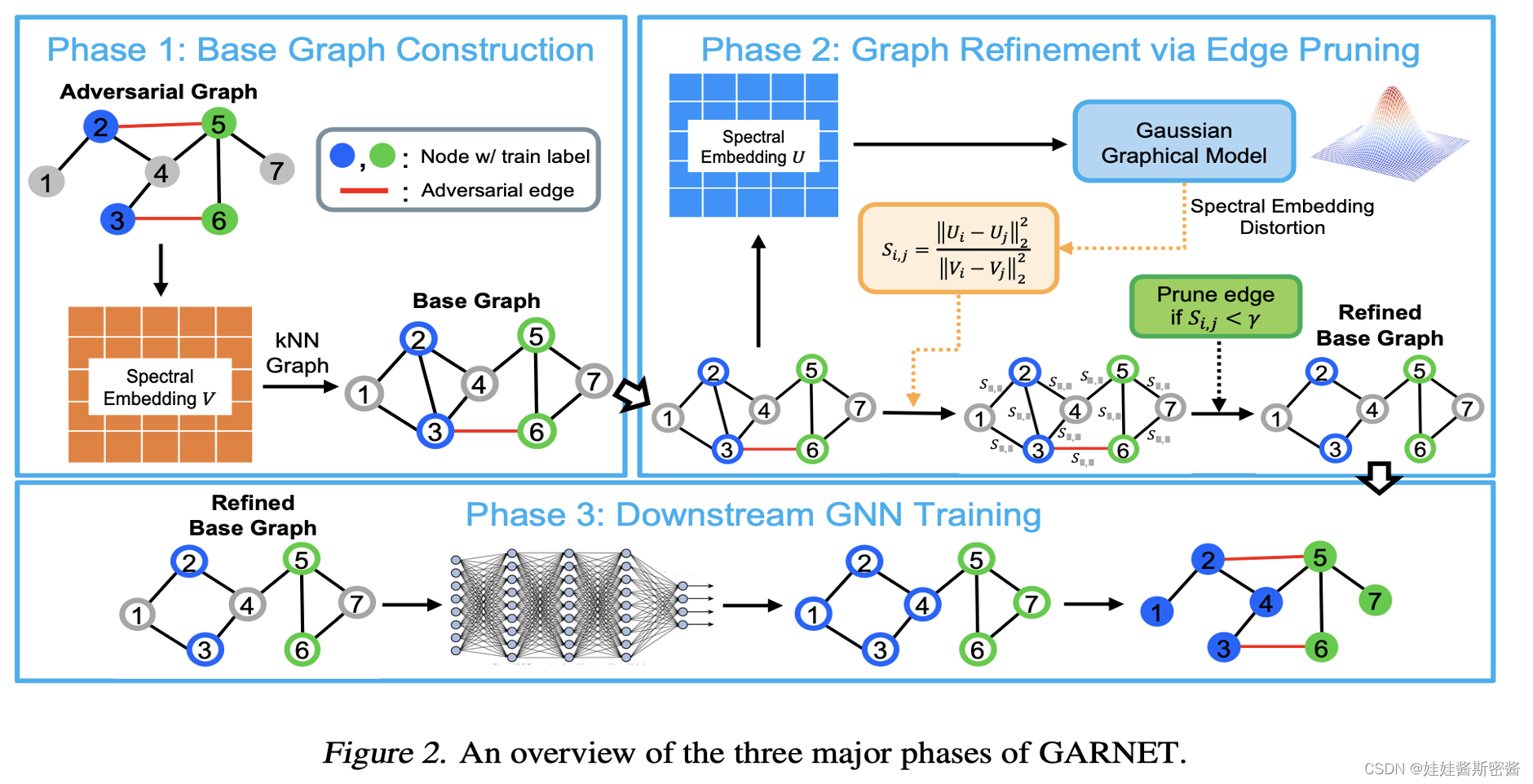
我们可以看到上面的模型图,上面也提到过了。第一阶段在给定对抗图的基础上,我们可以计算出加权谱嵌入矩阵V,再使用K近邻算法得到每个节点的相关的k个节点得到我们的基础图G_base;之后我们来到了第二阶段,在G_base的基础上计算出加权谱嵌入矩阵U,紧接着我们来到了计算谱嵌入失真s_i,j,以此来衡量边的重要性,通过比较s_i,j和我们所设定的超参γ(伽马),若s_i,j小于γ,则代表这一条边在基础图G_base中具有比较小的谱嵌入失真,那我们需要修剪这条边。为什么呢?我们想要构建出包含主导地位的奇异值和奇异向量的基础图,这些占主导地位的奇异值和奇异向量忽略了高秩的攻击影响,由此保证了面向对抗攻击的鲁棒性能;最后第三阶段,在第二阶段得到的G_base基础上进行现有的GNN模型的训练,以此来提高模型的鲁棒性。下面我将详细讲解三个阶段的实现过程。
3.构建基础图
第一部分,构建基础图,这里最重要的就是计算加权谱嵌入矩阵V,我们定义如下:

其中这里的λ是特征值,v是对应的特征向量。
我们可以把这个加权谱嵌入矩阵V看为对应的邻接矩阵A中一些主要的的奇异值和奇异向量组成的特征子空间矩阵。

论文中给出了上面这个式子的证明,这个式子描述了两个矩阵之间存在的联系。这里的V就是刚才所提到的加权谱嵌入矩阵,A尖代表的是正则化的邻接矩阵通过截断奇异值分解(TSVD)变为秩为r的矩阵。这里,关于TSVD,我想做一些相关说明,奇异值和特征值类似,奇异值在矩阵中也是从大到小排列的,并且奇异值的减小特别快,在很多情况下,前10%甚至是1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们可以用前r大的奇异值来近似描述矩阵,这同时也对应了我前面所说到的为什么要找占主导地位的奇异值和对应的奇异向量。
接下来,我们可以通过PGM(概率图模型)使用加权谱嵌入矩阵V来得到我们的底层干净图。但是,值得注意的是,想要的到V我们必须知道干净图结构的基本信息,那么这就有点矛盾了,这就有点像是先有鸡还是先有蛋这个问题了。
论文中发现了一种联系解决了这个问题,因为较大的主要的奇异值和对应的奇异向量是很难被对抗攻击所影响到的,所以我们进一步可以得到计算得到的加权谱嵌入矩阵在被攻击之后也有一定的抵抗能力。那么这进一步说明什么问题呢?这就说明了通过干净图基础上得到的加权谱嵌入矩阵和通过对抗图得到的加权谱嵌入矩阵是差不多的,所以我们可以用对抗图得到的加权谱嵌入矩阵代替干净图得到的谱嵌入矩阵。因为对抗图已知,我们可以顺理成章的得到V。
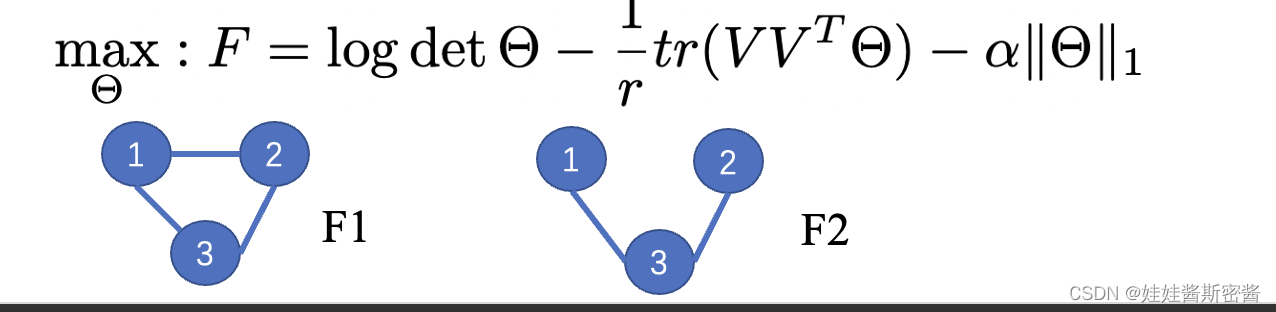
下面我将对这第三个式子做一个解释,这个地方的Θ类似于拉普拉斯矩阵,它在拉普拉斯矩阵L的基础上加上了一个常量方差值。这个式子的目的是通过最大似然估计找到最优的Θ矩阵,进而在加权谱嵌入矩阵V的基础上恢复出干净的图。通过第三个式子找到最优的Θ等价于去寻找完全图的重要的边结构。我们可以通过F是否强烈的增大或者强烈的减小,来判断包含某一条边是否重要。比如,我们想判断节点1和节点2之间的边是否重要,我们可以通过上面这个式子计算关于左边这个图中节点1和节点2有连边的F1数值,同时再计算一下关于右边这张图节点1和节点2没有连边的F2的数值。如果我们发现F1的值比F2的值大很多的话,就可以判定为节点1和节点2之间的连边是重要的;同理,如果F1的值比F2的值小很多的话,就可以判定节点1和节点2之间的连边不是重要的。如果按照这样的方法来计算边是否重要,显然花费的代价是巨大的,因为这种方法基于的是单变量,每次只能改变其中的一条边结构,想要计算一张图中所有边的信息,那我们得花费平方数量级别的时间复杂度,因为这篇论文想运用到大型图结构的数据集中,所以显然这种方法是不可取的。如果想在大型图数据集中取得效果,那么这个时间复杂度应该控制在近似线性级别的位置。这篇论文中想了一个办法,他们用基础图G_base代替了完全图,G_base很明显比完全图稀疏很多。但是尽管G_base比较稀疏,它里面也包含了恢复干净图结构的候选重要边的结构信息。
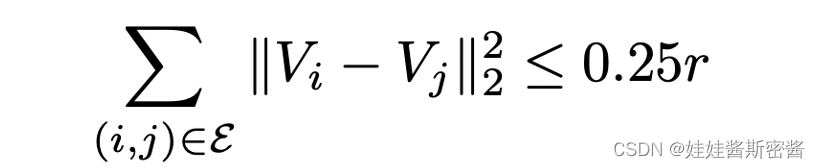
那么构建G_base我们还需要得到一个比较重要的数值,就是判断干净图中节点i和节点j之间是否有连边,这里是用到的是欧里几得距离。V_i表示的是正则化的拉普拉斯矩阵中最大的r个特征对构建出来节点i的加权谱嵌入矩阵,r表示的是相对较小的常数。如果干净图中节点i和节点j之间是存在边的,那么计算出来的欧式距离会很小。于是这就可以进一步想到我们可以通过使用K近邻算法来构建出G_base。
KNN近邻算法可以简单的描述为以下步骤:
- 计算某一个节点和所有节点的距离
- 按距离 近 -> 远 排列
- 统计前k个节点的连边情况
论文中对于k的选取在50~100之间,在这样的区间范围内达到了比较好的效果。
4.基础图修剪边

为了判断刚刚在第一阶段中所提到的F的变化情况对于边是否重要的部分,文章用梯度上升的方式来更新Θ。简单分析一下这个式子,其中 η (yita)是步长。如果F关于w_i,j的偏导数增大,那么对应的Θ_i,j的更新会减小,进一步最大似然估计出来的F会增大;反过来,如果F关于w_i,j的偏导数减小,那么对应的Θ_i,j的更新会增大,F会减小。从而进一步说明了相对应的边是否重要。所以,只要我们知道了F关于w_i,j的偏导数,那么我们就可以知道边的重要程度。
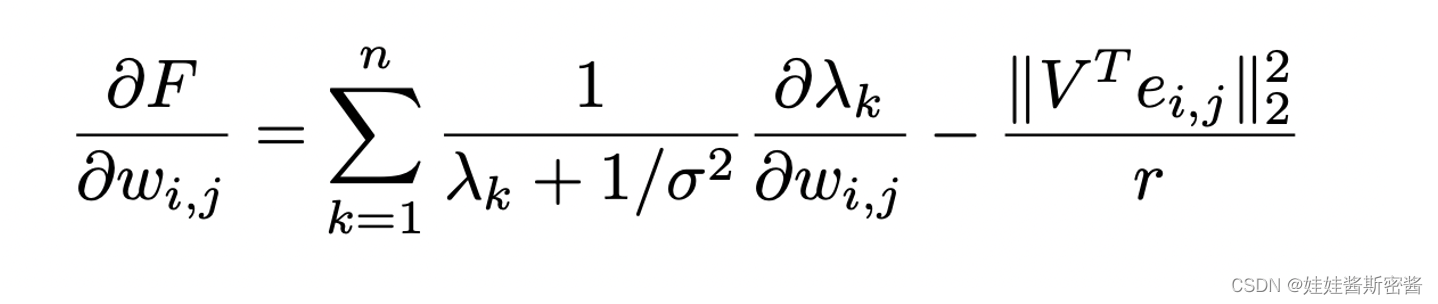
上面这个式子就是F对w_i,j求偏导的结果。其中涉及到λ_k关于w_i,j的偏导。于是论文中将谱图扰动δ(德尔塔)λ_k估计出了下面的式子:
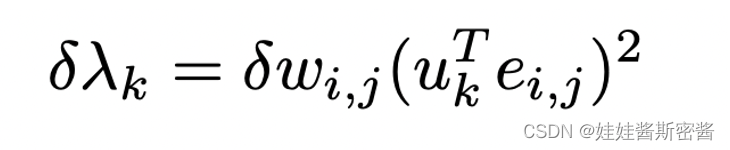
于是对这个式子求关于w_i,j的偏导数,带入上面的式子中,我们可以得到最下面的式子,由于对谱图扰动δ(德尔塔)λ_k是估计值,所以F关于w_i,j的偏导数写成了约等于:
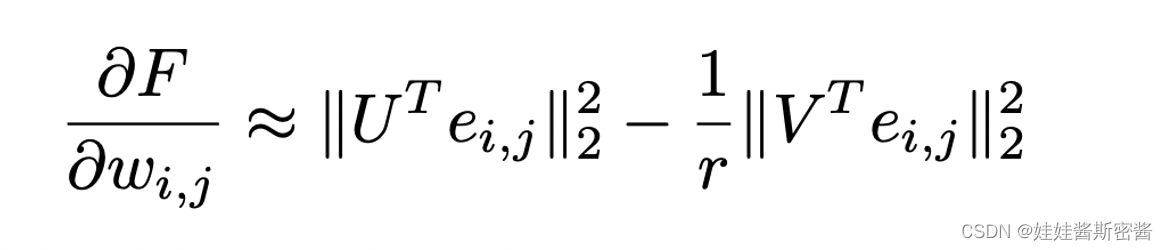
第二阶段的最后一部分是对基础图G_base的修边操作:
论文中定义了谱嵌入失真s_i,j的式子:
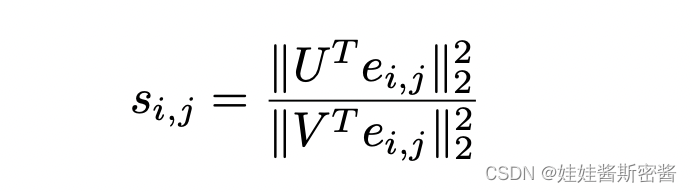
这里的U是在基础图上通过谱嵌入得到的矩阵,V是在输入的对抗图上通过谱嵌入得到的矩阵。s_i,j衡量了边的重要程度。可以设置一个超参γ(伽马)来决策边是否修剪。进而得到了最后已经修剪完成的G_base图结构。
5.GNN训练的下游任务
最后第三阶段就是在G_base的基础上训练数据集得到模型。这里分析一下各个阶段的时间复杂度:我们可以看到每个阶段的时间复杂度都处理在了接近线性的时间范围内,并且作者将GARNET方法与其他防御方法比如:TSVD和ProGNN。可以看到的是,GARNET确实是在时间上有一定优势。
三、实验部分
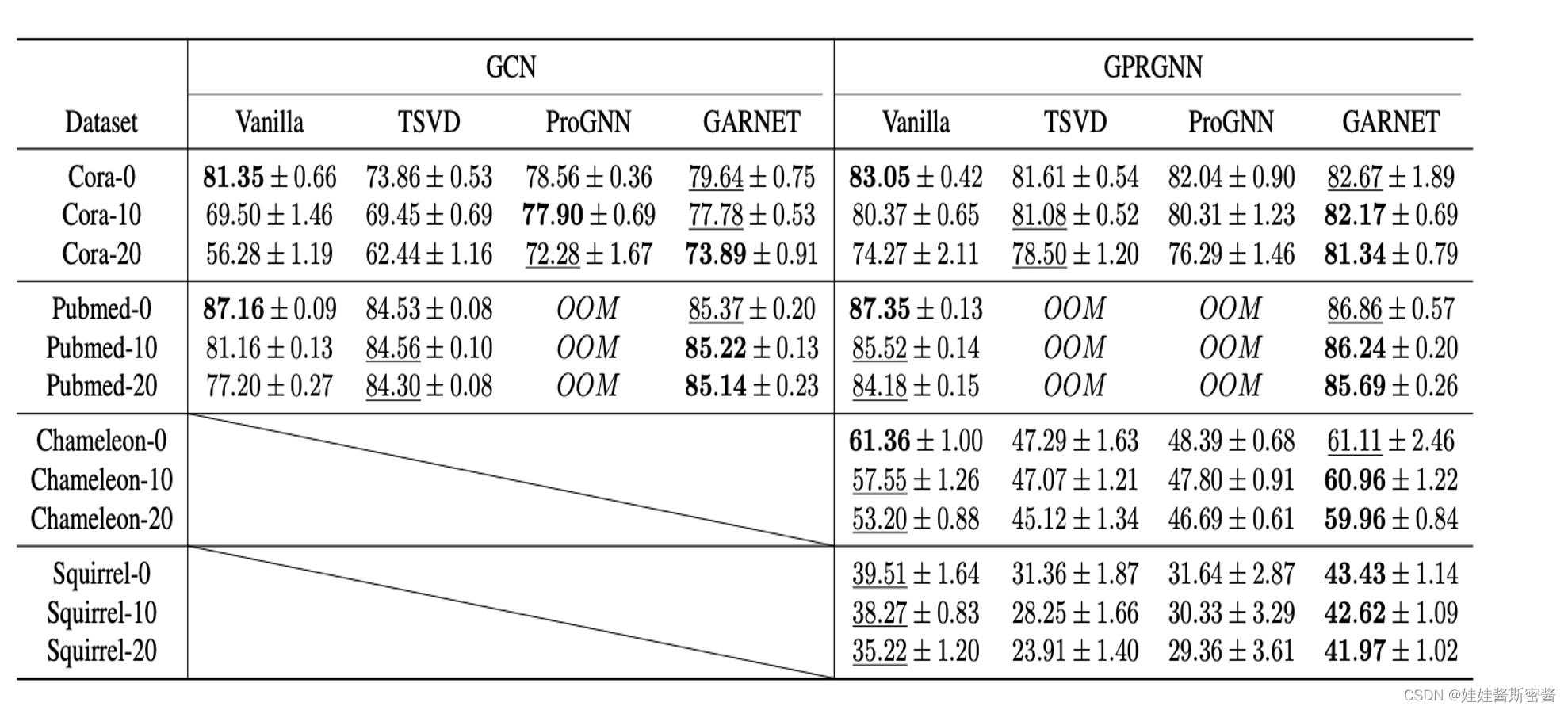
作者分别在目标攻击和非目标攻击上做了相关的实验:
分别是两个同质图数据集和两个异质图数据集。由于GCN框架在异质图的数据集上表现的不好,所以作者就没有写出来。

总结与一些疑问
