文章目录
0 abstract
- 隐式神经表示(INR)是一种基于深度学习(DL)的图像压缩解决方案。通过训练一个权重小于图像像素数的INR模型,将图像的坐标映射到对应的像素值,可以对图像进行压缩。虽然传统的INRs训练方法是基于加强像素图像一致性,但我们建议通过使用一种新的结构正则器进一步提高图像质量。我们提出结构正则化INR压缩(SINCO)作为一种新的INR图像压缩方法。SINCO通过使用分割网络来惩罚从压缩图像中预测的分割掩码的差异,使压缩图像的结构与真实图像相一致。我们在脑MRI图像上验证了SINCO,表明它比一些最近的INR方法能获得更好的性能。
1 introduction
- 在许多应用中,图像压缩是实现高效传输和存储图像的重要步骤。由于数据的高维特性,它被广泛应用于生物医学成像。传统的图像压缩方法是基于固定的图像变换[1,2],而深度学习(DL)作为一种强大的数据驱动替代方法最近出现了。大多数基于dl的压缩方法都是基于将自编码器训练为从图像像素到量化潜在表示的可逆映射[3-5]。
- 在这项工作中,我们通过关注最近使用隐式神经表示(INRs)的范式,寻求一种替代基于自动编码器的压缩方法。INR指的是一类DL技术,它通过使用多层感知器(MLP)来学习从输入坐标(如(x, y))到相应物理量(如(x, y)处的密度)的映射[6-10]。最近的研究显示了INR在图像压缩中的潜力[11-15]。基于INR的压缩背后的关键思想是训练MLP来表示图像,并将训练过的模型的权重作为压缩数据。然后可以通过在所需的像素位置上评估预训练的MLP来重建图像。使用INRs进行图像压缩的传统训练策略旨在加强预测图像像素和真实图像像素之间的一致性。另一方面,众所周知,通过向所需图像注入先验知识,可以提高图像质量[16,17]。基于这一观察结果,我们提出了基于结构正则化的INR压缩(SINCO)作为一种新的方法来改进基于INR的图像压缩。我们的结构正则化器寻求提高真实分割图和使用预训练分割网络从INR压缩图像中获得的图像之间的Dice得分。我们验证了脑MR图像上的SINCO,表明它可以导致比传统的基于inr的图像压缩方法的显著改进。我们表明,结合传统的图像一致性损失和我们的结构正则化器,使SINCO学习INR,可以更好地保存所需的图像特征。
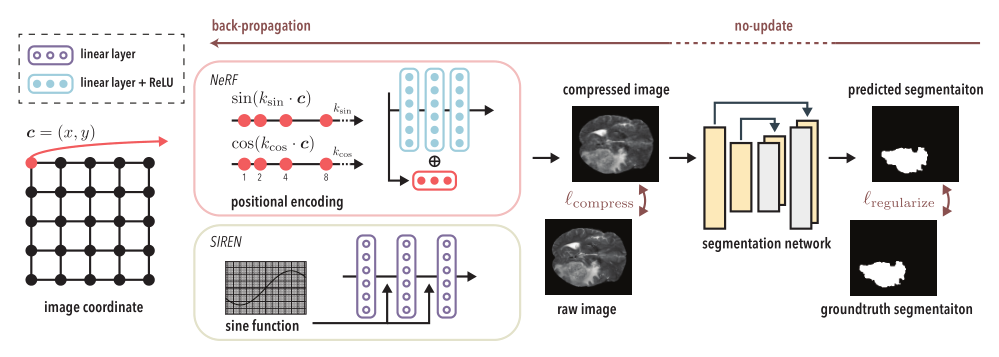 【图1:SINCO由两个部分组成:(a)多层感知器(MLP),通过将图像的坐标映射到相应的像素值来压缩图像;(b)从压缩图像中预测分割掩码的分割网络。与传统的INR方法不同,SINCO使用来自正则化器的信息,惩罚预测和地面真相分割掩模之间的差异。】
【图1:SINCO由两个部分组成:(a)多层感知器(MLP),通过将图像的坐标映射到相应的像素值来压缩图像;(b)从压缩图像中预测分割掩码的分割网络。与传统的INR方法不同,SINCO使用来自正则化器的信息,惩罚预测和地面真相分割掩模之间的差异。】
2 background
-
INR(也被称为神经场)表示一类使用基于坐标的mlp连续表示物理量的算法(参见最近的综述[6])。最近的工作显示了INRs在许多成像和视觉任务中的潜力,包括3D渲染中的新视图合成[7],视频帧插值[8],计算机断层扫描[9]和动态成像[10]。INR背后的关键思想是训练MLP将空间坐标映射到相应的观测物理量。训练后,可以在所需的坐标上评估预训练的MLP,以预测相应的物理量,包括不在训练范围内的位置。设c表示输入坐标的一个向量,v表示对应的物理量, M θ M_θ Mθ是一个MLP,可训练参数 θ ∈ R n θ∈\mathbb{R}^n θ∈Rn。INR训练可以表述为: θ ^ = arg min ∑ i = 1 N l i n r ( M θ ( c i ) , v i ) . (1) \widehat \theta=\argmin\sum_{i=1}^{N}\mathcal{l}_{inr}(\mathcal{M}_\theta(c_i),v_i).\tag{1} θ =argmini=1∑Nlinr(Mθ(ci),vi).(1)其中 N ≥ 1 N\geq1 N≥1为训练对个数 ( c , v ) (c,v) (c,v)。 l i n r l_inr linr的常用选择包括 l 2 l_2 l2和 l 1 l_1 l1规范。
-
INRs最近被用于图像压缩[11-14]。压缩隐式神经表示(COIN)[11]是一项开创性的工作,它通过将图像的像素位置(即c = (x, y))映射到像素值来训练MLP。将COIN中预训练的MLP量化后用作压缩数据。为了重建图像,可以在用于训练的相同像素位置上评估模型。有几篇论文研究了元学习方法,通过首先在大量数据点集合上训练MLP,然后在依赖于实例的MLP上对其进行微调来加速COIN[12,13,18]。最近的两篇论文提出了正则化基于inr的图像压缩,方法是对MLP的权重使用’ 0-和’ 1-范数惩罚,以提高压缩率[12,14]。
-
SINCO中的结构正则化是基于使用预训练卷积神经网络(CNN)的图像分割(参见主题[19]的综合综述)。在基于dl的图像分割的背景下,已有大量的文献可以整合到SINCO中[20-22]。据我们所知,此前没有研究在基于inr的图像压缩环境中考虑更高层次的结构正则化。值得一提的是,我们的结构正则化器与现有的INR压缩方法完全兼容;例如,可以很容易地将结构正则化器与另一个 l 0 l_0 l0正则化器结合起来。
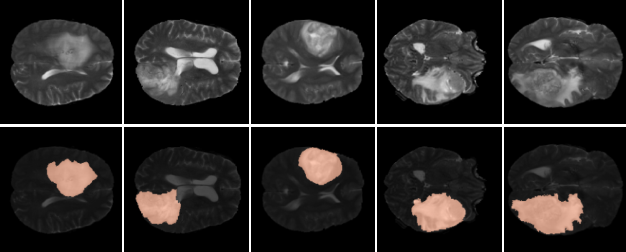
【图2:测试图像(上)和对应的分割掩码(下)用于我们的数值评估。】
3 proposed method
- SINCO由两个部分组成: (a)一个 MLP M θ \mathcal{M}_θ Mθ,它通过将图像的坐标映射到相应的像素值来表示图像;(b)一个 CNN g φ g_φ gφ,它预测由MLP产生的压缩图像的分割掩码。具体来说,设 x ∈ R H × W x\in \mathbb{R}^{H×W} x∈RH×W 表示我们要压缩的高H宽W的图像。设 c ∈ R H W × 2 c\in\mathbb{R}^{HW ×2} c∈RHW×2表示 x x x 内的所有像素位置,然后训练 M θ \mathcal{M}_θ Mθ 以c为输入,预测所有对应的 HW 像素值。我们将 M θ \mathcal{M}_θ Mθ 的输出格式化为压缩后的图像 x ^ ∈ R H × W \widehat x∈\mathbb{R}^{H×W} x ∈RH×W 。函数 g φ g_φ gφ 表示接受压缩图像并预测分割掩码的分割 CNN。 s ^ = g φ ( x ^ ) \hat s=g_φ(\widehat x) s^=gφ(x ) 。SINCO管道如图1所示。
3.1 network architecture
- 我们为 M θ M_θ Mθ 实现了两种不同的架构:(a) SIREN[23],它包含线性层,后面是正弦激活函数; (b) NeRF,它包含位置编码,在将 c 传递给 M θ M_θ Mθ之前展开 c : γ ( c ) = ( sin ( 2 0 π c ) , cos ( 2 0 π c ) . . . sin ( 2 L f π ⏟ k sin c ) , cos ( 2 L f π ⏟ k cos c ) ) (2) \gamma(c)=(\sin(2^0\pi c),\cos(2^0\pi c)...\sin(\underbrace{2^{L_f}\pi}_{k_{\sin}} c),\cos(\underbrace{2^{L_f}\pi}_{k_{\cos}}c))\tag{2} γ(c)=(sin(20πc),cos(20πc)...sin(ksin 2Lfπc),cos(kcos 2Lfπc))(2)其中, L f > 0 L_f>0 Lf>0 表示频率的个数。NeRF 的 M θ \mathcal{M}_θ Mθ 由线性层和 ReLU 激活函数组成。对于 NeRF 体系结构,我们还添加了从输入层到中间层的残余连接。我们随后将基于这两个 mlp 的 SINCO 表示为 SINCO (SIREN) 和 SINCO (INR)。我们采用广泛使用的 U-Net[22] 架构作为分割网络 gnn 的 CNN。
3.2 training strategy
-
SINCO 是通过最小化以下损失来训练的: l S I N C O = l c o m p r e s s ( x ^ , x ) + λ l r e g u l a r i z e ( s ^ , s ) . (3) l_{SINCO}=l_{compress}(\widehat x,x)+\lambda l_{regularize}(\hat s,s).\tag{3} lSINCO=lcompress(x ,x)+λlregularize(s^,s).(3)其中 s 为 x 的参考分割掩模,λ≥0 为用结构正则化平衡图像一致性的参数。我们实现 l c o m p r e s s l_{compress} lcompress 作为 l 2 l_2 l2 范数在压缩图像和真实图像之间。我们实现 l r e g u l a r i z e l_{regularize} lregularize 为 1 − D i c e ( s ^ , s ) 1−Dice(\hat s, s) 1−Dice(s^,s),其中 D i c e ( s ^ , s ) Dice(\hat s, s) Dice(s^,s) 是压缩图像预测的分割掩码与 真实掩码之间的 Dice 得分系数。在eq.(3)中,假设分割网络 g φ g_φ gφ 是预训练的,这意味着我们只在训练时优化 M θ \mathcal{M}_θ Mθ 的参数。注意,当 λ=0 时,eq.(3)等价于传统的基于 inr 的图像压缩。训练结束后,我们遵循[11]中的方法,将 M θ \mathcal{M}_θ Mθ 的权重从32位量化到16位。
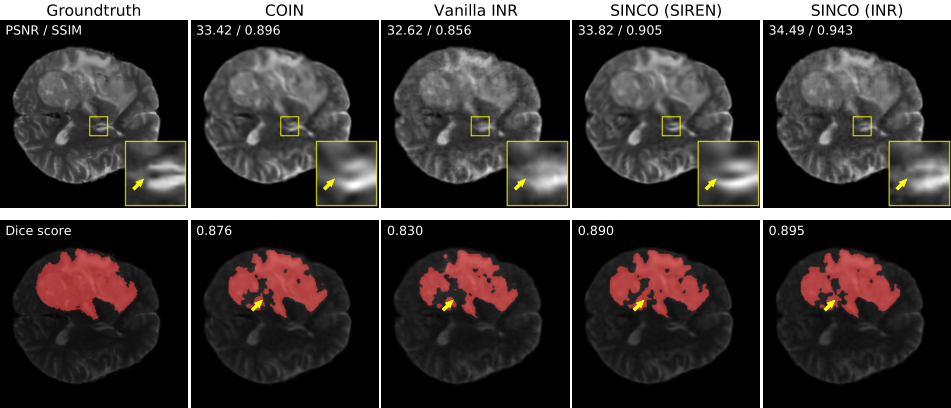 【图3:用SINCO和两条INR基线得到的压缩图像(上)和对应的分割掩码(下)的可视化插图。图像的左上角提供了用于图像压缩的PSNR和SSIM值以及用于图像分割的dice score值。这幅图表明,SINCO可以在定量和定性上显著改善图像质量。注意用黄色箭头突出显示的SINCO图像的质量。】
【图3:用SINCO和两条INR基线得到的压缩图像(上)和对应的分割掩码(下)的可视化插图。图像的左上角提供了用于图像压缩的PSNR和SSIM值以及用于图像分割的dice score值。这幅图表明,SINCO可以在定量和定性上显著改善图像质量。注意用黄色箭头突出显示的SINCO图像的质量。】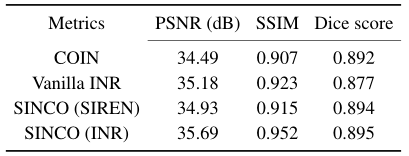
【表1:测试图像的平均定量评价指标。从该表可以看出,通过施加结构正则化,SINCO可以比INR基线获得更好的图像压缩和分割性能。】
4 numerical experiments
4.1 setup and comparison
- 在我们的实验中,我们使用了从 Decathlon 数据集获得的带有相应分割掩码的脑肿瘤 MR 图像。我们选取了10张分辨率为 240×240 的测试图像。图2 展示了我们实验中使用的几张带有相应肿瘤分割掩模的图像。我们将 SINCO 与两种参考 INR 方法进行比较:(a) COIN3,第二节讨论的一种最新的INR方法,和(b) Vanilla INR,一种将 λ 设为0的SINCO (INR)的变体。请注意,由于COIN也使用SIREN作为其MLP体系结构,因此可以将其视为使用不同损耗的SINCO (SIREN)。对于所有的方法,我们使用相同的压缩率,以每像素比特(bpp)量化: b p p = bit per parameters × # parameters # pixels . bpp=\frac{\text{bit per parameters}\times\#\text{parameters}}{\#\text{pixels}}. bpp=#pixelsbit per parameters×#parameters.在我们的实验中,我们将bbp设置为1.2,对应于相对于原始文件大小2%的压缩率。我们评估了所有的方法在图像压缩和图像分割使用压缩图像。对于图像压缩,我们使用了两个广泛使用的量化指标,峰值信噪比(PSNR),测量db,结构相似指数(SSIM)。我们使用Dice评分系数来评价图像分割。
4.2 implementation details
- 我们按照[22]训练分段网络gnn。我们在训练中使用了来自相同数据集的大约500张图像。相应的训练损失可以写成 ∑ i = 1 M l s e g ( g ϕ ( x i ) , s i ) . (4) \sum_{i=1}^{M}l_{seg}(g_\phi(x_i),s_i).\tag{4} i=1∑Mlseg(gϕ(xi),si).(4)其中 M≥1 表示训练样本数, l s e g l_{seg} lseg 对应二元交叉熵[22]。我们使用Adam[25]作为学习率0.0001的优化器。我们将训练周期设置为75,批次大小设置为8。在训练SINCO时,我们将λ In(3)设为1,将Lf In(2)设为12。我们使用Adam[25]作为学习率0.001的优化器。我们把训练时间设定为5万次。我们在一台配备了Intel Xeon Gold 6130处理器和NVIDIA GeForce RTX 1080Ti GPU的机器上进行了实验。
4.3 result
- 图3 展示了SINCO和其他两种INR方法的可视化结果。对于图像压缩,SINCO比其他INR方法获得了更高的PSNR和SSIM值,同时也提供了更清晰的图像,特征更符合地面真相。例如,SINCO可以重建由黄色箭头突出显示的更清晰的脑组织,而INR基线模糊了相同的特征。对于使用压缩图像的图像分割,SINCO在定性和定量上优于INR基线。特别是,与COIN相比,SINCO (SIREN)相对于真实分割掩码(参见黄色箭头突出显示的分割掩码)提供了更一致的结果。请注意,COIN还使用SIREN作为其MLP体系结构。图4 所示的另一组视觉结果也与观测结果一致,即SINCO导致了图像质量的显著改善。表1 总结了所有测试图像的定量结果。该表表明,在相同的MLP架构下(即COIN vs . SINCO (SIREN)和V anilla INR vs . SINCO (INR)), SINCO可以通过利用结构正则化实现更好的性能。
conclusion
- 我们提出了一种新的结构正则化图像压缩方法,使用隐式神经表示。SINCO背后的关键思想是使用预先训练的分割网络,以确保INR压缩图像产生准确的分割掩模。我们在大脑MR图像上的实验表明,SINCO在定量和定性上都优于传统的INR方法。在未来的工作中,我们将进一步研究用于高维数据压缩(例如3D或4D MRI[26])的SINCO,并利用最近发展的元学习策略来加速INR训练[18]。