这篇论文要解决的实际问题(研究点)是什么?
一般而言,用户基于item的显性反馈(比如评分数据)是可以出显示出用户对某样item的喜好程度的。但是现实生活中其实还存在着很多的隐性反馈(比如购买记录、浏览记录,搜索记录等)这样子的数据量其实是有非常的多的,但这一类数据普遍都存在一个缺陷,即它们是很难有证据显示出用户对该item的不喜欢程度(we lack substantial evidence on which products consumer dislike),至少大部分是,毕竟用户的打分才是最直接表示喜好的一种行为。所以如何处理隐性数据,以及如何显示出用户对item的喜好程度,成为了本文要研究的问题。
本文做的实验是分析用户对电视节目的watch habits,并且做出推荐。而拥有的数据都是隐性的数据,比如电视节目的观看时间以及次数等。
这个实际问题(研究点)目前的处理现状是什么?(即原有的方法是什么)
隐性反馈的一些特性
- 没有负面反馈( No negative feedback)。一般来说通过观察用户的行为(比如购买记录等)我们可以大致判断用户可能是喜欢某个物品,而对于没有记录的物品我们则是无法判断的,可能是因为用户不喜欢也有可能是因为用户根本不知道这个物品。而这在显性反馈里面是不存在这种不对称的信息的,比如,显性反馈更加注重于收集到的信息(比如user-item-rating),这里的 rating其实一定程度上是可以反应用户的喜好的,并且剩下的没有评分的数据信息在我们分析的时候是可以省略掉的。然而这在收集隐性反馈数据里是绝对不存在的,因为如果仅仅聚焦于收集用户行为数据(feedback)会让我们一直在收集正面的反馈,让我们在描述用户profile的时候,失去准确性。所以在隐性反馈数据中,最重要的是处理消失的最能反应用户负面反馈的数据。
- 隐性数据有固有的噪音。所以要针对用户的行为记录进行具体的分析。购买记录不一定能显示用户喜欢这个物品,可能它仅仅是一个礼物。
- 显性数据的“数字”可以显示用户的喜好程度,而隐性数据的“数字”可以反应用户行为的“置信程度(confidence)”而这个要结合具体的问题进行具体行为次数的分析。一般来说,一个重复发生的行为更可能反应用户的观点。
- 评估隐性反馈的推荐需要有合适的方法,一般如果有用户的评价分数的话,可以用诸如均方误差来衡量预测成功。然而对于隐式模型我们必须考虑item的可用性,和与其他item的竞争性以及重复反馈等数据(例如若我们收集关于电视观看的数据,则无法评估这个节目是否被看了多次,或如何比较两个同时出现的节目,因此不能被用户观看)
原有的方法
- Neighborhood models(user-oriented和item-oriented)
此类方法对于隐性反馈数据集来说不够友好,他们不提供区分用户喜好的灵活性和这些喜好里面的置信程度的灵活性。 - Latent factor models
Latent factor models是一种可以替代协同过滤的方法,它的目标是揭示解释观察到的评级的潜在特征;比如pLSA,神经网络,LDA.还有很受欢迎的SVD,因为它的准确率和可扩展性。典型的模型将每个用户u与用户向量 ∈ ,每个物品i和物品向量 ∈ 联系起来。预测是通过取内积来完成的,即 。更多涉及的部分是参数估计,一般此类的工作都是应用于显示反馈数据集,直接对观察到的评分进行建模,但是同时为了避免过度拟合,也会加入惩罚项。

它的结果一般比协同过滤要好,只是缺少可解释性
本篇论文中提出的工作是在隐式反馈数据集里面使用SVD,给评分数据加上置信度,去修改公式以及优化项。
本文提出的解决问题的方法(模型)是什么?
由于隐性反馈数据是不能显示用户的喜好程度的,作者把隐性反馈数据转换成了两个维度,一个是喜好程度(preference),另一个是置信程度(confidence),以此,得出的分数,我们是可以看出用户的喜好程度的(transform the raw observations(the values) into distinct preference-confidence pairs( , )),然后再使用SVD方法。
参数解释
:是评分数据|或者次数的数据
:显示用户u对物品i的喜好程度
:显示对
的置信程度(即这个答案的可信程度)
m:用户数量
n:物品数量
X:含有用户向量的矩阵(每一行代表用户, m* f ,f是factors的大小)
Y:含有用户向量的矩阵(每一列代表物品,n* f,f是factors的大小)
公式
所以,当
时,
,
会随着
的增大而增大,增长率由
控制,本文作者经过实验后设置为40.

损失函数

我们可以注意到这个目标函数和上面提到的拥有显性反馈数据的矩阵分解的目标函数有点相似,但是还是有两点重要的差别:
- 我们需要为不同的confidence level作出解释
- 我们需要为所有的(u,i)pairs进行优化,而不是仅仅为显性反馈数据里面观察到的数据进行优化。
一般地,正则项部分是为了防止过拟合,参数 是数据独立的,和X、Y没有关系,可以由cross validation求得。所以在求损失函数最小的时候,一般固定参数 的值,求前面一部分公式值最小,也就是整体最小了。所以
Loss(X,Y) =
通过计算损失函数Loss(X,Y)的最小值,来得到我们的用户向量 ∈ 和物品向量 ∈ 。
从公式可以知道,我们的损失函数包含m*n个参数,对于一般的dataset,参数的数据量将是billion级别的,所以在这里我们不使用一般在隐性反馈数据集里使用的梯度下降(sgd)进行函数优化。在这里,我们使用交替最小二乘法-Alternating-least-squares进行函数优化。
而怎样使用交替最小二乘法进行函数优化呢?
由公式可知,里面已经出现平方误差最小了,那现在要出现交替这件事了,因为X,Y都是未知的参数矩阵,因此我们需要用到轮流交替固定参数来对另一个参数求解。
-
先初始化X,Y,可以任意初始化
-
利用for u=1,2…m , 先固定Y,对loss function做X的偏微分,使其偏微分等于0:
得到

3. 利用for i=1,2…n , 再固定X,对loss function做Y的偏微分,使其偏微分等于0:
得到
- 把 和 带入损失函数,使得损失函数最小。重复上面2和3步骤,直到达到自己想要的损失函数的最低值或者达到更新多少次的要求。
关于这一块公式求导的具体步骤,详见求解最小二乘法步骤
作者提出,他的方法其实也是可以有进一步的变形的,比如
- 可以设定 的最小阈值,从而设定
- 的值也可以进行改变,比如
本文的方法与原有的方法比较有哪些优势以及劣势?
解决了隐性反馈数据固有的几个特性(上面有提及)的问题
- 一般的评分或者次数的数据,很多时候并不能够显示该数的真实情况,隐性数据有它固有的噪音存在,所以作者进一步把 变成了两个可以解释的维度,一个是 ,表示用户的喜好程度,一个是 表示用户喜好程度的置信程度。这更好的反应了数据的本质,以及对于提高数据准确率是非常重要的。
- 算法可以用线性时间计算完
这个实际问题的评估方式是什么?
:为u推荐i得到的百分等级排名(we denote by
the percentile-ranking of program i within the ordered list of all programs prepared for user u)
= 0% mean that program i is predicted to be the most desirble for user u
=100% indicates that program i is predicted to be the least prefereed for user u,thus placed at the end of the list.
所以作者使用的评价指标是
的平均值,即
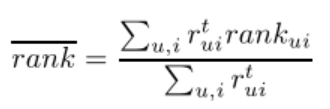
一般来说,这个指标越低越好,作者随意预测的结果是 =50%,所以,一般实验结果比这个好就可以了。
这个实际问题拥有怎么样的数据?
包含4个礼拜的300,000个机顶盒和17,000个电视节目的观看次数的数据。数据 代表用户看了电视节目的次数,非0数据有32million(处理后变成2million)经过训练后,用接下来一个礼拜的数据进行测试。
该论文是如何处理这份数据集的?
针对不同的场景以及数据,可以做相应的操作。
比如,这里把
<0.5的数据都删除,电影看1次,
=1,而电视剧看2集,
=2,所以依据这个,作者设置
,并且
等。
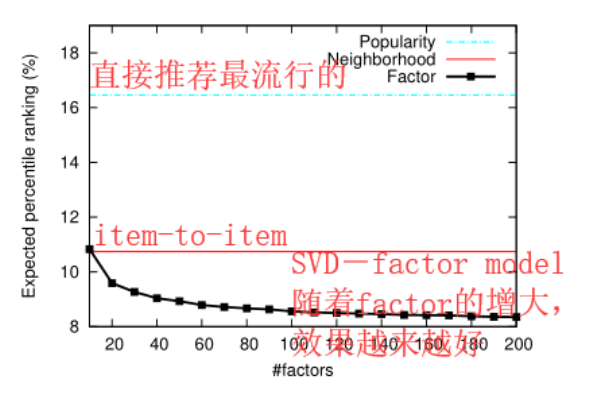
该论文的对比方法,以及实验结果
对比方法
方法一:基于电视节目的流行度进行排序,越流行的电视节目排序靠前。
方法二:item-to-item,但是使用的评分不知道是否是这里变换过后的评分(还是之前的观看次数?暂且不管)
接下来你要做什么?
- 读 “Item-based top-N recommendation algorithms”
- 读 "Implicit Feedback for Recommender Systems "