深度学习论文: WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
PDF: https://arxiv.org/pdf/2303.14814.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
WinCLIP是一种基于CLIP(Contrastive Language-Image Pretraining)模型的方法,用于零样本和少样本的异常分类和分割任务。该方法结合了文本编码器和图像编码器,利用CLIP模型的文本-图像关联能力来实现准确的异常识别和定位。
WinCLIP的核心思想是通过将不同状态和模板转换为文本嵌入,然后与图像编码器生成的图像嵌入进行关联,学习到异常和正常样本之间的关系。为了实现这一目标,WinCLIP引入了参考关联的概念。它将参考关联应用于基于视觉的异常评分图,通过文本引导评分的小样本AS/AC聚合而来。参考关联有助于捕捉异常样本的特征,并实现准确的分类和分割。
在实验中,WinCLIP在多个数据集上进行了评估,包括MVTec AD、CIFAR-10、MNIST等。实验结果显示,WinCLIP在零样本和少样本的异常分类和分割任务上表现出了优秀的性能。它超过了其他先进方法,并且在不同的异常类型和样本数量下都展现出了鲁棒性和泛化能力。

2 WinCLIP and WinCLIP+
通过CLIP文本编码器将各种状态和模板合成并转换为两个文本嵌入,作为类原型。类原型与WinCLIP中零样本AC/AS的CLIP图像编码器的多尺度特征相关。WinCLIP+将小窗口/中窗口补丁上的参考关联(patch/WindowAssociation)应用于基于视觉的异常评分图,这些异常评分图是为具有文本引导评分的小样本AS/AC聚合的。
2-1 Language-driven zero-shot AC
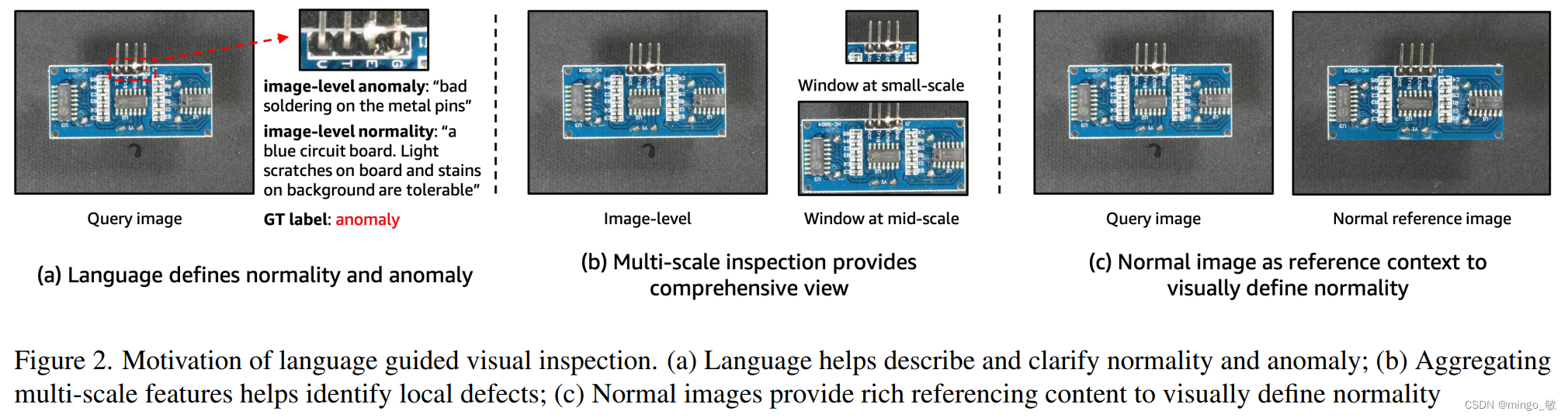
论文提出一个一个名为CLIP-AC的框架,以改善基于初始CLIP的零样本分类,并在零样本设置下改进异常分类。
为了更准确地定义对象的两个抽象状态,引入了一个组合提示集合(Compositional Prompt Ensemble),用于生成预定义的(a)每个标签的状态词列表和(b)文本模板的所有组合,而不是自由编写定义。状态词包括大多数对象共享的常见状态,例如正常的“flawless”和异常的“damaged”。此外,我们可以根据先前对缺陷的了解,选择性地添加特定于任务的状态词,例如PCB上的“bad soldering”。此外,我们还为异常任务精心策划了一个模板列表,例如“a photo of a [c] for visual inspection”。通过这种方式,我们能够更好地定义对象的状态,并提供更准确可靠的异常分类。
-
CPE(Contextual Prompt Engineering)与CLIP Prompt Ensemble是不同的。CLIP Prompt Ensemble不解释对象标签(例如“cat”),只通过试错选择模板来增强对象分类,其中包括一些不适合异常任务的模板,例如“a cartoon [c]”。因此,CPE中的文本与CLIP的联合嵌入空间中的图像更加对齐,适用于异常任务。
-
采用CPE(Compositional Prompt Ensemble)的双类设计,与标准的单类方法相比,是一种新颖的定义异常的方法。由于异常检测是一个开放性问题,因此它具有不适定性。以往的方法仅通过正常图像来建模正常性,将任何与正常性偏离的情况视为异常。然而,这种解决方案很难区分真正的异常和可接受的正常性偏差,例如"scratch on circuit"与"tiny yet acceptable scratch"之间的区别。但是,语言可以用具体的词语来明确定义状态。通过使用CPE,双类设计能够更准确地定义异常情况,并提供更可靠的异常检测结果。
论文使用的 Contextual Prompt Engineering 如下:

2-2 WinCLIP for zero-shot AS
使用预训练的CLIP模型,并提出了WinCLIP,它可以有效地提取和聚集与语言一致的多尺度空间特征,用于零样本异常分割。
给定CPE的语言引导异常评分模型,提出了用于零样本异常分割的基于窗口的CLIP(WinCLIP)用于零样本异常分割方法,以预测像素级异常。WinCLIP提取具有良好语言对齐和x局部细节的密集视觉特征,然后在空间上应用 a s c o r e 0 ascore_{0} ascore0来获得异常分割图。具体地,给定分辨率为h×w的图像x和图像编码器f,WinCLIP获得d维特征图 F W ∈ R h × w × d F^{W}∈R^{h×w×d} FW∈Rh×w×d的映射,如下所示:
1.生成一组滑动窗口{wij}ij,其中每个窗口 w i j ∈ 0 , 1 h × w w_{ij}∈{0,1}^{h×w} wij∈0,1h×w是一个二进制掩码,对于(i, j)周围的k×k核是局部活动的。
2.收集每个输出嵌入 F i j W F^{W}_{ij} FijW,根据应用每个 w i j w_{ij} wij后x的有效面积计算,定义为: F i j W : = f ( x ⊙ w i j ) F^{W}_{ij}: =f(x⊙w_{ij}) FijW:=f(x⊙wij),其中⊙是元素乘积(见下图)。

Harmonic aggregation of windows:
对于每个局部窗口,零样本异常得分 M 0 , i j W M^{W}_{0,ij} M0,ijW是窗口特征 F i j W F^{W}_{ij} FijW与合成提示集成的文本嵌入之间的相似性。该分数被分布到本地窗口的每个像素。然后,在每个像素,聚合来自所有重叠窗口的多个分数,以通过谐波平均改进分割,对分数进行更多加权,以实现预测。

Multi-scale aggregation:
内核大小k对应于计算WinCLIP方程中每个位置的周围上下文的数量。它控制着分割中局部细节和全局信息之间的平衡。为了捕捉尺寸从小到大的缺陷,我们聚合了多尺度特征的预测。具体而言,我们使用了以下尺度的特征:
- ( a ) 小尺度:在ViT的补丁尺度中为2×2,对应于像素中的32×32。
- ( b ) 中尺度:在ViT中为3×3,对应于像素中的48×48。
- ( c ) 图像尺度特征:由于自注意力机制而捕获图像上下文的ViT类token。
为了聚合这些多尺度特征,我们采用了谐波平均的方法。这种方法可以平衡不同尺度特征之间的重要性,从而获得更全面的预测结果。
2-3 WinCLIP+ with few-normal-shots
对于一个全面的异常分类和分割,文本引导的零样本方法是不够的,因为某些缺陷只能通过视觉参考而不仅仅是文本来定义。为了更准确地定义和识别异常,我们提出了WinCLIP的扩展:WinCLIP+,通过合并K个正常参考图像 D : = ( x i , − ) i = 1 K D:={(x_{i},−)}^{K}_{i=1} D:=(xi,−)i=1K。WinCLIP+结合了文本引导和基于视觉的方法的互补预测,以实现更好的异常分类和分割。
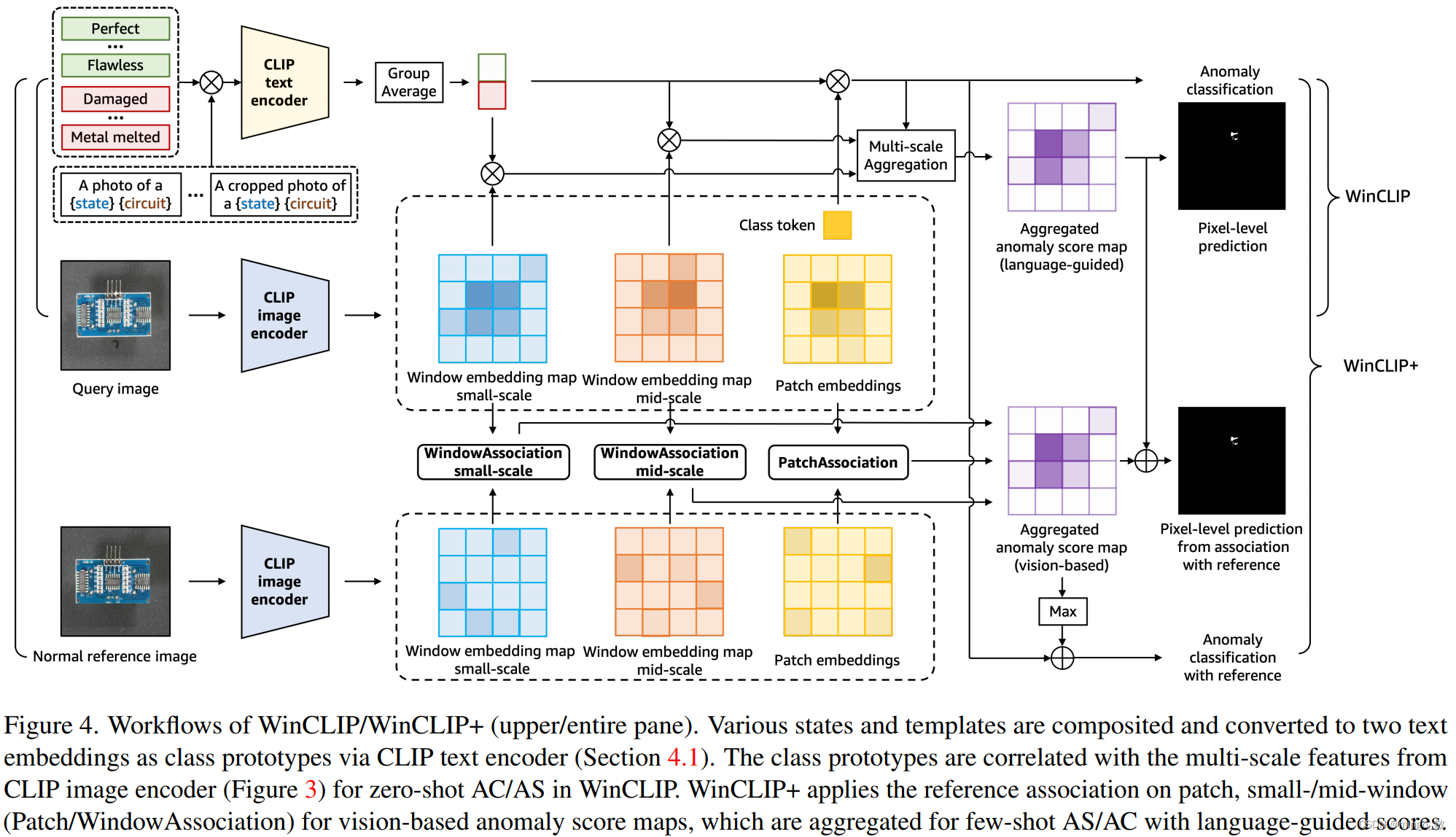
首先引入了一个关键模块,称为参考关联模块,用于合并给定的参考图像。该模块可以简单地存储和检索基于余弦相似性的记忆特征R。通过将查询图像提取的特征F(例如,patch-level2)与这样的模块结合,我们可以进行异常分割的预测M。预测结果M是一个h×w的矩阵,其中每个元素的值在0到1之间。这种预测结果可以提供关于图像中异常区域的概率估计,值越接近1表示越可能是异常区域。
![]()
在小样本的情况下,我们从三个不同的特征构建了单独的reference memories:(a) 小尺度特征FW的WinCLIP特征,(b) 中等尺度特征的WinCLIP特征,以及© 具有全局上下文的倒数第二个特征FP。即 RWs、RWm和RP。然后,对给定查询进行了多尺度预测并进一步平均得到查询的异常分割
![]()
此外,为了进行异常分类,结合 M W M^{W} MW的最大值和WinCLIP零样本分类得分。这两个分数具有互补的信息,特别是(a)一个来自小样本参考的空间特征,以及(b)另一个来自通过语言检索的CLIP知识:

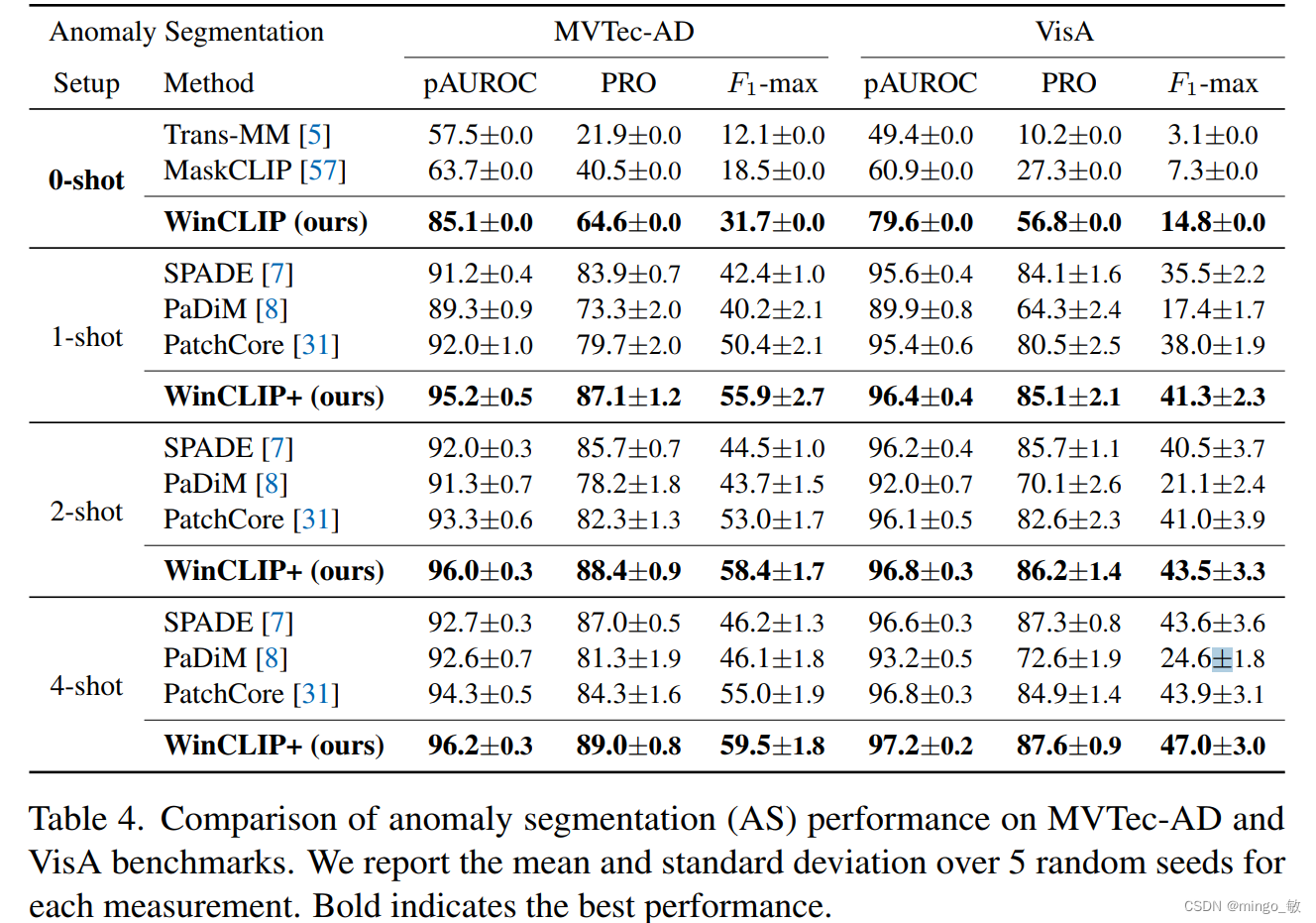
3 Experiments
Zero-/few-shot anomaly classification
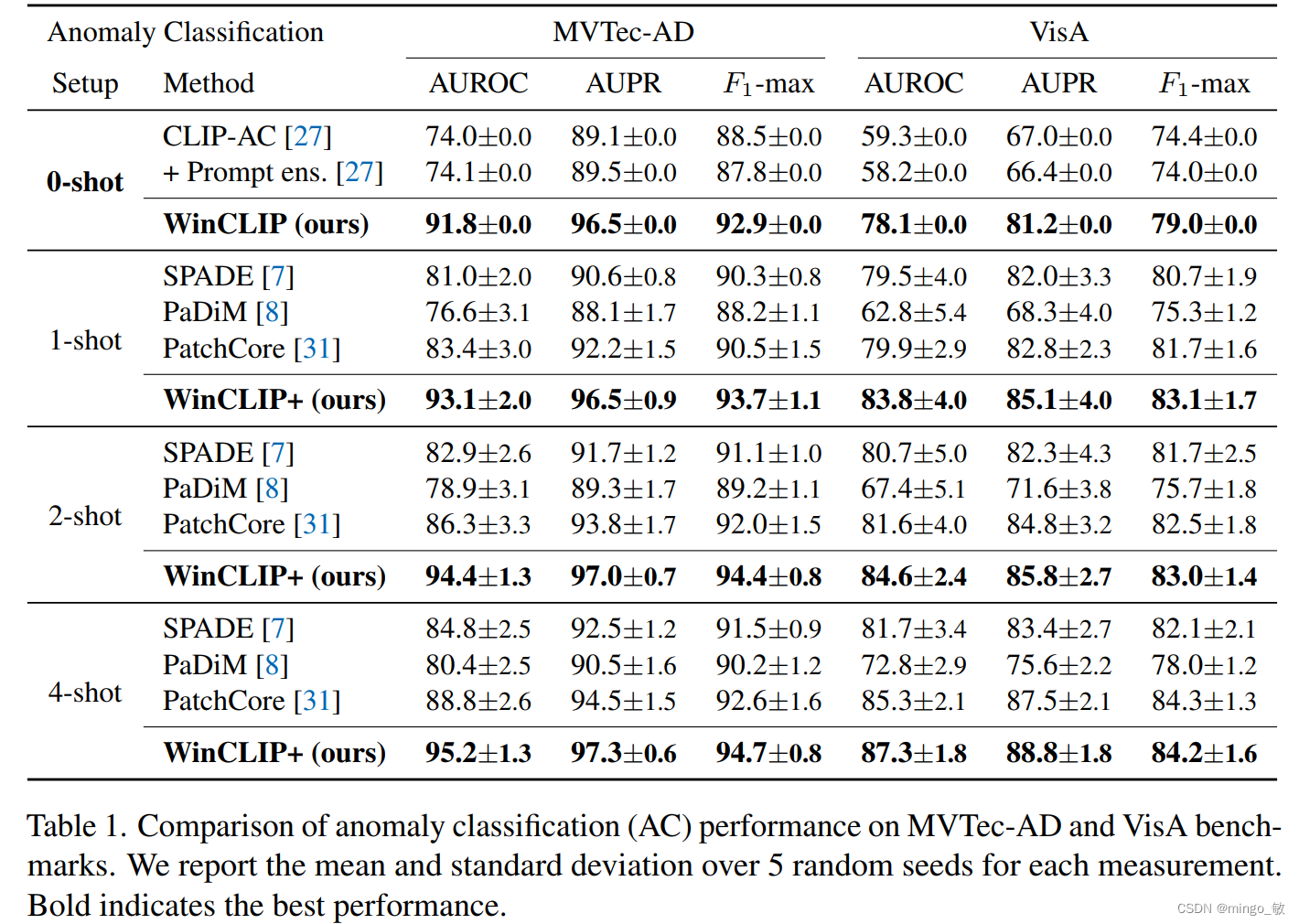
Zero-/few-shot anomaly segmentation