论文信息
| 名称 | 内容 |
|---|---|
| 论文标题 | Automatic Multi-Label Prompting: Simple and Interpretable Few-Shot Classification |
| 论文地址 | https://arxiv.org/abs/2204.06305 |
| 研究领域 | NLP, 文本分类, 提示学习 |
| 提出模型 | AMuLaP |
| 来源 | NAACL 2022 (main conference) |
阅读摘要
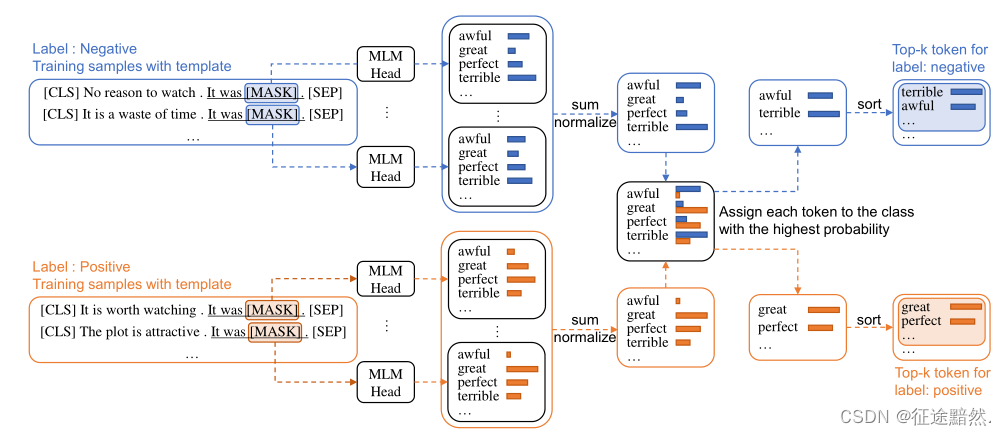
文章提出了一种简单确高效地构建verbalization的方法:
1. 对于每个标签 y i ∈ Y y_i∈Y yi∈Y,迭代所有的训练样本 x j ∈ D t r a i n x_j∈D_{train} xj∈Dtrain, x j x_j xj的基础真值标签也为 y i y_i yi。使用模型来预测[MASK]标记的标记概率,并将这n个样本的预测概率的平均值取为 z i z_i zi,其中 z i z_i zi是在整个词汇表上的向量,表示对词汇表上的每个词的平均概率。
2. 对于每个 y i ∈ Y y_i∈Y yi∈Y,初始化一个空的候选令牌集 S ( y i ) S(yi) S(yi)。
3. 对于每个 v ∈ V v∈V v∈V,其中 V V V是模型的词汇表,我们从每个标签的 z i z_i zi中检索 v v v的概率值 z i v z^v_i ziv。
4. 遍历所有的标签,每个标签都有一个 z z z,遍历每个位置,将 v v v赋给第m类的最可能令牌集 S ( y m ) S(y_m) S(ym),其中 m = a r g m a x i z i v m = argmax_i z^v_i m=argmaxiziv。
假设有3个标签,词汇表有2000,那么Z的形状为3*2000,然后遍历词汇表[0-1999],每个词我们去比较它在3个标签上的概率,取最大的然后放入这个标签对应的 S ( y ) S(y) S(y)中。
5. 对于 y i ∈ Y y_i∈Y yi∈Y,我们从 S ( y i ) S(yi) S(yi)中选取概率z^v_i最大的top-k个令牌,得到截断的词集 S ( y i ) S(yi) S(yi)。