Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python!
>>>点击此处查看往期Python教学内容
目录
Part1前言
我们的很多数据都是扁平化的,尤其是面板数据,例如一家企业有多种类型的股东,每一类股东又可能包含多名。如果我们想要统计根据股东类型统计出资额,就需要以股东类型来做分组,然后对组内所有股东的出资额进行加总。除了对组内数据进行加总,我们还可以进行均值、方差、计数等多种运算。而在 Python(Pandas) 中,我们不仅可以对一些数值类信息分组计算,还可以使用函数聚合的方式来对组内的字符信息进行自定义合并。本期文章我们将向大家介绍如何使用 Pandas 对数据进行基本的分组聚合,顺便介绍一下如何对数据进行排序。
本教程基于 pandas 1.5.3 版本书写。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写,本文分享的代码请使用 Jupyter Notebook 打开。
点给原文链接即可查看如何获取本文所有演示代码以及演示用的数据:Python 教学 | Pandas 分组聚合与数据排序
Part2分组聚合概述
在实际应用中,数据集往往是非常庞大而复杂的,其中包含了各种各样的信息和变量。很多时候我们数据都是以个体为单位的,一行数据描述的就是一个个体的各种信息,但有时也会出现一行数据无法存放某个信息的现象。例如我们有一个涉农上市公司的股东信息数据,数据中有股东名称和股东认缴出资额两个信息,由于一家上市公司可能包含不止一名股东,所以为了让数据更加清晰,通常会对数据进行展开保存,让每一个股东的信息都独占一行,其他的信息保持不变。不过当需要对不同上市公司的股东出资额做分析时就会发现数据没有那么直观了。对于这种情况,我们可以利用数据分组聚合把数据按照某些特定列进行分组(分类),计算每个分组下的数据的信息,从而简化数据分析难度。例如在上述场景中,我们可以使用数据分组聚合将数据按照公司名称分组,然后计算每个组内的股东出资额的总和、平均值等统计指标,从而更好地了出资情况,为进一步的分析提供有用的数据支持。
常见的数据处理工具一般都包含数据分组聚合的功能,在 Excel 中,可以通过“数据透视表”来实现不同分组内的总和、均值等常见的聚合方式;在 Stata 中,可以使用 collapse 命令完成分组聚合;在数据库(SQL)中,则是通过 GROUP BY 子句来实现;如果使用 Python,那么可以借助 Pandas 中的 groupby()函数来实现分组聚合。以上四种方式在数据分组聚合方面各有优劣,我们在下方做一个简单的总结。
-
Excel:优点是使用简单,界面简介,交互清晰;缺点是无法处理稍大的数据集,这一直是 Excel 这类办公软件的通病,虽然 Excel 的数据存储上限是 1048576 行,但是实际上处理数据量在几十万行的数据时就已经濒临崩溃。
-
Stata:更加适合有 Stata 基础的社科类学者,上手容易;不过 Stata 普及度不高,只符合小部分数据需求者的使用习惯。
-
SQL:SQL 可谓是分组处理数据的鼻祖了,由于 SQL 能够借助硬盘完成数据运算,所以在处理超大数据(大于内存空间)时也不会导致电脑崩溃,只是效率稍差了些。不过在 SQL 中修改数据是一件相对麻烦的事情,这一点和 Stata、Python 一样,使用灵活度方面比不上 Excel。
-
Python:Pandas 作为数据处理、分析的万能利器,对数据进行分组聚合当然是一件很简单的事情,对比 Excel 来说,Pandas 能够处理的数据量要大得多,而且在聚合时候不局限于常规的加总、计数、均值等方式,还可以利用自定义函数完成更加个性化的聚合操作。当然,这种 Python 处理的方式入手门槛也比较高 ,要求用户有一定的 Python 语言基础。
本期文章我们将着重介绍如何使用Python 中的 Pandas 进行数据的分组聚合操作。
Part3Pandas 分组函数 —— groupby()
正式介绍groupby()之前,我们先使用 pandas 读取演示用的涉农上市公司股东信息数据(样例)。
import pandas as pd
# 读取演示用的数据
data = pd.read_csv('./涉农上市公司股东信息表_13条样例数据.csv')
data
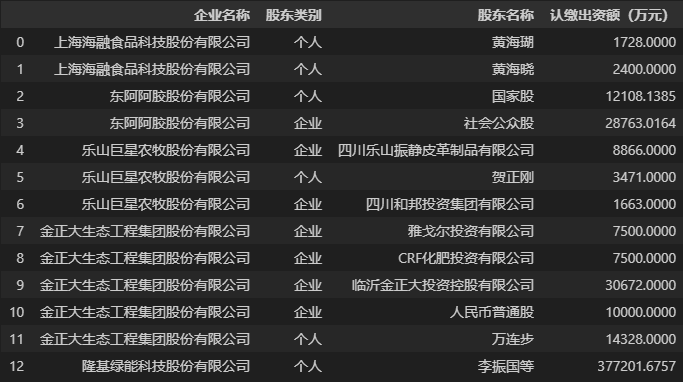
下面我们来介绍groupby()函数,它是 Pandas 中 DataFrame 类型的一个属性函数,即只有表格数据 DataFrame 才可以调用groupby()(Series 类型也有一个groupby()属性函数,但几乎用不到)。它的作用是根据指定的数据字段对表格进行分组,并返回一个分组器对象,它的基本语法和常用参数列表及含义如下。
df.groupby(by=None, axis=0, as_index=True, dropna=True, sort=True)
| 参数名称 | 参数可选值 | 参数用法含义 |
|---|---|---|
| by | 单个字段名称 或 包含字段名称的列表 | 必要的参数,是函数进行分组的依据,需要传入字段名称。如果根据某一个字段进行分组,那么传入该字段的名称即可;如果根据多个字段进行分组,则需要传入包含所有分组依据字段的名称,一定要注意多个字段名称的先后顺序。 |
| axis | 0 或 1 | 默认值为 0 ,表示按行进行分组,这也是最常用到的,符合我们的数据使用习惯;为 1 时表示按列进行分组(不是重点)。 |
| as_index | True 或 False | 默认值为 True,表示将分组依据的字段作为分组结果的行索引,如果分组依据包含多个字段,那么所有的字段都会被设置为行索引,聚合后的数据就是带有多级行索引的数据。设置为 False 时,只是对数据进行分组,聚合后不会将分组依据字段设置为索引。 |
| dropna | True 或 False | 默认值为 True,表示当分组依据字段中存在缺失值时,主动删除缺失值所在行;而当设置为 False 时,则会将缺失值也视为一个组进行分组。 |
| sort | True 或 False | 默认值为 True,表示会对聚合后的结果进行排序;设置为 False 时则不会排序,将按照分组字段的原始顺序排列,同时提高分组的效率。 |
上文提到,groupby()函数会返回一个包含分组结果的分组器,由于一个数据表分组后包含多个组别,所以不好直接展示出来,所以返回值是一个不可见的分组器结果,而且分组器还拥有更多属性,可以完成更多聚合操作。下面我们处理演示数据,以企业名称字段为依据对数据进行分组,代码如下。
# 以【企业名称】字段为依据对数据进行分组
data_grouped = data.groupby(by='企业名称', as_index=False)
# 尝试输出查看得到的分组器
print(data_grouped)
# 得到: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F5F2CA3490>
# 尝试输出分组器,只得到一个 DataFrameGroupBy 对象
虽然无法直接查看分组器中的内容,但是我们可以使用循环来获取不同分组的内容,代码如下。
# 使用字典推导式将分组器转为字典,“键”为分组依据,“值”为一个组的数据,是一个表格
All_groups = {name:group for name, group in data_grouped}
print(All_groups)
# 输出如下(已优化输出,实际输出排版略有不同)
"""
{ '上海海融食品科技股份有限公司': 企业名称 股东类别 股东名称 认缴出资额(万元)
11 上海海融食品科技股份有限公司 个人 黄海瑚 1728.0
12 上海海融食品科技股份有限公司 个人 黄海晓 2400.0,
'东阿阿胶股份有限公司': 企业名称 股东类别 股东名称 认缴出资额(万元)
0 东阿阿胶股份有限公司 个人 国家股 12108.1385
1 东阿阿胶股份有限公司 企业 社会公众股 28763.0164,
'乐山巨星农牧股份有限公司': 企业名称 股东类别 股东名称 认缴出资额(万元)
7 乐山巨星农牧股份有限公司 企业 四川乐山振静皮革制品有限公司 8866.0
8 乐山巨星农牧股份有限公司 个人 贺正刚 3471.0
9 乐山巨星农牧股份有限公司 企业 四川和邦投资集团有限公司 1663.0,
'金正大生态工程集团股份有限公司': 企业名称 股东类别 股东名称 认缴出资额(万元)
2 金正大生态工程集团股份有限公司 企业 雅戈尔投资有限公司 7500.0
3 金正大生态工程集团股份有限公司 企业 CRF化肥投资有限公司 7500.0
4 金正大生态工程集团股份有限公司 企业 临沂金正大投资控股有限公司 30672.0
5 金正大生态工程集团股份有限公司 企业 人民币普通股 10000.0
6 金正大生态工程集团股份有限公司 个人 万连步 14328.0,
'隆基绿能科技股份有限公司': 企业名称 股东类别 股东名称 认缴出资额(万元)
10 隆基绿能科技股份有限公司 个人 李振国等 377201.6757}
"""
根据输出可以看出,groupby() 就是根据by参数中的分组依据字段来将数据分为不同的组别,例如在上述操作中,我们按照企业名称字段进行分组,那么分组后每个组内的数据都是企业名称一样的数据。这就是分组的基本原理。
数据分组后,接下来就需要聚合操作。什么是聚合呢?在上一步中,我们已经对数据进行了分组,那么聚合操作就是对每一个小组内数据的某几个字段做计算,最后再将每个组内计算后的结果合并在一起。例如上一步我们已经根据企业名称进行了分组,那么当我们需要分析每个企业中所有股东的认缴出资额总和时,就可以使用“加总”的方式计算组内认缴出资额(万元)的总和,然后再将所有小组的加总结果合并在一起,返回最终的聚合结果,代码如下。
# 分组,对“认缴出资额(万元)”做加总聚合
Result = data.groupby(by='企业名称', as_index=False).sum() # .sum() 表示对所有可加总的字段做加总聚合
Result
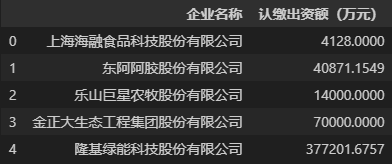
观察上述结果,可以发现聚合后认缴出资额(万元)中的值已经是每个分组内数值的和,而且已经按该列中数值的大小排好序,这是因为sort参数的生效。另外,在上述代码中我们主动设置了参数as_index=False,表示把分组依据字段设置为数据字段,而不是数据行索引,如果我们没有设置这个参数,那么将会得到下面的结果。
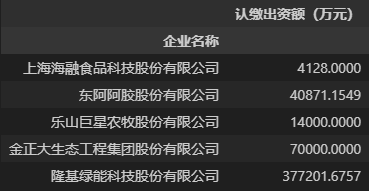
可以看到,当不设置as_index参数时,分组依据字段企业名称将会变为聚合结果的行索引,字符串“企业名称”就是索引的名称。
另外,可以发现聚合结果中只包含两个字段,这是因为分组依据(by参数)仅一个企业名称字段,且聚合时只有值为数字型的认缴出资额(万元)能够满足求和函数sum()的要求,所以聚合结果只包含这两列。当然这是在 pandas 1.5.3 版本下的结果,而 pandas 更新到 2.0.0 版本之后,分组聚合函数的工作原理有所优化,如果在 pandas 2.0.0 版本下运行上述代码,将会得到下面的结果。
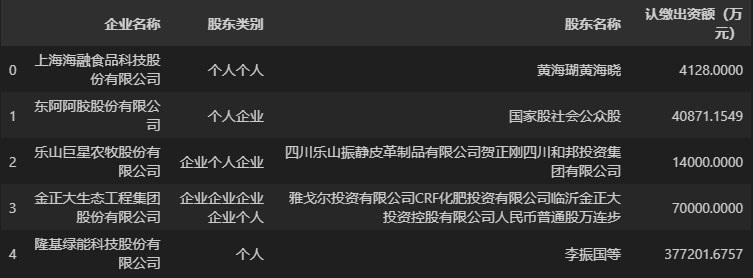
可以看到,pandas 2.0.0 中的求和函数sum()不仅会对存储数字类型的数据列进行加总,也会对值为字符型的数据列进行拼接。所以为了避免出现不必要的乌龙,我们可以使用功能更全面的聚合函数——agg()。agg()是分组器下的一个函数,可以自由地对分组内不同字段进行不同的聚合操作,下面我们演示一下如何使用agg()函数+匿名函数的方式来将同一企业内同一类型所有股东使用顿号(、)连接起来,代码如下。
# 根据“企业名称”和“股东类别”分组,对“股东名称”做字符连接,中间使用顿号隔开
Result = data.groupby(by=['企业名称', '股东类别'], as_index=False)\
.agg({'股东名称': lambda x : '、'.join(x)})
Result

上述代码中,groupby()函数中by=['企业名称', '股东类别']表示将会根据企业名称和股东类别这两个字段进行分组。agg()函数接受一个字典,字典中的“键”表示要进行聚合的字段的名称,字典中的“值”则表示该字段的聚合方式,常见的有求和('sum')、均值('mean')、方差('std')、最大值(max)、最小值(min)等,这些聚合方式大多适用于数值字段。如果这些计算方式无法满足需要,我们也可以使用自定义函数或匿名函数对组内待聚合的字段进行自由处理。例如在上述代码中就使用了一个匿名函数来将分组内字符型的数据拼合在一起,编写匿名函数时,我们可以把输入值x视作一个包含待聚合字段的一维 Series,事实上也是如此。
除此之外,agg()函数还可以同时对分组内的不同字段进行不同方式的聚合,且可以对一个字段实施多种聚合方式,例如下面的代码就是根据企业名称和股东类别进行分组,然后对认缴出资额(万元)字段做求和、求均值、求最大值这三种聚合,同时又对股东名称字段做拼合操作。
# 同时对多个字段进行不同方式的聚合操作
Result = data.groupby(by=['企业名称', '股东类别'], as_index=False)\
.agg({'认缴出资额(万元)': ['sum', 'mean', max],
'股东名称': lambda x : '、'.join(x)})
Result
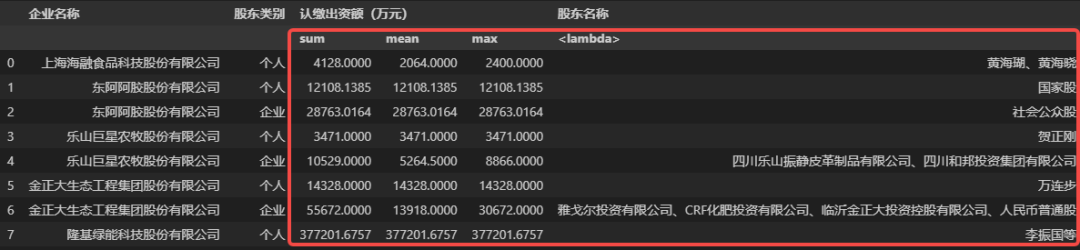
以上就是 Pandas 中分组聚合的基本使用方法。
Part4数据排序
Pandas 的内容已经写了不少了,但一直没有找到机会介绍一下 Pandas 中的数据排序,这一期就简单介绍一下如何使用 Pandas 对数据进行排序。
Pandas 中最常见的数据排序是df.sort_values(),它的功能是根据表中的数据值进行排序,它的基本语法和常用参数的用法及含义如下。
df.sort_values(by=IndexLabel,
axis=0,
ascending=True,
na_position='last',
inplace=False,
ignore_index=False)
| 参数名称 | 参数可选值 | 参数用法含义 |
|---|---|---|
| by | 单个字段名称 或 包含字段名称的列表 | 指定按照哪些列进行排序,可以是一个列名或者列名列表。如果不设置该参数,则默认按照所有列进行排序。 |
| axis | 0 或 1 | 指定按照哪个轴进行排序,默认值为 0,表示对数据行进行排序,较为常用;若设置为 1,则对数据列进行排序,可在转置后的数据中使用。 |
| ascending | True 或 False,排序字段不唯一时可传入包含True、False 的列表 | 指定是否按照升序排序,默认值为 True,表示按照升序排序。如果设置为 False,则表示降序排序。如果 by 参数包含了多个字段,那么可以设置该参数为包含True、False 的列表,例如当参数by=[A,B]时,可以设置ascending=[True,False],表示根据 A 列进行升序排序的基础上,再对 B 列进行降序排序。 |
| na_position | 'last' 或 'first' | 指定缺失值的位置,默认值为 'last',表示将缺失值放在最后,也可以设置为 'first' 表示将缺失值放在最前面。 |
| inplace | True 或 False | 指定是否在原 DataFrame 上进行操作,默认值为 False,表示不在原 DataFrame 上进行操作,返回一个排序后的新 DataFrame,如果设置为 True,则表示直接在原始的数据上(调用方)进行排序,同时不会返回任何值。 |
| ignore_index | True 或 False | 指定是否忽略索引,默认值为 False,表示保留原索引,也可以设置为 True 表示忽略原索引并重新生成新的连续索引。 |
数据排序是一个精细活,所以功能型参数有不少,但这些参数非常容易理解,使用起来也不会有太多麻烦。下面我们举例介绍如何进行数据排序。
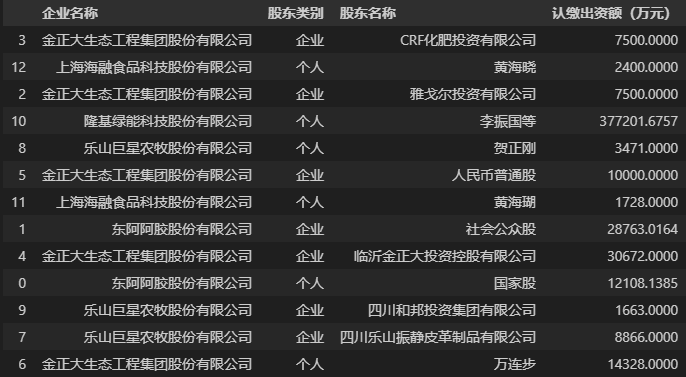
我们仍以上文中使用到的涉农上市公司数据为例,排序之前先使用df.sample()函数打乱数据的顺序,代码如下。
# 打乱数据(行)的顺序
unordered_data = data.sample(frac=1)
unordered_data # 查看乱序后的数据
下面我们对这个乱序的数据进行排序。如果我们希望排序后同一企业的数据行都在一起,且同一个企业的数据行按照认缴出资额降序排列,那么就可以使用下面的代码。
# 根据'企业名称'升序排序的基础上,再根据'认缴出资额(万元)'进行降序排序,排序后的结果赋给新变量 sorted_data
sorted_data = unordered_data.sort_values(by=['企业名称', '认缴出资额(万元)'],
ascending=[True, False])
sorted_data # 查看排序后的新数据

从排序结果中可以看出,在企业名称排序的基础上,又按照出资额的大小进行了降序排序。由于没有主动设置参数ignore_index=True,所以排序结果中的数据索引仍是原始的索引,如果后续需要进行数据选取,那么不连续的索引值将不利于选取操作。如果希望排序后的数据索引值是连续的,可以设置参数ignore_index=True或者在排序结果后面使用.reset_index(drop=True)来重置索引。以上就是 Pandas 中数据排序的基本使用方法。
Part5总结
分组聚合、排序都是数据处理中基本的技巧,分组聚合可以让扁平化的数据变得更加直观,减少数据的冗余;排序则可以让我们更加清晰地了解数据的规律,这些都是数据分析中必会的知识。
Part6Python 教程
目录
本期