基本操作
import pandas as pd
import numpy as np
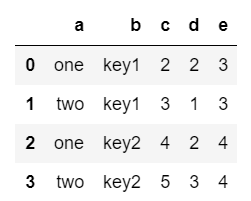
df = pd.DataFrame({'a':['one','two','one','two'],
'b':['key1', 'key1','key2','key2'],
'c':[2,3,4,5],
'd':[2,1,2,3],
'e':[3,3,4,4]})
df
# 对a进行分组,使用mean聚合函数,方法1
df.groupby('a').agg(['mean'])

# 对a进行分组,使用mean聚合函数,方法2
df[['c','d','e']].groupby(df['a']).agg(['mean'])

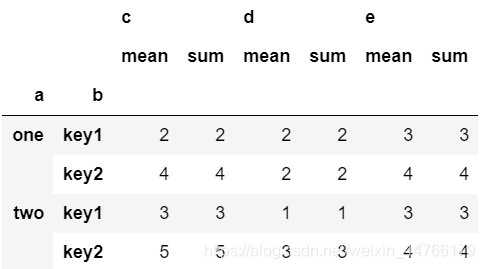
# 对a,b进行分组,使用mean,sum聚合函数
df.groupby(['a','b']).agg(['mean','sum'])
GroupBy对象支持迭代操作
grouped1 = df_obj.groupby('key1')
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
# 单层分组,根据key1
for group_name, group_data in g1:
print(group_name)
print(group_data)

# 多层分组,根据key1 和 key2
for group_name, group_data in g2:
print(group_name)
print(group_data)

GroupBy对象可以转换成列表或字典
# groupby对象转换为列表
d = list(g1)
print(d)

d[0][0] # 'one'
d[0][1]
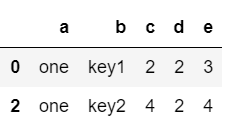
# groupby对象转换为字典
dic = dict(list(g1))
print(dic)

dic.keys() # dict_keys(['one', 'two'])
dic['one']

透视表
import pandas as pd
# 构造数据
df = pd.DataFrame({'A': np.random.randint(3, size=(5, )), 'B': ['a', 'b', 'a', 'c', 'b'], 'C': np.random.randint(4, size=(5, ))})
# 透视表
df1 = df.pivot(index='A', columns='B', values='C')
# 重置索引
df1.reset_index(inplace=True)
df1.columns.name=None
df

df1

