1.csv格式数据导入import pandas as pd
w=pd.read.csv("数据地址")
w.describe()
w.sort_values(by="列名")
2.excel格式数据导入`
mport pandas as pd
pd.read_excel("数据地址")
3.MySQL数据导入
import pandas as pdimport pymysql
dbconn=pymsql.connect(host="127.0.0.1",user="root",passwd="root",db="hexun")
sql="select * from myhexun"w=pd.read_sql(sql,conn)w.describe()
使用pandas操作Excel表单
部分参考自:pandas表单
1. 表单读取
import pandas as pd
#方法一:默认读取第一个表单
df=pd.read_excel('lemon.xlsx')#默认读取Excel的第一个表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
#方法二:通过指定表单名的方式来读取
df=pd.read_excel('lemon.xlsx',sheet_name='student')#可以通过sheet_name来指定读取的表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出
#方法三:通过表单索引来指定要访问的表单,0表示第一个表单
#也可以采用表单名和索引的双重方式来定位表单
#也可以同时定位多个表单,方式都罗列如下所示
df=pd.read_excel('lemon.xlsx',sheet_name=['python','student']) #可以通过表单名同时指定多个
df=pd.read_excel('lemon.xlsx',sheet_name=0) #可以通过表单索引来指定读取的表单
df=pd.read_excel('lemon.xlsx',sheet_name=['python',1]) #可以混合的方式来指定
df=pd.read_excel('lemon.xlsx',sheet_name=[1,2]) #可以通过索引 同时指定多个
data=df.values#获取所有的数据,注意这里不能用head()方法
print("获取到所有的值:\n{0}".format(data))
若出现下述情况:
ImportError: Install xlrd >= 0.9.0 for Excel support
解决方法:
安装xlrd的库,并import
2. pandas操作Excel的行列
loc和iloc以及ix的区别
loc可以使用文本标签,如loc[“name”];iloc使用序号,如iloc[1]。对于默认序号做行索引的情况,两者是通用的。
ix已经被depreciated在今后的版本中可能不再被使用。在pandas的官方文档中已经做出说明,推荐使用loc或iloc。
本段参考自:pandas中df.iloc函数应用
iloc:
示例:
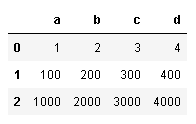
-
按行索引
(1)整数作为索引:df.iloc[n],默认查找第n行>>>df.iloc[0] #输出第0行,左边的‘abcd’为行头标志 a 1 b 2 c 3 d 4(2)列表作为索引:只查找列表中数字对应行号的数据
df.iloc[[0,2]]#只输出第0行与第二行数据(3)列表作为索引:切片作为索引:实现多行数据查找
df.iloc[:2]#选择前两行数据(4)表达式作为索引:
df.iloc[lambda x: x.index % 2 == 0]#选择偶数行
2、同时规定行和列进行索引,与只按行索引类似
df.iloc[0, 1]#选择行号=0,列号=1的数据
df.iloc[[0, 2], [1, 3]]#选择行号为0和2,列号为1和3的数据
df.iloc[1:3, 0:3]#选择行号为1-2,列号为0-2的数据,注意切片范围为左闭右开
df.iloc[:, [True, False, True, False]]#行号全选,选择第1列和第3列数据
df.iloc[:, lambda df: [0, 2]]#选择dataframe的第1列与第3列