1.声明
当前的内容用于本人复习使用,主要是针对Pandas读取数据出现NaN值时的处理,以及读取的时候产生?或者其他值的处理,还有分组和统计。
2.处理NaN值
在读取数据的时候可能出现某个值缺失,这个时候Pandas默认使用NaN代替缺失值!
准备具有确实值的数据:

import pandas as pd
import numpy as np
pd_dataFrame = pd.read_csv("test.csv",index_col=0)
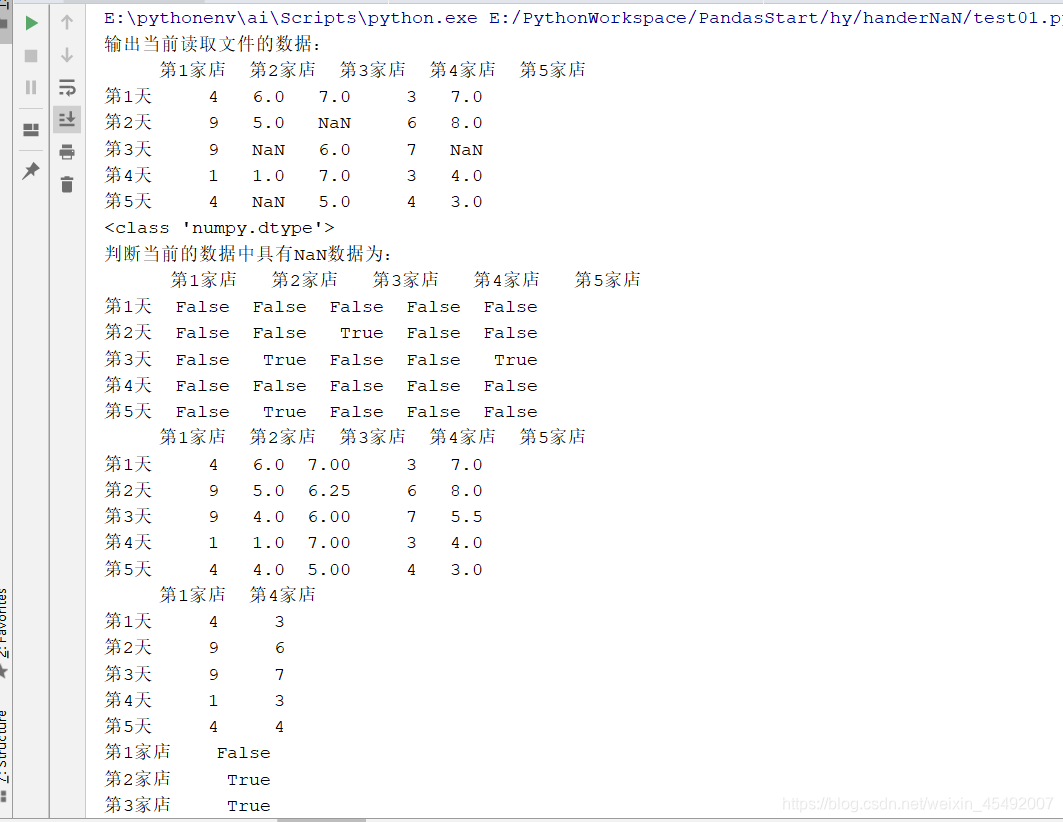
print("输出当前读取文件的数据:\n{}".format(pd_dataFrame))
print(type(pd_dataFrame.values.dtype))
# 从数据中可以看出当前的数据中存在许多NaN值
# 现在开始处理NaN值
print("判断当前的数据中具有NaN数据为:\n{}".format(pd_dataFrame.isna()))
# 或者使用isnull()
# print("判断当前的数据中具有NaN数据为:\n{}".format(pd_dataFrame.isnull()))
# 或者使用pd.isna()或者pd.isnull()
# print(pd.isnull(pd_dataFrame))
# print(pd.isna(pd_dataFrame))
# 处理NaN值,pd.mean()就是获取这列的平均值,inplace就表示是否操作当前的数据,对原来的数据进行修改
replace_dataFrame = pd_dataFrame.fillna(pd_dataFrame.mean(),inplace=False)
print(replace_dataFrame)
# 使用删除NaN值的方式处理数据,默认删除的就是行的数据,如果包含NaN就直接删除这一行数据,可以指定当前的axis
# drop_dataFrame = pd_dataFrame.dropna(inplace=False)
drop_dataFrame = pd_dataFrame.dropna(axis=1,inplace=False)
print(drop_dataFrame)
# 直观方式看出当前的数据是否包含NaN
print(pd_dataFrame.isnull().any())
print(pd_dataFrame.notnull())
# 当前的数据的结果显示的数据为:每一列中是否包含NaN,如果包含就显示True,否者显示False
结果:
总结:
1.首先需要判断当前的数据是否存在NaN数据
- 可以
使用pd.isnull()或者pd.notnull(),或者pd.isna()
2.在处理NaN值的时候可以使用删除方法,就是将NaN的那一行或者那一列删掉,可以使用pd.dropna(),这个时候可以指定axis表示删除的方式,还有inplace表示是否操作原表
3.可以使用填补数据的方式,将原来的NaN填充其他数据,pd.fillna()
3.处理特殊字符(?号或者其他)
就是Pandas读取文件的时候读出了特殊的字符,不是NaN的时候
# 为当前的?号类型的数据设置一个默认值,就是处理?号值
# 首先将原来的?号所在的值设置为NaN,然后直接将这些数据按照NaN的处理方式来处理
# 1.替换?号值,设置为NaN
import numpy as np
import pandas as pd
# 首先使用一个模拟的并读取数据为:?,就是读取文件后出现了?号的数据
has_undifind_file = "?_file.cvs"
read_file =pd.read_csv(has_undifind_file)
replace_pd = read_file.replace(to_replace="?",value=np.nan)
# 按照NaN的方式处理数据
default_value = 1
handler_result = replace_pd.fillna(default_value,inplace=False)
1.我们可以先将原来的特殊字符使用替换的方式替换成NaN,需要使用pd.replace(),需要指定替换的字符to_place和替换的字符或者值value
2.然后按照上面对NaN的数据处理即可
4.分组操作和聚合
# 使用分组和聚合操作,当前的分组和聚合都是在pandas来实现的
import pandas as pd
students = [["101", "张三", 80, 70, 100],
["101", "李四", 70, 70, 50],
["101", "王五", 60, 50, 70],
["102", "赵六", 90, 70, 80],
["102", "老七", 55, 49, 88],
["102", "赵六", 90, 70, 80],
["103", "老七", 55, 49, 88],
["104", "赵六", 90, 70, 80],
["105", "老七", 55, 49, 88],
]
pd_students = pd.DataFrame(students, columns=["class", "name", "语文", "数学", "英语"])
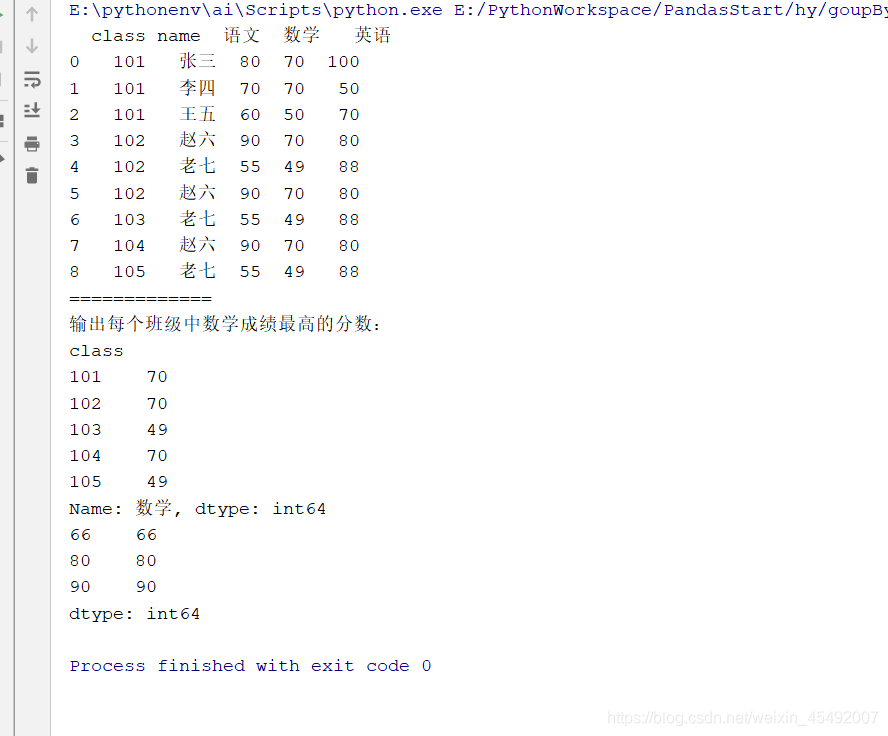
print(pd_students)
print("=============")
print("输出每个班级中数学成绩最高的分数:\n{}".format(pd_students.groupby("class")["数学"].max()))
# 使用series方式实现分组以及当前的聚合操作
math = [80, 90, 66]
pd_series = pd.Series(math, index=["语文", "数学", "英语"])
print(pd_series.groupby(pd_series).max())
结果:
总结:
1.分组使用pd.groupby(),需要指定按照什么分组
2.实现统计的时候需要在当前的groupby的方法之后才能调用count之类的,类似于数据库的分组和聚合操作
5.总结
1.在处理NaN值的时候,需要先判断,然后使用填充数据或者删除数据的方式
2.在处理特殊值的时候,可以使用pd.replace()方法将其转换成其他的值或者直接替换成NaN,然后按照NaN来处理
3.分组聚合就是类似数据库的分组聚合操作
以上纯属个人见解,如有问题请联系本人!
