前言
数据聚合于分组操作在众多的关系型或非关系型库中都有涉及,大体原理都是类似,根据某个或者多个业务字段将获取到的数据进行聚合操作或者分组操作,pandas提供了非常友好的分组聚合功能,可以方便使用人员对数据进行不同维度的聚合分组操作
API简要说明
构造一个DataFrame的数据
import numpy as np
import pandas as pd
df=pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
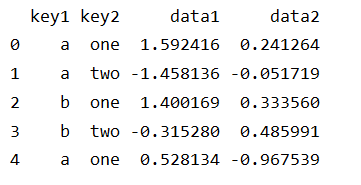
print(df)
展示结果
1、对某个字段进行分组
#通过key1分组
grouped = df.groupby(by='key1')
print(grouped)
print(type(grouped))
for i in grouped:
print(i)
print("-"*50)
显示结果
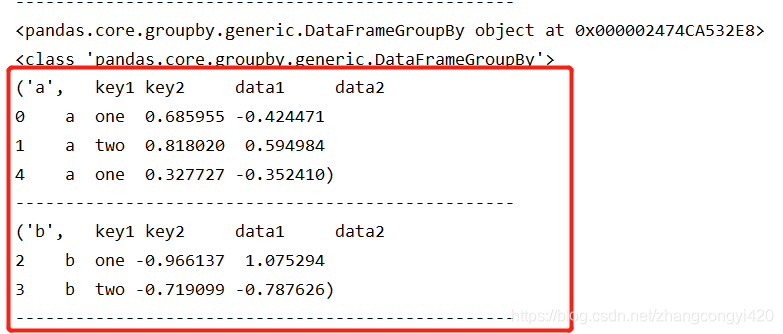
根据字段分组后,得到一个group的对象,这个分组对象,pandas提供了一系列的操作方法(函数),可以直接拿来使用,比兔mean求平均值 ,count进行统计等
通过继续遍历group对象,可以发现group的每个值又是一个元祖,名称为分组名称,值为某一行的值,拿到了group可以进行多种操作
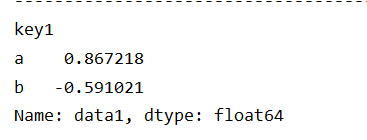
求某一列的平均值
#求data1平均值
mean_data1 = grouped['data1'].mean()
print(mean_data1)
2、对多个字段进行分组
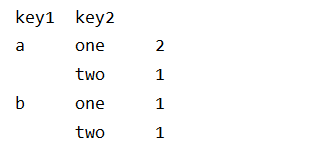
#获取多个分组,并计算平均值
multi_group = df.groupby(by=[df['key1'],df['key2']])['data1'].count()
print(multi_group)
或者写成下面这样也可以
multi_group = df.groupby(by=['key1','key2'])['data1'].count()
print(multi_group)
很好理解,多个分组的情况,一般来说,都是从大的维度往小的维度划分,不管组别的层级分成多少,最后的那一层的数据还是完整的行和列的数据,然后依次层层往下下取数据即可,比如上述,先按照key1和key2分组,然后从分组的数据中获取data1的那一列进行统计
当然,最终去到的待统计的那一列可以写在前面,也可以放在后面,因此下面这样写也是可以的
multi_group_names = df['data1'].groupby(by=[df['key1'],df['key2']]).count()
print(multi_group_names)

要点说明:
在上述的分组操作最终获取到的分组对象时候,其实我们得到是series的类型,当然也可以得到DataFrame类型,得到的分组对象类型不同,对于分组对象的函数操作也会有所不同,比如通过下面这种方式,可以获取到DataFrame类型的结果
multi_group_names = df[['data1']].groupby(by=[df['key1'],df['key2']]).count()
print(type(multi_group_names))
print(multi_group_names)

数据聚合
对于聚合,指的是任何能够从数组产生标量值的数据转换过程。例如:mean,count,min以及sum等。许多常见的聚合运算都有就地计算数据集统计信息的优化实现,然而,并不是只能使用这些方法。可以自己定义聚合运算,还可以调用分组对象上已经定义好的任何方法。例如,quantile可以计算Series或DataFrame列的样本分位数
1、算出按key1分组后的data1的分位数(0.9)的值
grouped=df.groupby('key1')
print(grouped) #返回groupby对象
print(grouped['data1'].quantile(0.9))

2、自定义的聚合函数,只需将其传入aggregate或agg方法即可
grouped=df.groupby('key1')
#自定义函数
def peak_to_peak(arr):
return arr.max()-arr.min()
print(grouped.agg(peak_to_peak))
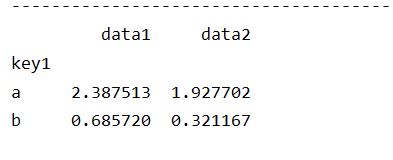
注意:自定义函数要比那些经过优化的函数慢,这是因为在构造中间分组数据块时存在非常大的开销(函数调用/数据重排等),因此慎用,但是它在一些特殊的业务场景中非常有效
案例讲解
下面使用一个2019年全国高校的excel数据表进行相关的使用分析,截取的部分数据如图
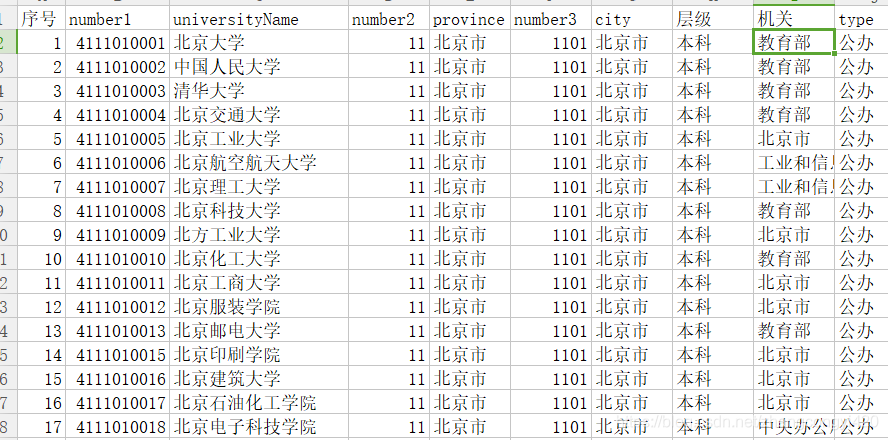
这张表列举了2019年全国不同的省份,每个省份不同的城市中的大学、大学等级等字段信息,下面通过几个简单的需求进行讲述
1、统计各个省的高校数量
iopath = './全国高校名单excel版(2019).xlsx'
df = pd.read_excel(iopath,sheet_name='全国高校')
#统计各个身份的大学,首先根据省进行分组,得到分组的对象
#得到的分组对象是一个元祖,由于元祖是可迭代的对象,一个是分组名称,一个是dataFrame对象,
# 然后就可以使用分组相关的函数进行后续操作了
grouped = df.groupby(by="province")
print(grouped['universityName'].count())
2、统计河北省的高校数量
group_count = df.groupby(by="province")['universityName'].count()['河北省']
print(group_count)
3、统计某个省份的大学数量
hebei_data = df[df['province'] == '河北省']
print(hebei_data['universityName'].count())
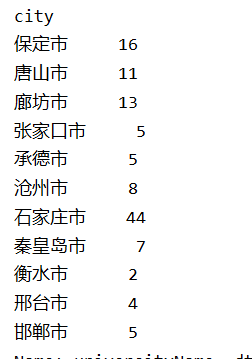
4、河北省下面各个市的大学数量
hebei_data = df[df['province'] == '河北省']
city_grouped = hebei_data.groupby(by='city')
print(city_grouped.count()['universityName'])
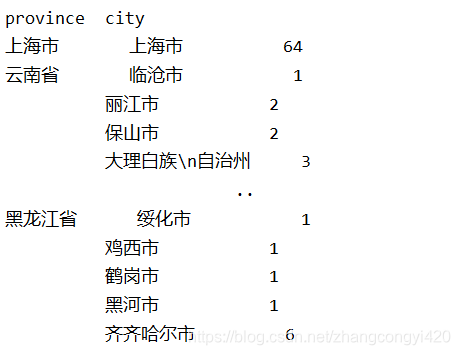
5、多字段分组,统计各个省,每个省下面的大学数量
multi_group = df.groupby(by=['province','city'])['universityName'].count()
print(multi_group)
上文提到了按照多字段的分组,因此也可以写成下面这样
multi_group_names = df['universityName'].groupby(by=[df['province'],df['city']]).count()
print(multi_group_names)
绘图
分析并进行数据统计后,一般需要对结果进行绘图展示,下面通过上文中获取到的全国不同的省份的高校数量,以及获取河北省的高校数量进行图形展示
1、全国不同的省份的高校数量图
import pandas as pd
from matplotlib import pyplot as plt
iopath = './全国高校名单excel版(2019).xlsx'
df = pd.read_excel(iopath,sheet_name='全国高校')
print(df.head(2))
#避免中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#呈现出全国省份排名前10的高校数量
grouped = df.groupby(by='province').count()['universityName'].sort_values(ascending=False)[:10]
print(grouped)
_x = grouped.index
_y = grouped.values
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()
展示效果图
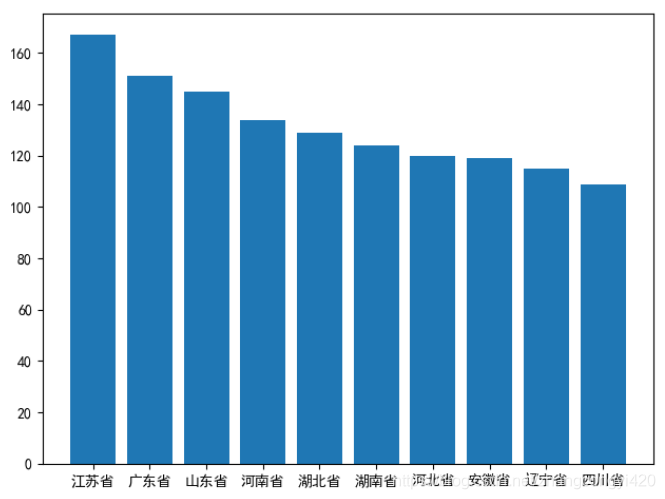
2、河北省不同地区高校数量图
#展示出河北省的每个城市的高校数量
df = df[df['province']=='河北省']
grouped = df.groupby(by='city').count()['universityName'].sort_values(ascending=False)
# 设置中文显示字体,避免乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
print(grouped)
_x = grouped.index
_y = grouped.values
plt.bar(range(len(_x)),_y,width=0.3,color='orange')
plt.xticks(range(len(_x)),_x)
plt.show()
绘制的图形的细节部分可以继续完善,此处不再做过多讲述
本篇到此就基本结束了,重点对分组的常用操作做了简单的说明,而聚合操作也是pandas的非常重要的内容,后续有空会继续做深入研究,最后,感谢观看!
