ViT(Vision Transformer ): 2021年,CV 最有影响力的工作
- 推翻了 2012 Alexnet 提出的 CNN 在 CV 的统治地位
- 有足够多的预训练数据,NLP 的 Transformer 搬运到 CV,效果很好
- 打破 CV 和 NLP 的壁垒,给 CV、多模态 挖坑
标题
An image is worth 16*16 words
每一个方格都是 16 * 16 大小,图片有很多 16 * 16 方格 patches --> an image is worth 16 * 16 words
Transformers for image recognition at scale
transformer 去做大规模的图像识别
摘要
- Transformer 架构已成为自然语言处理任务事实上的标准,但其在计算机视觉中的应用仍然有限。
- 在视觉中,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
- 我们证明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer 可以在图像分类任务上表现良好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与现有技术相比取得了优异的结果艺术卷积网络,同时需要更少的计算资源来训练
ViT fewer computational resources to train, really?
少的训练资源 == TPUv 3 + 2500 天。 “fewer” 相对来说
引言
self-attention 架构, esp Transformers,是 NLP 必选模型。主流方式是 BERT 提出的,大规模数据集预训练,在 特定领域的小数据集 做微调。 Transformer 的 计算高效和可扩展性,1000亿参数都还没有 性能饱和 的现象。

那个时代的解决方法:


当在没有强正则化的情况下在 ImageNet 等中型数据集上进行训练时,这些模型的准确度比同等大小的 ResNet 低几个百分点。这种看似令人沮丧的结果是可以预料到的:Transformers 缺乏 CNN 固有的一些归纳偏差,例如平移等方差和局部性,因此在数据量不足的情况下训练时不能很好地概括。
Transformers缺乏CNN的归纳偏置:
-
Translation Equivariance(平移等变性):这是指CNNs(卷积神经网络)天生具有的一种偏置。当图像中的物体在图像中平移时,CNNs能够捕捉到这种平移的特征。 这是因为CNNs使用卷积操作来提取特征,卷积核在图像上滑动并检测不同位置的特征,从而使得模型具有平移不变性,即无论物体在图像中的位置如何,模型都能够识别它。
-
Locality(局部性):CNNs天生关注输入数据的局部区域。卷积操作只考虑输入数据的小块区域,这与自然图像数据的局部性质相吻合。这种局部性使CNNs更适合处理图像,因为在图像中,物体通常由局部特征组成。
Transformers不具备这些偏置:
-
Transformers 是一种用于处理序列数据的神经网络架构,最初被设计用于自然语言处理(NLP)。相对于CNNs,它们没有天生的平移等变性。在序列数据中,平移操作通常没有明显的含义,因此Transformers没有这种偏置。
-
Transformers 不具备局部性偏置,因为它们的自注意力机制允许模型同时考虑输入序列中的所有位置,而不是局部区域。这对于处理语言等序列数据非常有用,但在图像等需要关注局部信息的任务中,可能不如CNNs那么适用。
因此,文中提到,当在中等规模数据集上训练Transformers模型时,如果没有足够强的正则化(例如Dropout、权重衰减等),它们的性能可能会略低于具有相似规模的ResNets(卷积神经网络)。这部分原因可以归结为Transformers在处理图像等数据时缺乏CNNs天生具备的平移等变性和局部性偏置,这些偏置有助于CNNs更好地泛化到图像数据。
结论

相关工作
Transformer 在 NLP 领域的应用:BERT, GPT
Transformer 先在大规模语料库上做预训练,再根据具体的任务数据集进行微调。
BERT: denosing mask挖词、完形填空,把masked的词预测出来
GPT: language modelling, 预测下一个词 next word prediction
完形填空 or 预测下一个词,人为设定。语料句子是完整的,去掉某些词(完形填空) or 最后词(预测下一个词) --> 自监督的训练方式。
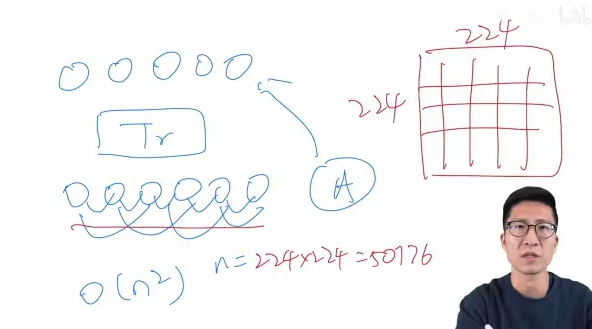
self-attention 在视觉领域的应用:
self-attention to each pixel:对每个像素点做自注意力❌
224 * 224 image: O(n^2 = 50176)(1k, 4k image: 维度爆炸)
self-attention to each image with approximations:
不用整张图,只用 local neighborhoods,降低序列长度
sparse transformer: 全局注意力的近似、只对 稀疏的点 做注意力
scale attention by applying attention in blocks of varying size
把自注意力用到不同大小的 blocks,in the extreme case only along individual axes 极端情况,只关心轴, axial self-attention,横轴 + 纵轴。
小结:以上 self-attention + CV 效果不错,但工程实现加速很难。可在 cpu gpu跑,但大规模训练不行。

ViT模型
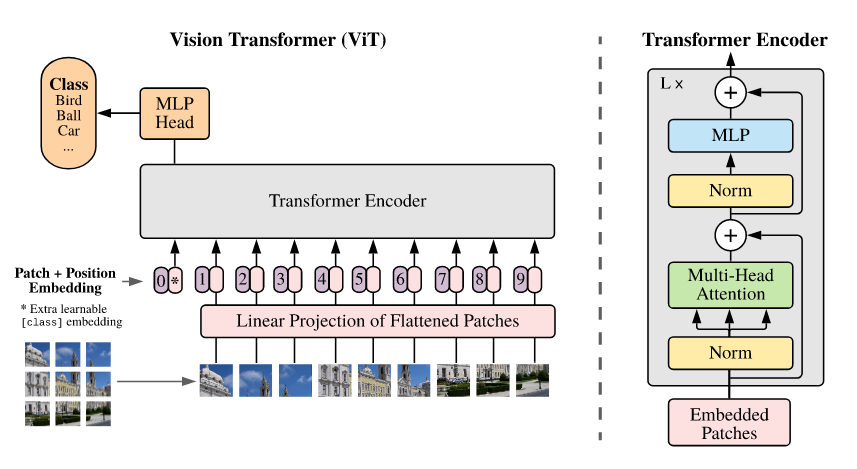




编码器的输入是:197*768
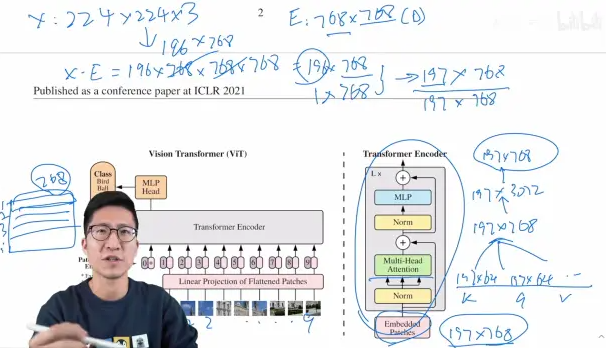
ViT base: 12 heads
MLP:放大 4 倍,再缩小到原维度大小
Transfomer encoder 输入输出维度一致,可以直接叠加 L 个
D.3 Head type and class token 作者的消融实验
ViT 除了标准的 transformer,关键部分是 怎么对图片进行预处理 和 怎么对图片最后的输出进行后处理。
CLS token + MLP (tanh acitvation) == 分类
CV 通常的 全局特征:i.e., Res50。feature map (14 * 14) --> GAP globally average-pooling 全局平均池化 --> a flatten vector 全局的图片特征向量 --> MLP 分类。类似的,Transformer 的 输出元素 + GAP 可以用做全局信息 + 分类吗? Ok.
CV 的 CLS GAP 和 NLP 的 CLS 效果差异不大。CLS-Token 和 GAP 的 适用参数 不一样。


ViT的前向传播过程: E是Linear Projection of Flattened Patches,包括LayerNormal和残差。

归纳偏置和混合模型:

实验
对比 ResNet, ViT, Hybrid ViT (CNN 特征图,不是图片直接 patch 化) 的 representation learning capabilities 表征学习能力。
为了了解每个模型预训练好 到底需要多少数据,在不同大小的数据集上预训练,然后在很多 benchmark tasks 做测试。
考虑模型预训练的计算成本时,ViT performs very favourably 表现很好, SOTA + fewer resource 训练时间更少
ViT 的自监督训练,可行,效果也还不错,有潜力;一年之后,MAE 用自监督训练 ViT 效果很好。
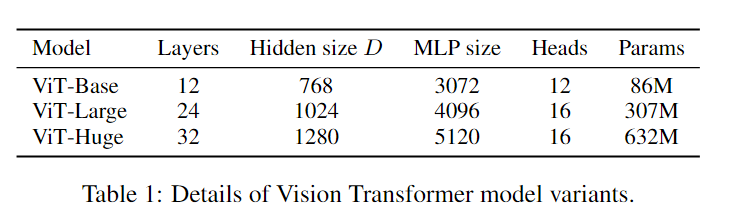 ViT Base, Large, Huge
ViT Base, Large, Huge
Layers, Hidden size D, MLP size, Heads 相应增加。模型变体 = (Base, Large, Hugh) + (patch size 表示)
ViT-L/16 使用 Large 参数 和 patch 16 * 16 输入。
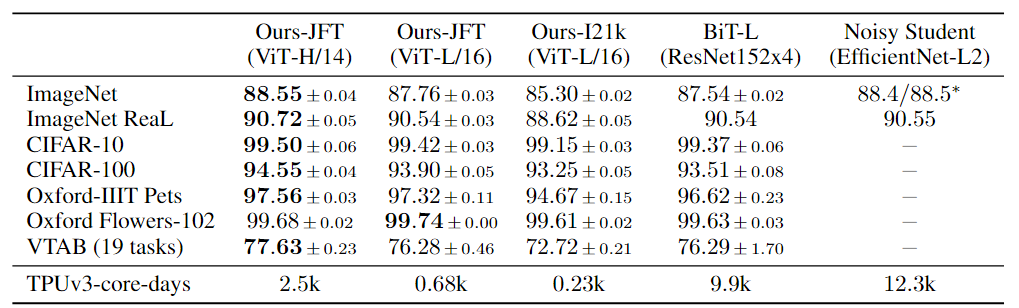
ViT-H/14 训练比 ViT-H/16 贵,效果和 BiT-L 差不多,优势不明显。怎么突出 ViT 的好呢?
**ViT 训练更便宜。**TPUv3 天数:ViT-H/14 2.5K, BiT-L 9.9K, Noisy Student 12.3K
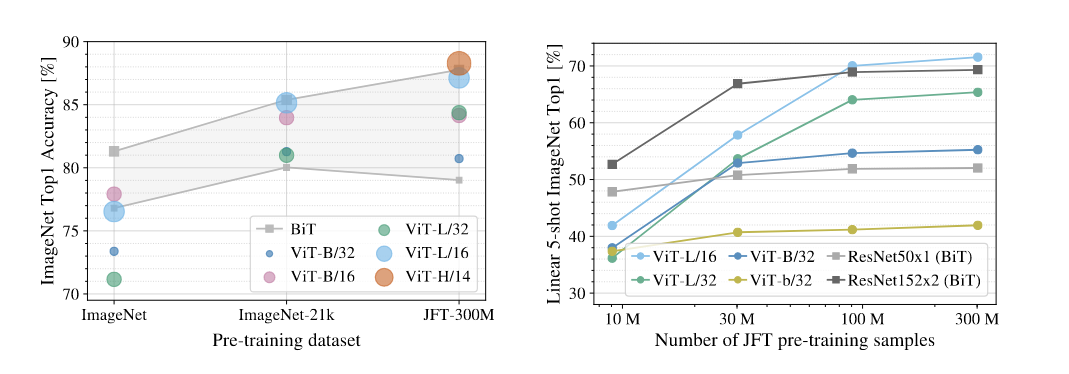
如果想用 ViT,至少需要 ImageNet-21K 14M 大小的数据集
小于整个数据量,CNN 更合适,更好的利用 inductive bias,ViT 没有特别多 inductive bias 需要更多数据训练。
数据集规模比 ImageNet-21K 更大时,Vision Transformer 效果更好,因为可扩展性 scaling 更好。
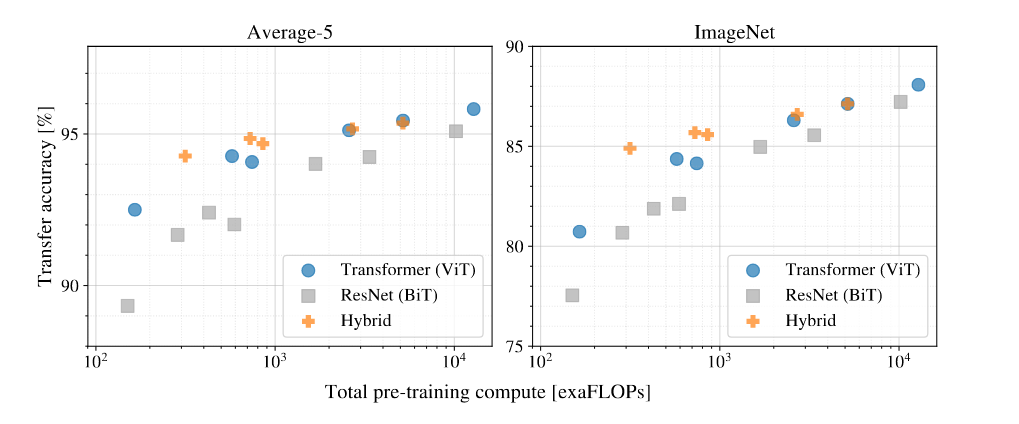
Q: Hybrid 模型,CNN 抽取出来的特征,能不能帮助 Transformer 更好的学习呢?
小模型,Hybrid 模型吸收 CNN 和 Transformer 的优点,效果好。不需要很多的数据预训练,达到 Transformer 的效果
大模型,Hybrid 模型 和 Transformer 差不多,甚至不如 Transformer 模型。Why?
如何 预处理图像,如何做 tokenization 很重要,后续论文有研究


提出问题:如何用 自监督 的方式 训练一个 vision transformer?
评论

