Very Deep Convolutional Networks for Large-Scale Image Recognition
一、摘要
本文主要是使用非常小的(3X3)的卷积滤波器架构对网络深度的增加进行全面的评估。
二、网络结构
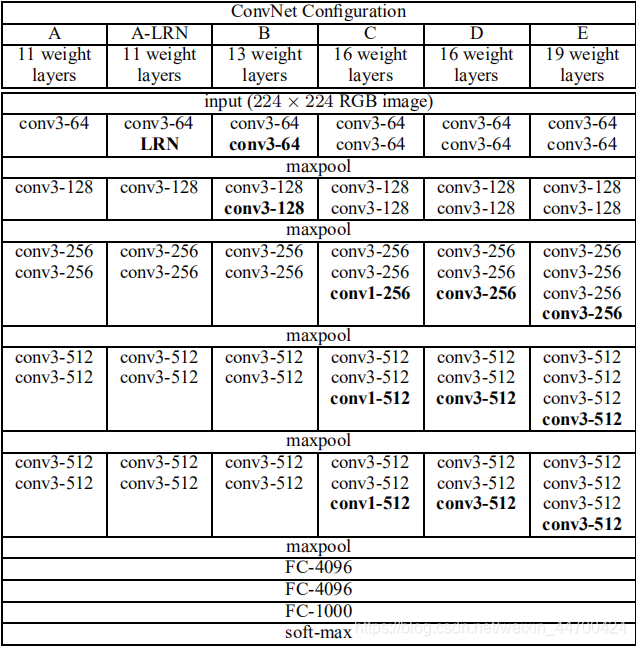
图像的预处理是减去均值固定大小为224x224。3X3卷积层的填充是1、步长也是1。MAXPOOL窗口是2、步长也是2,初始通道数为64,在通道没有达到512之前,每池化一次通道数都会增加一倍。激活函数是ReLU。虽然LRN(Local Response Normalisation)在AlexNet对最终结果起到了作用,但在VGG网络中没有效果,并且该操作会增加内存和计算,从而作者在更深的网络结构中,没有使用该操作。
使用堆叠的3x3卷积核代替5x5和7x7的卷积核,在感受野相同的情况下(1)增加了非线性的激活函数使得决策函数更有辨别力。(2)减少了参数量,3个3X3的参数量是3x3x3C方明显小于7X7卷积核的49C方。
1X1卷积核在没有影响感受野的情况下增强了决策函数的非线性,因为卷积层的激活函数是非线性的。
三、分类框架
1、训练
使用带momentum的mini-batch gradient descent代替multinomial logistic regression objective优化参数。训练参数:batch size:256、momentum:0.9、学习率为0.01(训练过程中下降三次,每次乘以0.1)最大迭代次数是370K迭代(74epochs)。权重正则化、全连层使用dropout正则化大小为0.5。虽然模型的参数和深度相比AlexNet有了很大的增加,但是模型的训练迭代次数却要求更少,这是因为:a)正则化+小卷积核,b)特定层的预初始化 。
参数初始化:随机初始化浅层网络结构A,然后利用训练好的A的参数给其他模型初始化(初始化前4层卷积+全连接层,其他的层采用正态分布随机初始化,mean=0,var=10−210−2, biases = 0),最后证明使用全部随机初始化,模型也可以训练的更好。
训练输入:采用随机裁剪的方式,获取固定大小224x224的输入图像。并且采用了随机水平镜像和随机平移图像通道来丰富数据。
训练数据大小:令S为图像的最小边,如果最小边S=224,则直接在图像上进行224x224区域随机裁剪,这时相当于裁剪后的图像能够几乎覆盖全部的图像信息;如果最小S>224,那么做完224x224区域随机裁剪后,每张裁剪图,只能覆盖原图的一小部分内容。注:因为训练数据的输入为224x224,从而图像的最小边S,不应该小于224 。
两种训练数据的生层方式:(1)固定S的大小,在S=224和S=384的尺度下,对图像进行224x224区域随机裁剪。(这是单尺度训练,但是采样crops图像的内容,仍然表示多尺度的图像数据)(2)令S随机的在[Smin,Smax]区间内值,放缩完图像后,再进行随机裁剪(其中Smin=256,Smax=512),这是多尺度训练,可以看作是使用尺度抖动对训练集数据的增强。为了训练时间,多尺度模型可以使用训练好的单尺度模型进行微调。
2、测试
设Q为测试图像的大小。两种预测方式:(1)密集性,将最后的三个全连层的第一层换成7x7的卷积层将最后两层换成1x1的卷积层,卷积层的参数还是用训练好的模型的全连层的参数。然后将全卷积网络应用在未裁剪的图像上得到一个类得分映射,并具有依赖于输入图像大小的可变空间分辨率,分类数等于最后卷积层的通道数。为了得到图像的类分数的固定大小向量,对类分数映射进行平均池化。增加了测试集的水平翻转图像;对原始图像和翻转图像的软最大值类后验进行平均,得到图像的最终得分。将最后的全连层是转换成1*1卷积的好处:参数总量不变,计算负担也相对减少,又消除输入的限制。(2)对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结果,最终对所有结果平均。
multi-crops相当于对于dense evaluatio的补充,原因在于,两者在边界的处理方式不同:multi-crop相当于padding补充0值,而dense evaluation相当于padding补充了相邻的像素值,并且增大了感受野。
四、分类实验
measures评估指标:top1 error (错误预测占比,预测错误图片/总的图片),top5 error(正确class超出前5预测class范围的占比,正确预测超过前5分数的总数/总数)
1、单尺度评估(从测试角度)
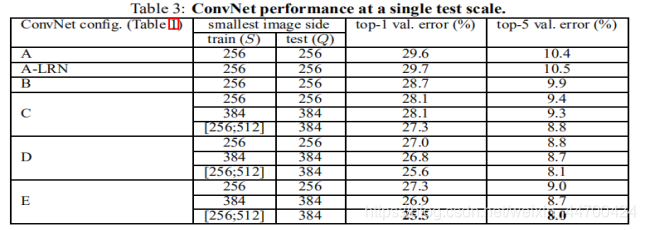
结论:(1)模型E(VGG19)的效果最好,即网络越深,效果越好。(2)同一种模型,随机scale jittering的效果好于固定S大小的256,384两种尺度,即scale jittering数据增强能更准确的提取图像多尺度信息 。
2、多尺度评估(从测试角度)
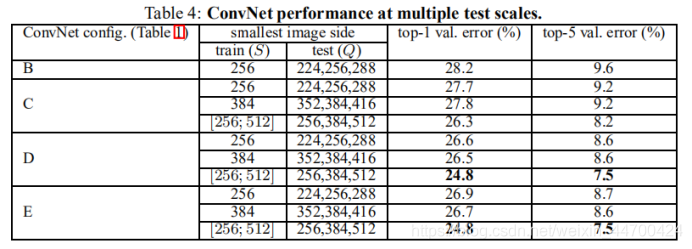
结论:对比单尺度预测,多尺度综合预测,能够提升预测的精度。同单尺度预测,多尺度预测也证明了scale jittering的作用。
3、多尺度裁剪评估
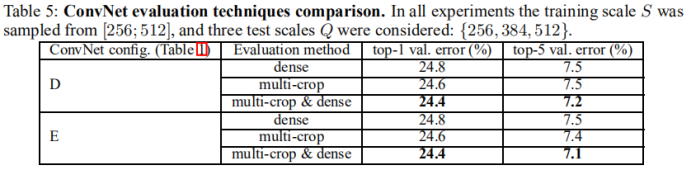
结论:使用多种剪裁表现要略好于密集评估,并且这两种方法确实是互补的,因为它们的结合优于他们中的每一种。如上所述,我们假设这是由于卷积边界条件的不同处理造成的。
4、ConvNet融合
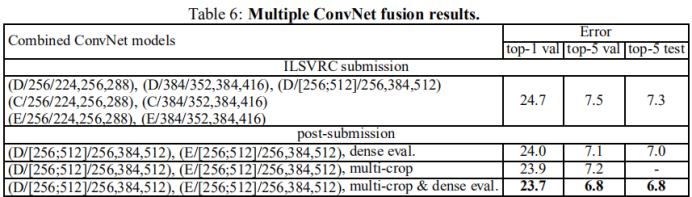
通过多种模型融合输出最终的预测结果,能达到the state-of-the-art的效果。
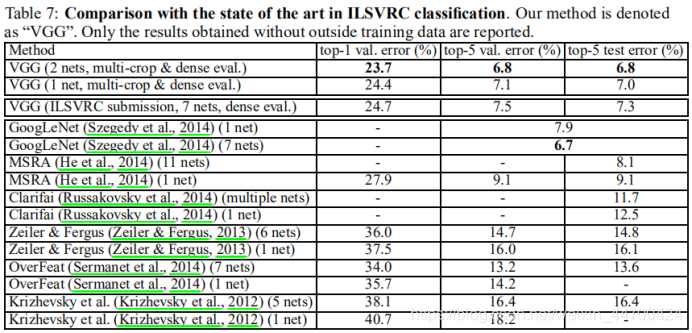
5、与现有技术作比较。
五、结论
证明了深度有益于分类准确度,结果再次证实了在视觉表示中深度的重要性。
六、附录A(定位)
1、定位网络
包围框由一个四维向量表示,它存储它的中心坐标、宽度和高度。两种分类方法:SCR(single-classregression),用一个回归函数来学习预测所有类别的bounding box;PCR(per-class regression)每个类别有自己单独的一个回归函数。
(1)训练
使用Euclidean loss代替逻辑回归函数。Euclidean loss惩罚预测的包围框参数与地面真相的偏差。使用训练好的相一致的分类模型初始化,只有最后一层全连层是从零开始训练前面层都是微调初始化参数。学习率设置为0.001。
(2)测试
两种测试方法:第一种:定位网络只应用在图像的裁剪中心,用于比较不同的网络修改下性能。第二种:利用OverFeat的贪婪融合过程(不使用offset pooling),在整个图像上密集应用定位网络;首先根据softmax分类结果给定bounding box的置信得分,然后融合空间相似的bounding box,最后选取最大置信得分的bounding box。
2、定位结果
(1)设置比较
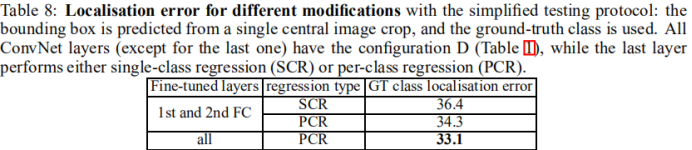
结论:PCR优于SCR。微调所有全连层优于只微调前面两个全连层。
(2)全场景评估
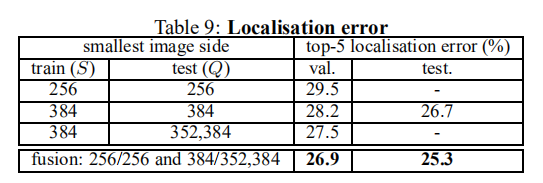
结论:整图像预测优于中心裁剪。多尺度网络融合预测最好,多尺度测试比单尺度测试好。
3、与先进网络比较

[1]: https://blog.csdn.net/qq_37791134/article/details/83474310
[2]: https://blog.csdn.net/wy23333/article/details/80258853
[3]: https://blog.csdn.net/whiteinblue/article/details/43560491
[4]: https://blog.csdn.net/C_chuxin/article/details/82833028
Very Deep Convolutional Networks for Large-Scale Image Recognition(VGG)笔记

猜你喜欢
转载自blog.csdn.net/weixin_44700424/article/details/104292338
今日推荐
周排行