最近看transformer用于CV比较热门,特意去进行了解,这里用分类的一篇文章进行讲解。
NLP中的transformer和代码讲解参考我另一篇文章。
论文链接:AN IMAGE IS WORTH 16X16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
一.思想
其实核心问题就是考虑如何把图像数据H*W*C,序列化成一个一个词那种结构,自然就想到将图片crop成一个一个patch,假设有N个patch,维度为p*p*C,reshape加concate一下就变成个N*p^2C,也就类似词向量。
二.模型结构
如下图所示:
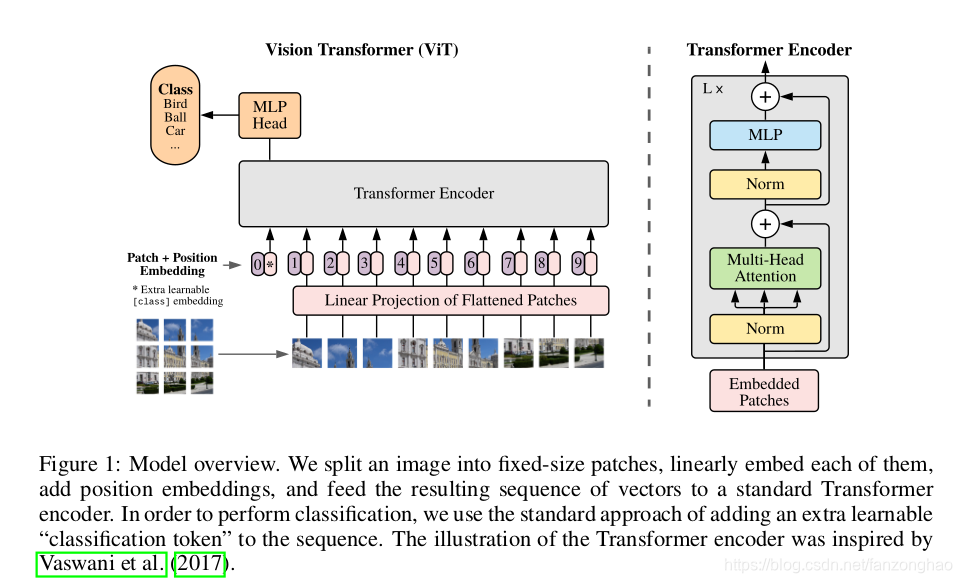
1.图像转序列
将图片H*W*C,crop成N个patch,然后在转换成N*(p^2C),同时为了避免模型结构受到patch size的影响,采用Linear project将不同flatten patchs转换成D维向量。这样的话输入图片数据就成了N*D二维矩阵就和词向量矩阵对应上了。

2.Position embeddings
作者用一个可学习的embedding向量去将图像位置信息加入到序列中。

3.learnable embedding
上图中,带*号的粉色框是一个可学习的embedding,记住Xclass,经过encoder后的结果作为整张图像的表示。之所以不用其中一个patch的embedding是因为,这种embedding不可避免带有path的信息,而新增的这个没有语义信息,能更佳反映整张图片。

4.输入transformer encoder
进行特征提取,我另一篇文章已经很详细了,这里就不赘述了。
整个公式如下:

三.实验结果:
在中等数据集(例如ImageNet),效果不如resnet,但是在大规模数据集上,表现更佳。

