版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lhanchao/article/details/60874649
先发发牢骚,最近的日子就是“准备数据集——想改进方法——跑实验——实验结果不好”的循环,熬得一点心情都没有了= =
好了,废话不多说了,这篇VGGNet的论文是两三周之前看的了,而且最近撘的网络结构跟VGGNet很相像,就拿出来复习一下吧。
这篇论文是牛津大学的几个人做出来,在ILSVRC 2014中的classification项目的比赛中取得了第2名的成绩(没错,第一就是上一篇博客中介绍的GooLeNet),但是实际上这里提出的VGGNet单个网络的识别率是比GooLeNet要好的,下面是正式的介绍。
Abstract
这篇论文中作者探究了一下深度神经网络中网络的层数与网络的分类能力的关系,结果就是网络越深,网络学习能力越好,分类能力越强。现在看来可能是显而易见的,可是在14年还没几个人撘特别深的网络时,也算个发现成果吧。作者做的主要贡献就是使用了具有小卷积核(3x3大小)的深度神经网络在达到一定深度(16~19层)以后性能会有非常显著的提升。
1. ConvNet Configurations
1.1 Architecture
在网络的训练过程中,作者采用的输入图像为224x224的RGB彩色图像,作者做的唯一的预处理就是计算这三个通道的平均值,在训练时减去这些平均值,这样处理训练时网络可能更快的收敛。输入图像在网络中经过一系列具有3x3大小的卷积核的卷积层(说3x3是小卷积核的原因是,3x3大小是可以同时获取上下左右像素信息的最小的卷积核)。在实验中,作者也采用了1x1大小的卷积核,1x1大小的卷积核不能获取局部区域的信息,只能作为对图像单个像素的一种线性处理。
在网络中,所有卷积层的大小都是3x3,而且stride均为1,同时pad也为1,保证卷积层不改变feature map的大小,而max pooling层的kernel为2x2,同时stride为2。卷积层以后是两个全连接层,全连接层为4096维,后面是一个1000维的全连接层,最后跟一个softmax层。另外,所有隐层后面都跟一个ReLU激活曾进行非线性处理。
说了这么多看一下作者总结的网络结构表格吧,表格说的更清楚。
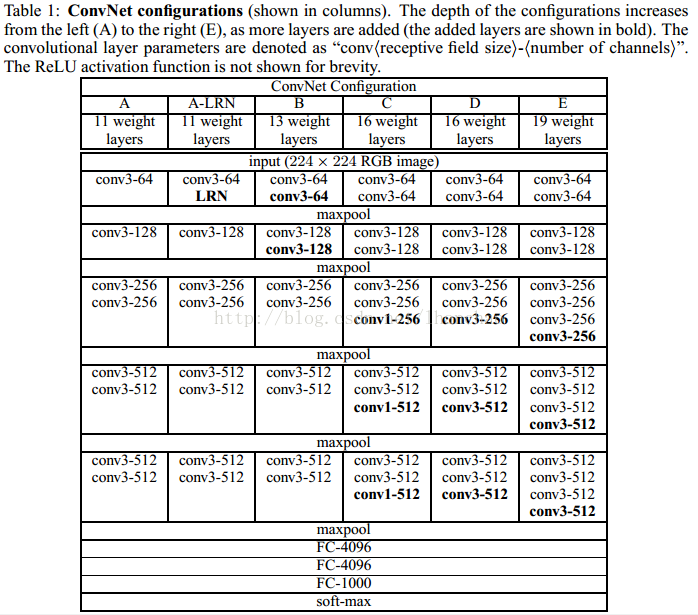
1.2 Configurations
全部都写到上面的表中了,这里需要提一下的是作者的
卷积层的filters数目,从64开始,每经过一个max pooling后就把filters数目翻倍。
1.3 Discussion
这一部分作者主要介绍了使用3x3大小的卷积核的原因:我么可以很明显的看出,两个连续的3x3大小的卷积层与一个5x5大小的卷积核具有相同的局部空间,而连续3个3x3大小的卷积核则与一个7x7大小的卷积核具有相同的局部空间。但是相比使用一个7x7大小的卷积核,3个连续的3x3的卷积核进行了3次非线性处理(7x7的进行了1次),这样在一定程度上就提高了网络的学习能力;另外,使用3x3的卷积核也降低了参数的数目,假设3x3的的卷积核处理C通道的feature maps时,一共有3(3x3xCxC)=27CxC个参数,而7x7的则有7x7xCxC共49CxC个参数;最后这也可以看成是对7x7的filter进行正则化处理,强迫7x7的卷积核分解为3x3大小的。
后面作者介绍了1x1卷积核的好处,这里我们就不详述了,在GooLeNet的介绍博客中已经很详细的说明了1x1大小的卷积核的作用。
最后,作者介绍了几个使用小卷积核的工作,证明小卷积核相比大卷积核确实是有一定的优势的。
2. Classification Framework
2.1 训练阶段
这里主要介绍了作者在训练时的一些参数配置:
(1)使用随机梯度下降法(SGD)进行训练;
(2)batch size = 256;
(3)momentum = 0.9;
(4)weight decay = 0.0005;
(5)dropout ratio = 0.5
(6)learning rate = 0.01
(7)learning rate变化方法:当validation的识别率不变化的时候,learning rate降低十倍
(很好奇,怎么用caffe控制这一点的?)
以上的设置都与我们平时的设置差不大多,就不详细解释了。
最后作者说明在训练的过程中,比AlexNet收敛的要快一些,原因为:(1)使用小卷积核和更深的网络进行的正则化;(2)在特定的层使用了预训练得到的数据进行参数的初始化。
作者提到对于较浅的网络,如上图中的网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
2.2 测试阶段
本篇论文中值得一提的是作者在测试阶段的操作,在测试阶段中,作者把测试图片的最短边设为Q,注意到这个Q和训练过程中图片的最短边S不一定相等,而且可以对于同一张测试图片可以rescale成不同的大小,即多个scale的同一张图片在都在网络中进行测试,这样可以提升测试效果。在测试阶段,作者参考Sermanet等人的做法(Sermanet的做法见文章
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks这也是一篇非常经典的文章,以后再写关于它的阅读笔记)对于网络的全连接层转换为多个卷积层进行处理。
这里多讲一点,把其实全连接层是可以看做卷积层的,比如一个输入为1024个参数,输出为2048个参数的全连接层,就可以看做输入时1x1大小是的1024通道的feature maps做卷积核为1x1x1024的卷积,输出为1x1大小的2048通道的feature maps。
又比如一个输入为7x7大小,512通道的feature maps,输出为1024个参数的全连接层,就可以看做是输入为7x7大小的512通道的feature maps做卷积核为7x7x512的卷积,输出为1x1大小的1024通道的feature maps。
其实说白了就是把全连接层中的每个节点看做是一个1x1大小的feature map,而若有n个节点,则看做是1x1的n通道的feature maps。
不知道我说的清楚不清楚,大家可以参考
知乎——全连接层的作用是什么?魏秀参的回答
好的,原归正传,作者在对测试图像进行了类似Sermanet的做法以后,最后得到的就是一个具有n通道的(n为最后要求分类的类别数目),a x b大小的一个feature map(这里a和b的大小取决于输入的测试图像的大小),最后把不同scale的测试图像得到的结果进行了一个average操作,作为真正的分类结果。(其实这里不同scale的测试图像最后得到的n通道的axb feature map是不同的,Sermanet首先把一个scale中的axbxn的feature map合并为1x1xn大小的向量,合并的方法就是取这axb个不同向量中同一维(每个向量有n个维度)中最大的那个座位合并结果中该维度的值,最后不同的scale的1x1xn的向量再做average操作)
这里有些绕,不知道我说清楚没= =|,有问题可以留言,我尽量说清楚些。
接下来就是介绍为什么使用Sermanet的做法,而不是使用Alexnet的做法,对一个测试图片进行多次crop(取中间、四角的crop),因为Sermanet的做法可以一次计算即可获取同一张图片不同的区域的分类结果(上面提到的axb,即axb个不同的区域),而Alexnet则需要对不同的crop分别进行计算,这样就减少了计算量。另外,作者也提到了,如果对同一张图片切成大量的的crops,进行测试的话同样也可以提高正确率。但是由于大量的crops需要大量的计算,实际应用中由于增加crops增加正确率相比增大的计算量明显不划算,所以实用性肯定不强,但是作为参考作者还是进行了多个crop的测试。
3. 实验结果
终于可以缓口气,大家来看一下作者的实验结果
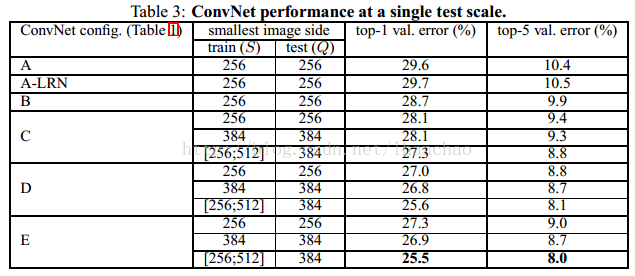
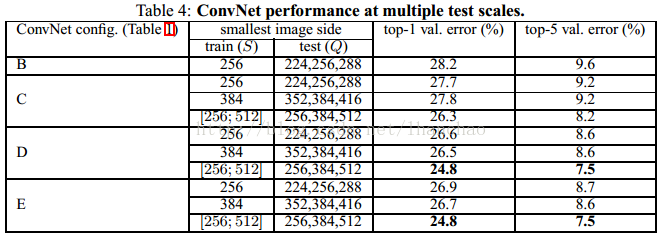
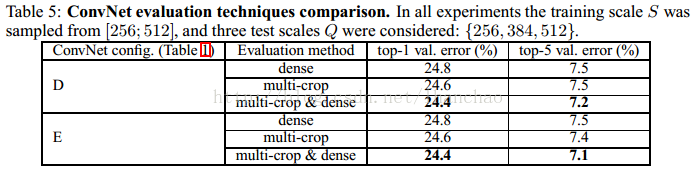
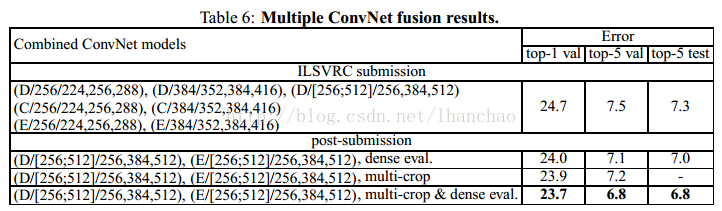
以上一个图分别是单尺度测试、多尺度测试、大量crops测试、多模型投票的实验结果,可以看出的是深度越深,实验结果越好,多尺度测试比单尺度测试结果要好,大量crops的测试结果可以进一步提高正确率,多模型若何也可以提高正确率。
4. 总结
其实以现在(2017年)的角度来看,我觉得这篇文章介绍的VGGNet的网络结构创新性并不大,说白了就是堆网络层数。值得称道的是作者这样设计的原因,能够分析小卷积核的作用,总体来说还是大神一样的存在,要不然现在就不会有很多人直接拿VGGNet在自己的任务上训练了。