论文来源:arxiv.org
本文作者:李炎,硕士研究生,目前研究方向为深度学习、计算机视觉。
摘要
将基于自注意力机制的Transformer直接应用于图像分类;传统计算机视觉任务都是以CNN结构为主导。本文采用与原始Transformer几乎相同的结构对图像进行分类,在经过数据集验证后表明在更大量的数据集训练下效果比以往方法好,但是小数据集训练结果较差。
问题描述
受Transformer在NLP领域应用的效果启发,将标准Transformer结构直接应用于图像分类任务。
致在尽量不改动原始的Transformer结构,并且可以进行端到端训练。
本文核心工作
-
设计一种与标准Transformer Encoder结构几乎相同的ViT网络模型用于图像分类
-
验证采用不同大小的数据集训练对模型性能的影响
模型

-
网络模型输入:将图片分成尺寸为(P*P)的几块(patch),然后将每块拉成一维,作为序列依次进行输入;同时加入Position Embedding,这个Position Embedding也是一维的0,1,2用来表示位置信息。.
-
Transformer 的输入序列长度与patch大小的平方成反比,因此具有较小patch大小的模型在计算上更昂贵
-
网络模型输出:最终输入图片的类别序列。
-
网络由以下几种模块组成:多头注意力机制(Multi-Head Attention)、层归一化(Norm)、多层感知机(MLP)、残差结构
实验
实验设计
-
对比:ViT-B/32、 ViT-L/16、 ViT-H/14、 ResNet50四种网络模型进行相同训练后的检测效果
-
对比在不同大小数据集上进行训练后的网络检测效果
数据集
ILSVRC-2012 ImageNet:1k classes and 1.3M images
ImageNet-21k :21k classes and 14M images
实验结果
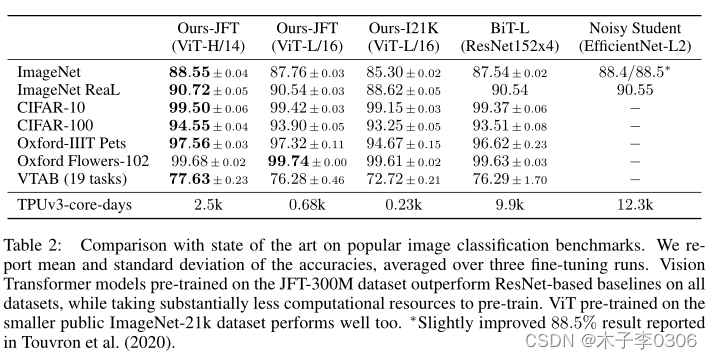
实验结果表明在各个大小数据集上经过训练的ViT网络效果都要好于ResNet50网络结构;在更大数据集上训练后的效果更好。

ResNets 在较小的预训练数据集上表现更好,但比 ViT 更快达到稳定状态,后者在较大的预训练数据集上表现更好。
总结
- 本文将图像分成一系列补丁(Patch)进行输入,使用标准 Transformer 编码器对其进行处理。
- 该网络模型在大型数据集中进行预训练后,效果很好。
- 由此Vision Transformer 在许多图像分类数据集上达到或超过了最先进的水平,同时预训练相对更容易。
其他相关文章
一文带你掌(放)握(弃)ViT(Vision Transformer)(原理解读+实践代码)
论文代码:GitHub