摘要
作者称,现有多数方法都是在低噪声训练集上进行学习,这不符合现实低照度图像噪点多的真实特点。同时作者发现在低照度图像中的噪声在不同频度表现不同,低频层相比高频层更容易检测到噪声,并且更容易被抑制(给出的参考论文是29和41)。作者提出了一个网络,能够先在低频层恢复图像对象,在恢复的图像基础上增强高频细节。作者还设计了一套新的sRGB低照度图像数据集(文中称这是出于SID方法使用RAW原始数据不够方便的考虑)。还提出了ACE和CDT两个子模块。

用博主自己的的话来说整体流程如下:
- 输入低照度图像(作者自己建立的RAW转sRGB数据集),
- 经过第一阶段的ACE模块,中间使用低频层结构信息图 ,最后得到频率感知非本地特征 ,
- 将 输入编码解码结构(包含CDT模块),也是使用低频信息得到内容 ,再放大,
- 将放大得到的 输入第二阶段的ACE,此时使用的是高频细节的 ,并得到响应的 ,
- 输入 到第二阶段的编码解码(包含CDT模块),使用高频细节进行重构加工,
- 最后像素级相加得到最终增强结果。
总的来说,作者利用低频层来检测噪声并在低频层抑制噪声,同时低频层包含图像的主要结构信息,这都是在网络的第一阶段中进行处理,第一阶段是先要去除高频层的影响;而高频层包含图像细节,在第二阶段重构的时候用到,能够让增强图像保持锐度,防止模糊。
introduction
e、d、f是低照度图像方法增强结果。c、d分别是作者使用高斯滤波器得到的低频层和高频层,低频层中充满了噪声。g是GT,h是作者方法的结果。作者称现有低照度图像方法及时增强了图像,仍旧保持较低的信噪比(SNR)。这就有点类似说增强后的图像PSNR值比较低,不过实际上,有些增强后的图像即使PSNR值较高,也不代表好,因为PSNR不太能代表人主观观察的喜好,存在高值却看起来很失真的情况。

关于去噪
作者称,之前传统方法有采用例如自相似性、稀疏性和低秩(low rank)等特性来去噪,还有深度学习的一些模型,但是这些方法通常从假设有加性(addactive)、白噪声或者高斯噪声中训练,不符合真实情况。又有一些方法使用单纯合成数据或者单纯真实数据,或者两者混杂在一起,或者无监督,进行训练,但是效果都不太理想。
作者称这些方式都没有考虑到低像素的低照度图像难以提供足够上下文信息(这里不是很清楚)进行去噪;同时在增强图像的时候,某些噪声会被“不可预测地”放大(实际上哪种方法都无可避免,关于这点我猜作者应该也是为了写而写)
模型概况
第一阶段:
是放大后的低频层;
是低频图像增强函数,
是颜色恢复放大函数。
作者称下面这个公式可以不必学习全局信息(如照明)和局部信息(如颜色),从而提高增强结果
第一级增强:
,
是可学习的全局比例。
第二阶段:
没有使用充满噪声的原始图像,而是使用上一级产生的
来学习高频细节,还有高频细节增强函数
,然后用残差的方式对
进行建模:
下图为各阶段结果可视化(d-h):

Attention to Context Encoding(ACE)模型
ACE模块的目标是学习用于图像分解的频率感知特征,ACE扩展了非局部操作[42]来选择频率自适应上下文信息,该操作最初是为编码远程关系而提出的。
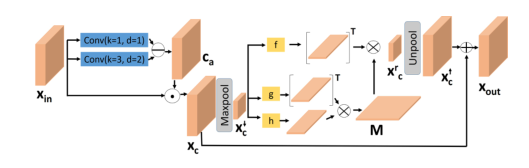
这里用两个膨胀卷积d1、d2,然后通过公式:
,得到对比度感知注意力图
,它包含像素级的高频信息。再通过
,得到包含低频信息的
。在ACE和CDT模型中,都是在第一阶段用
,即低频信息,再在第二阶段使用
即高频信息。同时
。
第一阶段第二阶段ACE层共享参数
下图是ACE结果可视化。

Cross Domain Tranformation(CDT)模型

此模块的作用是,缩小低照度图像和增强图像之间特征差距(距离),用的是和文中39一样的增加感受野已获得更多全局信息的方法。
在第一阶段:
来自编码器的噪声特征在空间上通过逆对比度感知图
来消除高频细节(即高对比度的像素细节),然后和相对应的编码器的特征
连接。再从特征
计算全局缩放向量
,以通道自适应的方式来缩放不同域的特征。(en编码器,de解码器,具体框架看最上面整体框架图)
在第二阶段:
使用对比度感知图
而非逆对比度感知图。和ACE一样的操作。
数据集
本文数据集基于SID数据集建立,但是SID中的RAW相机原始数据是线性的,而普遍使用的sRGB(普通jpg之类的)为非线性的。而且,基于相机原始数据和sRGB的方法不能完全同等换用,是有不同的。所以作者通过三个方面,来修改RAW相机原始数据,变成可使用的sRGB数据集:曝光补偿、白平衡和去线性化。
- 曝光补偿:碍于曝光补偿在每个相机的标准都不太一致,所以以0.5EV的间隔从[0EV,2EV]随机抽取曝光补偿值
- 白平衡:碍于白平衡在每个相机标准也不太一致,所以选择了[2100K,4000K]范围内的色温,这表示典型的家庭照明和日出/日落照明的色温。
- 去线性化:碍于每个相机响应函数所引入的非线性不同,很难进行逆向工程(17),所以作者这里如(12)所建议,使用伽马矫正来去线性化。(伽马矫正能够反向)
最终得到4198个用于训练的图像对和1196个用于测试的图像对。
loss
loss设计相对简单:
用的L2 loss,
是重构内容,
是低频层的GT,
是增强(重构)后的图像,
是增强图像的GT。这里要搞清楚,低频层对应图像内容;增强图像对应增强图像的GT。还有前两个是系数。同时还加了一个VGG loss,
,
是VGG。
experiments



注意这里的定性比较中,作者通过用他们自己的sRGB训练集重新训练原本使用RAW数据的SID方法,展示作者方法的有效性(表格中的*)。还有消融实验中,通过各个部件的控制变量,来证明各个部件确实能够提高性能。以及一个是,先使用增强方法(以LIME举例)再使用传统去噪BM3D效果好还是先去噪再使用BM3D效果好,这个思路不错,证明了无论是前面两个方法中的哪一个,都不能很好降低噪声,只能是通过深度学习,进行照片重构增强才能很好地去除噪声。