论文地址:《Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement》
代码地址:https://github.com/langmanbusi/Semantic-Aware-Low-Light-Image-Enhancement
Abstract
弱光图像增强(LLIE)研究如何提高照明和产生正常光图像。现有的方法大多采用全局统一的方式对微光图像进行改进,而没有考虑不同区域的语义信息。如果没有语义先验,网络很容易偏离区域的原始颜色。
为了解决这一问题,我们提出了一种新的语义感知知识引导框架(semantic-aware knowledge-guided framework, SKF),该框架可以帮助弱光增强模型学习包含在语义分割模型中的丰富和多样化的先验。
我们专注于从三个关键方面整合语义知识 :
一个语义感知的嵌入模块(semantic-aware embedding module),在特征表示空间中整合语义先验;
一个语义引导的颜色直方图损失(semantic-guided color histogram loss),保持各种实例的颜色一致性;
一个语义引导的对抗损失(semantic-guided adversarial loss),通过语义先验产生更自然的纹理。
我们的SKF在充当LLIE任务的一般框架方面很有吸引力。大量的实验表明,在多个数据集上,使用SKF的模型显著优于基线,我们的SKF可以很好地推广到不同的模型和场景。
1. Introduction
在现实世界中,由于不可避免的环境或技术限制(如照明不足和曝光时间有限),微光成像相当普遍。微光图像不仅对人类感知具有较差的可视性,而且不适合后续的多媒体计算和为高质量图像设计的下游视觉任务[4,9,36]。因此,我们提出了微光图像增强(LLIE)来揭示微光图像中隐藏的细节,并避免在后续视觉任务中降低性能。主流的传统LLIE方法包括基于直方图均衡化的方法[2]和基于Retinex模型的方法[18]。
最近,许多基于深度学习的LLIE方法被提出,如端到端框架[5,7,34,45,46,48]和基于retainex的框架[29,41,43,44,49,53,54]。deep LLIE方法得益于其对微光和高质量图像之间映射的建模能力,通常比传统方法获得更好的结果。然而,现有的方法通常对微光图像进行全局统一的改进,而没有考虑不同区域的语义信息,而语义信息是增强的关键。如图1(a)所示,缺乏语义先验利用的网络很容易偏离区域的原始色调[22]。

此外,研究还证明了将语义先验与弱光增强相结合的重要性。Fan等人的[8]利用语义映射作为先验,将其整合到特征表示空间中,从而提高了图像质量。Zheng等人的[58]没有依赖于优化中间特征,而是采用了一种新的loss来保证增强后图像的语义一致性。这些方法成功地将语义先验与LLIE任务结合起来,证明了语义约束和引导的优越性。
然而,他们的方法未能充分利用语义分割网络可以提供的知识,限制了语义先验的性能增益。此外,分割和增强之间的交互是针对特定的方法设计的,限制了将语义引导纳入LLIE任务的可能性。
因此,我们想知道两个问题:
1.我们如何获得各种各样和可用的语义知识?
2. 语义知识如何促进LLIE任务图像质量的提高?
我们试图回答第一个问题。首先,引入在大规模数据集上预先训练的语义分割网络作为语义知识库(semantic knowledge bank, SKB)。该算法可以提供更丰富、更多样化的语义先验来提高增强网络的能力。其次,根据前人的研究[8,19,58],SKB提供的可用先验主要由中间特征和语义映射组成。一旦训练了一个LLIE模型,SKB产生以上的语义先验并指导增强过程。该先验不仅可以利用亲和矩阵(affinity matrices)、空间特征变换(spatial feature transformations)[40]和注意机制(attention mechanisms)等技术来细化图像特征,还可以通过将区域信息明确地整合到LLIE任务[26]中来指导目标函数的设计。
然后我们试着回答第二个问题。在此基础上,我们设计了一系列将语义知识整合到LLIE任务中的新方法,并构建了一种新的语义感知的知识引导框架(SKF)。首先,我们使用在PASCAL-Context数据集[35]上预先训练的高分辨率网络[38] (HRNet)作为前面提到的SKB。
为了利用中间特性,我们开发了一个语义感知嵌入(semantic-aware embedding,SE)模块。它计算参考和目标特征之间的相似度,并在heterogeneous representations之间采用cross-modal interactions。因此,我们将图像特征的语义感知量化为一种注意形式,并将语义一致性嵌入增强网络中。
其次,一些方法[20,55]提出利用颜色直方图优化图像增强,以保持图像的颜色一致性,而不是简单地全局增强亮度。另一方面,颜色直方图仍然是一个全局统计特征,不能保证局部一致性。因此,我们提出了一种语义引导的颜色直方图(SCH)损失来改善颜色的一致性。在这里,我们打算利用从场景语义中得到的局部几何信息和从内容中得到的全局颜色信息。在保证增强后图像原始颜色的同时,还可以在颜色直方图中加入空间信息,实现更加细致的颜色恢复。
第三,现有的损失函数与人类的感知不匹配,无法捕捉图像的固有信号结构,导致视觉效果不佳。为了提高视觉质量,enlightened[16]采用了global和local image-content consistency,随机选择local patch。然而,鉴别器并不知道哪些区域可能是“假的”。因此,我们提出了一种语义引导的对抗性损失。具体来说,通过利用分割图来确定伪区域,提高了鉴别器的能力,进一步提高了图像质量。
我们工作的主要贡献如下 :
- 我们提出了一种语义感知的知识引导框架(SKF),通过共同维护颜色一致性和改善图像质量来提高现有方法的性能。
- 为了充分利用语义知识库(SKB)提供的语义先验,我们提出了三个关键技术:语义感知嵌入(SE)模块、语义引导颜色直方图(SCH)丢失和语义引导对抗(SA)丢失。
- 我们对LOL/ LOL-v2数据集和未配对数据集进行了实验。实验结果表明,我们的SKF在解决LLIE任务方面有很大的提高,验证了它的有效性。
2. Related Work
2.1. Low-light Image Enhancement
Traditional methods
传统的微光增强方法包括基于直方图均衡化的方法[2]和基于Retinex模型的方法[18]。前者通过扩展动态范围来改善弱光图像。后者将弱光图像分解为反射和光照映射,并将反射分量视为增强图像。这种基于模型的方法需要明确的先验来很好地拟合数据,但为各种场景设计合适的先验是困难的。
Learning-based methods
最近的基于深度学习的方法显示了很好的结果[15,29,43,44,53,54,56]。我们可以进一步将现有的设计分为基于retainex的方法和端到端方法。基于retex的方法利用深度网络对图像进行分解和增强。Wei等人提出了一种基于retainex的两阶段方法,称为retainex net[43]。受reatex net的启发,Zhang等人提出了两种精细化的方法,称为KinD[54]和KinD++[53]。最近,Wu等人[44]提出了一种新的基于retainex深度展开的网络,进一步整合了基于模型和基于学习的方法的优势。
与基于retainex的方法相比,端到端方法直接学习增强的结果[5-7,27,32,34,37,41,45,46,51,57,59]。Lore等人提出了一个名为LowLight Net (LLNet)的深度自动编码器,这是[30]的第一次尝试。随后,各种端到端的方法被提出。提出了拉普拉斯金字塔[27]、局部参数滤波器[34]、拉格朗日乘子[57]、De-Bayer-Filter[5]、归一化流[41]和小波变换[7]等基于物理的概念,以提高模型的可解释性,得到视觉上令人满意的结果。在[16,17,48]中,引入对抗学习来捕捉视觉属性。在[11]中,光增强被创造性地表述为一项使用零拍学习进行图像特定曲线估计的任务。[20, 47, 55]利用3D查找表和颜色直方图来保持颜色的一致性。然而,现有的设计侧重于优化增强过程,而忽略了不同区域的语义信息。相比之下,我们设计了一个具有三个关键技术的SKF来探索语义先验的潜力,从而产生视觉上令人愉悦的增强结果。
2.2. Semantic-Guided Methods
近年来,语义引导方法证明了语义先验的可靠性。这些方法可以分为两类:损失级语义引导方法和特征级语义引导方法。
Loss-level semantic-guided methods
为了利用语义先验,一些研究将语义感知缺失作为原始视觉任务的额外目标函数。在图像去噪[28]、图像超分辨率[1]、微光图像增强[58]中,研究者直接利用语义分割损失作为额外的约束来指导训练过程。此外,Liang等人的[26]通过语义亮度一致性损失,更好地保持了图像的细节。
Feature-level semantic-guided methods.
与损失级语义引导方法相比,特征级语义引导方法侧重于从语义分割网络中提取中间特征,并在特征表示空间中引入语义先验与图像特征相结合。在图像恢复[23]、图像解析[24]、图像超分辨率[40]、微光图像增强[8]、深度估计等方面也有类似的工作[10,19]。
现有的语义引导方法由于语义先验与原始任务之间的交互不足而受到限制。因此,我们提出了一个语义感知的框架,以充分利用语义信息在损失级别和特征级别,包括两个语义引导的损失和一个语义感知的嵌入模块。具体来说,与LLIE任务中的语义引导方法相比[8,26,58],我们的SKF作为一个通用框架是有吸引力的。
3. Method
3.1 Motivation and Overview
照明增强是通过调整照明、消除噪声和恢复丢失的细节,使曝光不足的图像看起来更好的过程。语义先验可以为提高增强性能提供丰富的信息。具体来说,semantic prior 可以帮助将现有的LLIE(low-light image enhancement )方法重新表述为一个 region-aware enahncement framework。特别是,新模型将以一种简单的方式模糊平滑区域的噪声,该模型将天空等平滑区域的噪声进行简单的模糊处理,而室内场景等细节丰富的区域则会非常小心。此外,结合语义先验,对增强后的图像进行颜色一致性处理。缺乏语义先验访问的网络很容易偏离区域的原始色调[22]。然而,现有的弱光增强方法忽视了语义信息的重要性,能力有限。

本文提出了一种新的SKF算法(semantic-aware knowledge-guided framework,SKF),联合优化图像特征,保持区域颜色一致性,提高图像质量。如图2所示,SKB提供语义先验,并通过SE模块、SCH loss和SA loss三个关键组件集成到LLIE任务中。
- Problem definition of semantic-aware LLIE
给定微光图像 I l ∈ R W × H × 3 I_l∈R^{W×H×3} Il∈RW×H×3,宽度 W W W,高度 H H H,结合语义分割,LLIE过程可建模为两个函数, 第一个:
M = F segment ( I l ; θ s ) , M=\mathbf{F}_{\text {segment }}\left(I_l ; \theta_s\right), M=Fsegment (Il;θs),
其中M为语义先验,包括分割结果和具有多尺度维度的中间特征。
F s e g m e n t F_{segment} Fsegment表示预先训练的语义分割网络,作为SKB(semantic knowledge bank), θ s \theta_s θs在训练阶段被冻结。然后用 M M M作为输入:
I h ^ = F enhance ( I l , M ; θ e ) \widehat{I_h}=\mathbf{F}_{\text {enhance }}\left(I_l, M ; \theta_e\right) Ih =Fenhance (Il,M;θe)
其中 I h ^ ∈ R W × H × 3 \hat {I_h} \in R^{W\times H\times 3} Ih^∈RW×H×3为增强结果, F e n h a n c e F_{enhance} Fenhance表示增强网络。训练阶段,在 M M M的引导下,通过最小化目标函数来更新 θ e \theta _e θe, θ s \theta_s θs固定:
θ e ^ = argmin L ( I h ^ , I h , M ) \widehat{\theta_e}=\operatorname{argmin} \mathcal{L}\left(\widehat{I_h}, I_h, M\right) θe =argminL(Ih ,Ih,M)
其中 I h ∈ R W × H × 3 I_h\in R^{W\times H\times 3} Ih∈RW×H×3 是ground truth, L ( I h ^ , I h , M ) \mathcal{L}\left(\widehat{I_h}, I_h, M\right) L(Ih ,Ih,M) 是semantic-aware LLIE的目标函数。
3.2 Semantic-Aware Embedding Module
在利用语义先验细化图像特征时,需要特别考虑的另一个挑战是两种来源之间的差异。为了解决这个问题,我们提出了SE模块来细化图像特征图,如图3所示。SE模块(semantic-aware embedding)就像分割网和增强网之间的桥梁(见图2),在两个异构任务之间建立连接。

在我们的框架中,我们选择了**HRNet[38]**作为SKB,因为它具有出色的性能,并做了一些特定于任务的修改。除了semantic map 外,我们还利用representation head前的输出特征作为multi-scale semantic priors。
为了进一步说明,三个SE模块如图2所示: 因此,我们采用三种空间分辨率( H / 2 4 − b , W / 2 4 − b H/2^{4−b},W/2^{4−b} H/24−b,W/24−b)的语义/图像特征( F s b / F i b F^b_s/F^b_i Fsb/Fib, b = 0 , 1 , 2 b = 0,1,2 b=0,1,2),其中H和W为输入图像的高度和宽度。SE模块在 F s b F^b_s Fsb和 F i b F^b_i Fib之间执行pixel-wise interaction,并给出最终细化的特征图 F o b F^b_o Fob。学习过程的细节如下所示。
SE模块通过cross-modal similarity计算semantic awareness of the image features,并生成semantic-aware map。
我们首先应用卷积层将 F s b F_s^b Fsb和 F i b F_i^b Fib转换为相同的维度。接下来,受restoremer[50]的启发,我们采用一种transposed-attention mechanism,以较低的计算成本来计算attention map。因此,semantic-aware attention map 描述如下
A b = Softmax ( W k ( F i b ) × W q ( F s b ) / C ) , A^b=\operatorname{Softmax}\left(W_k\left(F_i^b\right) \times W_q\left(F_s^b\right) / \sqrt{C}\right), Ab=Softmax(Wk(Fib)×Wq(Fsb)/C),
其中, W k ( ⋅ ) W_k(·) Wk(⋅)和 W q ( ⋅ ) W_q(·) Wq(⋅)为卷积层,LN为层归一化,C为特征的通道数。在这里, A b ∈ R C × C A^b∈R^{C×C} Ab∈RC×C表示语义感知的注意映射,它表示 F i b F^b_i Fib和 F s b F_s^b Fsb之间的相互关系。然后我们用 A b A^b Ab构造图像特征 F i b F_i^b Fib,如下所示:
F o b = F N ( W v ( F i b ) × A b + F i b ) F_o^b=F N\left(W_v\left(F_i^b\right) \times A^b+F_i^b\right) Fob=FN(Wv(Fib)×Ab+Fib)
其中FN为前馈网络, F o b F_o^b Fob 为第b个 SE模块的最终精细化特征图,作为增强网第(b+1)解码器的输入。
3.3 Semantic-Guided Color Histogram Loss
颜色直方图承载了至关重要的图像统计信息,对学习颜色表示很有帮助。DCC-Net[55]采用具有affinity matrix的PCE模块在特征级对颜色直方图和内容进行匹配,从而保持了增强后图像的颜色一致性。然而,颜色直方图描述了一个全局的统计信息,消除了不同实例之间的颜色特征差异。因此,我们提出了一种直观的实现局部颜色调整的方法,即语义引导的颜色直方图(SCH)损失,如图2所示。它着重于调整每个实例的颜色直方图,从而保留更详细的颜色信息。
首先利用semantic map将增强结果分割成具有不同实例标签的image patches; 每个patch 包含一个具有相同标签的实例。因此,将patch的生成过程定义如下:
P = { P 0 , P 1 , … , P class } , P c = I out ⊙ I seg c P=\left\{P^0, P^1, \ldots, P^{\text {class }}\right\}, \quad P^c=I_{\text {out }} \odot I_{\text {seg }}^c P={ P0,P1,…,Pclass },Pc=Iout ⊙Iseg c
式中⊙为点积, I o u t I_{out} Iout为增强结果, I s e g c I^c_{seg} Isegc为one-hot semantic map的第c个通道, P c ∈ R W × H × 3 P^c∈R^{W×H×3} Pc∈RW×H×3为第c个图像patch, P为包含所有patch的组。
由于颜色直方图的离散性,我们受到Kernel Density Estimation[3]的启发,近似可微版本用于模型训练。考虑到语义结果的预测误差,不考虑接近边界的像素。不考虑边缘像素的情况下,我们将patch group P细化为 P ′ P' P′,减少了误分类的影响。对于第c个图像patch的R通道 P c ′ ( R ) P_{c'}(R) Pc′(R),估计过程定义如下:
x i j h = x j − i − 0.5 255 , x i j l = x j − i + 0.5 255 , x_{i j}^h=x_j-\frac{i-0.5}{255}, \quad x_{i j}^l=x_j-\frac{i+0.5}{255}, xijh=xj−255i−0.5,xijl=xj−255i+0.5,
式中, x j x_j xj表示 P c ′ ( R ) P^{c'}(R) Pc′(R)中的第 j j j个像素, i ∈ [ 0 , 255 ] i∈[0,255] i∈[0,255] 表示像素强度。 x i j h x_{ij}^h xijh和 x i j l x_{ij}^l xijl分别代表higher anchor和lower anchor,这是估计直方图的关键变量,如下图所示 :
H i c = ∑ j ( Sigmoid ( α ⋅ x i j h ) − Sigmoid ( α ⋅ x i j l ) ) H c = { i , H i c } i = 0 255 \begin{gathered}H_i^c=\sum_j\left(\operatorname{Sigmoid}\left(\alpha \cdot x_{i j}^h\right)-\operatorname{Sigmoid}\left(\alpha \cdot x_{i j}^l\right)\right) \\H^c=\left\{i, H_i^c\right\}_{i=0}^{255}\end{gathered} Hic=j∑(Sigmoid(α⋅xijh)−Sigmoid(α⋅xijl))Hc={ i,Hic}i=0255
其中 H c H^c Hc表示 P c ′ ( R ) P^{c'}(R) Pc′(R)的可微直方图, H i c H_i^c Hic表示强度值为 i i i 的估计像素数。 α \alpha α 是一个比例因子,为了更好地估计,我们在实验中将其设置为400。两个 S i g m o i d ( ⋅ ) Sigmoid(·) Sigmoid(⋅)结果的差值表示 x j x_j xj对强度值为 i i i的像素个数的贡献,当 x j x_j xj正好等于 i i i时,差值为1,即 x j x_j xj对 H i c H_i^c Hic加1。
最后,我们使用 l 1 l_1 l1 loss 来约束估计的可微直方图。因此,SCH loss可以描述为 :
L S C H = ∑ c ∥ H c ( I ^ h ) − H c ( I h ) ∥ 1 , \mathcal{L}_{S C H}=\sum_c\left\|H^c\left(\hat{I}_h\right)-H^c\left(I_h\right)\right\|_1, LSCH=c∑ Hc(I^h)−Hc(Ih) 1,
式中 I ^ h \hat I_h I^h和 I h I_h Ih分别表示output和ground truth, H c ( . ) H^c(.) Hc(.)表示直方图估计过程。
3.4 Semantic-Guided Adversarial Loss
在image inpainting 任务中,使用全局和局部discriminator来鼓励更真实的结果[14,25]。Enlightened gan[16]也采用了这一理念,但是局部的patches是随机选取的,而不是聚焦于fake region。因此,我们引入语义信息来引导discriminator关注有用的区域。为此,我们通过3.3节中提到的分割图 I s e g I_{seg} Iseg和image patches P ′ P' P′进一步细化了全局和局部adversarial loss函数。最后,我们提出了语义引导的对抗性损失(semantic-guided adversarial (SA) loss)。
对于局部对抗损失,我们首先使用改进的patch group P ′ P' P′作为输出 I o u t I_{out} Iout的candidate fake patches。然后,我们比较 P ′ P' P′之间image patch的discriminating result,最差的patch最有可能是”fake”的,可以选择它来更新discriminator和generator的参数。因此,discriminator很有可能使用语义先验自行找到target fake region x f x_f xf ~ p f a k e p_{fake} pfake。而真正的real patch x r x_r xr ~ p r e a l p_{real} preal每次仍然是随机从真实图像中裁剪出来的。局部对抗损失函数定义为:
L local = min G max D E x r ∼ p real MSE ( D ( x r ) , 0 ) + E x f ∼ p fake MSE ( D ( x f ) , 1 ) , \begin{gathered}\mathcal{L}_{\text {local }}=\min _G \max _D \mathbb{E}_{x_r \sim p_{\text {real }}} \operatorname{MSE}\left(D\left(x_r\right), 0\right) \\\\+\mathbb{E}_{x_f \sim p_{\text {fake }}} \operatorname{MSE}\left(D\left(x_f\right), 1\right),\end{gathered} Llocal =GminDmaxExr∼preal MSE(D(xr),0)+Exf∼pfake MSE(D(xf),1),
x f = P t , D ( P t ) = min ( D ( P 0 ) , … , D ( P class ) ) x_f=P^t, D\left(P^t\right)=\min \left(D\left(P^0\right), \ldots, D\left(P^{\text {class }}\right)\right) xf=Pt,D(Pt)=min(D(P0),…,D(Pclass ))
式中, M S E ( ⋅ ) MSE(·) MSE(⋅)为均方误差, P t P_t Pt为目标fake patch。
针对全局对抗性损失,我们采用了一种简单的设计来实现识别假样本时的语义感知指导。我们将 I o u t I_{out} Iout和 I s e g ′ I'_{seg} Iseg′连接起来,这是Softmax之前的输出特性,作为一个新的 x f x_f xf。随机采样具有real distribution的图像 x r x_r xr。最后,全局对抗损失函数定义为:
L global = min G max D E x r ∼ p real MSE ( D ( x r ) , 0 ) + E x f ∼ p fake MSE ( D ( x f , I seg ′ ) , 1 ) \begin{array}{r}\mathcal{L}_{\text {global }}=\min _G \max _D \mathbb{E}_{x_r \sim p_{\text {real }}} \operatorname{MSE}\left(D\left(x_r\right), 0\right) \\\\+\mathbb{E}_{x_f \sim p_{\text {fake }}} \operatorname{MSE}\left(D\left(x_f, I_{\text {seg }}^{\prime}\right), 1\right)\end{array} Lglobal =minGmaxDExr∼preal MSE(D(xr),0)+Exf∼pfake MSE(D(xf,Iseg ′),1)
因此,SA损失可以定义为:
L S A = L global + L local \mathcal{L}_{S A}=\mathcal{L}_{\text {global }}+\mathcal{L}_{\text {local }} LSA=Lglobal +Llocal
我们将Enhancement Net的原始损失函数定义为 L r e c o n L_{recon} Lrecon,根据所选方法的原始设置,可以是 l 1 l_1 l1 loss、MSE loss、SSIM loss等,也可以是他们的组合。因此,我们的SKF的总体损失函数可以表示为:
L all = L recon + λ S C H L S C H + λ S A L S A \mathcal{L}_{\text {all }}=\mathcal{L}_{\text {recon }}+\lambda_{S C H} \mathcal{L}_{S C H}+\lambda_{S A} \mathcal{L}_{S A} Lall =Lrecon +λSCHLSCH+λSALSA
其中 λ s \lambda s λs 是用来平衡这些损失的权重。
4. Experiments
4.1 Experimental Settings
-
Datasets
我们在多个不同场景的数据集上评估了所提出的框架,包括LOL[43]、LOL-v2[49]、MEF[31]、LIME[12]、NPE[39]和DICM[21]。LOL数据集[43]是一个真实捕获的数据集,包含485对低/正常光图像对用于训练,15对用于测试。loll -v2数据集[49]是loll -v2的实部,它比LOL更大、更多样化,包括689对低/正常光对用于训练,100对用于测试。其中MEF(17张)、LIME(10张)、NPE(85张)和DICM(64张)是包含未配对图像的真实数据集。 -
Metrics
为了评估使用和不使用SKF的不同LLIE方法的性能,我们使用了完全参考和非参考图像质量评价指标。对于LOL/LOL-v2数据集,采用峰值信噪比(PSNR)、结构相似度(SSIM)[42]、学习感知图像贴片相似度(LPIPS)[52]、自然图像质量评价器(NIQE)[33]。对于没有配对数据的MEF、LIME、NPE和DICM数据集,只使用NIQE,因为没有groud truth。 -
Compared Methods
为了验证我们的设计的有效性,我们将我们的方法与一系列用于LLIE的SOTA方法进行了比较,包括LIME[13]、RetinexNet[43]、KinD[54]、DRBN[48]、KinD++[53]、Zero-DCE[11]、ISSR[8]、tgan[16]、MIRNet[51]、HWMNet[7]、SNR-LLIE-Net[46]、LLFlow[41]。为了真实地展示我们的方法的优越性,我们合理地选择了几种方法作为基线网络。其中最具代表性的方法有retexnet、KinD和KinD++,最新的方法有HWMNet、SNR-LLIE-Net和LLFlow。因此,我们的方法被标记为RetinexNetSKF、KinD-SKF、DRBN-SKF、KinD+±SKF、HWMNetSKF、SNR-LLIE-Net-SKF、LLFlow- s -SKF和LLFlow- lskf(分别为LLFlow的小版本和大版本)。 -
Implementation Details
我们在NVIDIA 3090 GPU和NVIDIA A100 GPU上进行实验,实验基于基线网络发布的具有相同训练设置的代码。其中,只对retex -SKF、KinD-SKF和KinD+±SKF的最后一个子网进行SCH loss和SA loss的训练,对其他子网进行原loss函数的训练。此外,我们没有将SA loss应用于LLFlow,因为在训练阶段没有增强输出。此外,SE模块合理地位于所有基线网络的解码器中。
4.2 Quantitative Evaluation
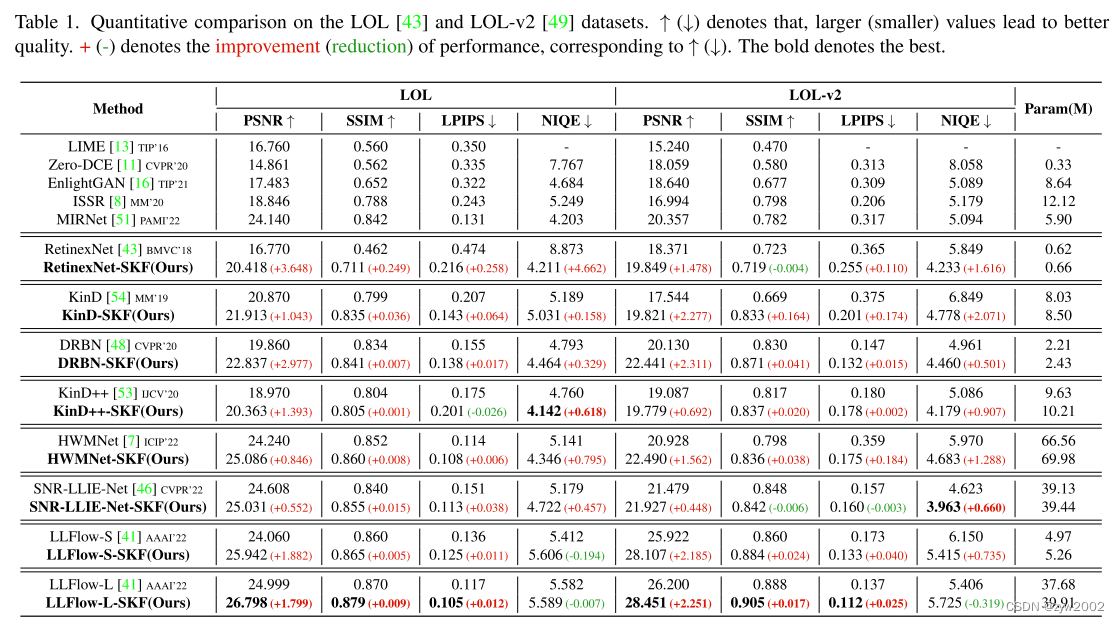
- Quantitative results on LOL and LOL-v2 datasets
评价结果如表1所示。我们可以观察到,我们的SKF在每个基线方法上都获得了一致和显著的性能增益。具体来说,我们的SKF在LOL/ loll -v2数据集上分别提供了1.750 dB/1.611 dB的平均改进,这是通过引入抑制噪声和伪像以及保持颜色一致性的能力来实现的。值得注意的是,我们的LLFlow-L-SKF在LOL/LOL-v2数据集上获得了26.798 dB/28.451 dB的PSNR值,从而建立了一个新的SOTA。此外,SSIM值也实现了类似的性能。在LOL/ loll -v2数据集上,我们的SKF产生了更好的SSIM值,平均为0.041/0.037,这说明我们的SKF有助于基线方法恢复亮度和对比度,并保留详细的结构信息。此外,我们的SKF提供的LPIPS和NIQE的大量收益合理地表明,通过引入我们设计的语义先验,人类直觉更接近于匹配。
- Quantitative results on MEF, LIME, NPE and DICM datasets.
MEF、LIME、NPE和DICM数据集的评价结果如表2所示。总的来说,除了DRBN-SKF和HWMNet-SKF的3个较差的情况外,在所有6个数据集上,使用SKF的每种方法都获得了比基线更好的NIQE结果。retavexnet -SKF在MEF数据集上的NIQE值为3.632,表现最好,而KinD+±SKF在其他5个数据集上的表现最好。总的来说,值得注意的是,在所有的方法和数据集上,我们的SKF在NIQE上产生了0.519的平均增益。结果表明,该方法可以获得更自然的纹理,对弱光图像的恢复效果更好。

4.3 Qualitative Evaluation
对LOL和LIME数据集的定性评价分别如图4和图5所示。从图4可以看出,我们的SKF可以提高基线方法的增强能力,生成更令人满意的感知质量的图像。具体来说,由于存在明显的色差和严重的噪声,因此retexnet的结果是不真实的,我们的SKF可以缓解这一点。与KinD和KinD++的结果相比,KinD-SKF和KinD+±SKF解决了光照不一致和奇怪的白色伪影的问题。对于其他效果,我们的SKF为桌子、墙壁和衣服实现了更一致的颜色和自然的细节恢复。

我们在图5中进一步展示了LIME数据集上的视觉增强结果。可以看出,我们的SKF方法抑制了灯具周围不自然的光晕,恢复了自然的色彩和细节。因此,与基线相比,使用我们的SKF的方法产生了更赏心悦目的视觉结果,这支持了我们的方法在定量评价中的出色表现。更多的可视化结果在补充材料中提供。

4.4. Ablation Study
我们对LOL数据集进行消融研究,从多个方面证明我们的SKF的有效性。
-
SCH loss, SA loss and SE module
如表3所示,我们进行了KinD+±SKF、DRBNSKF和HWMNet-SKF的实验。

添加SCH损耗和SE模块后,PSNR分别比基线平均提高了0.243 dB和0.841 dB。同时应用SCH损耗和SE模块进一步改进了基线方法,在基线上产生了1.741 dB的平均增益。这验证了在增强过程中集成了更多有益的语义感知先验。尽管添加SA损失会导致一些完整参考指标的轻微下降,但NIQE在所有情况下都获得了0.292的平均增益。因此,每个组件通过语义感知知识来细化基线方法,整个框架导致了显著的性能提升。此外,图6的结果表明,使用SCH损耗和SE模块的模型可以保持颜色一致性和细节,而SA损耗通过产生更多的自然纹理来减少假区域。

-
Semantic-guided losses.
表4列出了不同损耗设置的结果。w/o S和w/ S分别表示计算全局直方图和语义引导直方图。对于SA损失,w/o SA、w/o S和w/ S表示没有SA损失的情况下,经典的全局和局部对抗损失,如tgan[16]和我们的SA损失。首先,SCH损耗的HWMNet-SKF具有更好的性能,PSNR的平均改善幅度为0.512 dB,说明SCH损耗对保持颜色一致性的能力显著。此外,在NIQE上添加经典对抗损失的平均增益为0.271,可以归因于鉴别器提高视觉质量的能力。最后,我们的SA损失在NIQE上比基线有0.411的良好增益,真实地证明了语义先验有助于发现虚假区域,从而产生更多的自然图像。

-
Superiority of semantic priors
我们选择HWMNet SKF、LLFlow-S-SKF和LLFlow-L-SKF来研究我们的SKF提供的语义先验和SE模块的更多参数对性能的改善是否有好处。如表5所示,Baseline, Large和w/ SKF表示原始模型,表示有较多层或通道的原始模型,表示有我们SKF的原始模型。我们的方法在PSNR上取得了显著的提高,平均边际为1.272 dB。因此,我们证明了语义先验的优越性,而不是额外的参数。
5. Conclusion
本文提出了一种新的语义感知图像增强框架,名为SKF。SKF将语义先验引入增强网络,通过SE模块、SCH损失和SA损失保持颜色一致性和视觉细节。SE模块允许图像特征通过语义特征表示来感知丰富的空间信息。SCH损耗提供了有效的语义感知区域约束,以保持颜色一致性。SA损失将全局和局部对抗损失和语义先验相结合,寻找目标虚假区域并产生自然结果。大量的实验表明,我们的SKF在所有六种基线方法的情况下都取得了优异的性能,并且LLFlow-L-SKF优于所有的竞争对手。但这种改进在处理未知类别时存在局限性,在提高SKB识别未知实例的能力时具有更大的可能性。此外,我们还将探索SKF在其他低水平视觉任务中的潜力。