
- 这是CVPR2023的弱监督暗图增强论文,需要一个对同一场景有两个不同亮度相同内容的暗图的数据集,但论文提出可以对一张暗图做类似neighbor2neighbor的采样操作得到两张图片来获得。
- 网络结构如下图所示,由3个模块组成,P-net负责对图片进行去噪和去伪影操作,L-Net和R-Net分别对应retinex模型中的L分量和R分量估计。g(L)就是gamma校正。
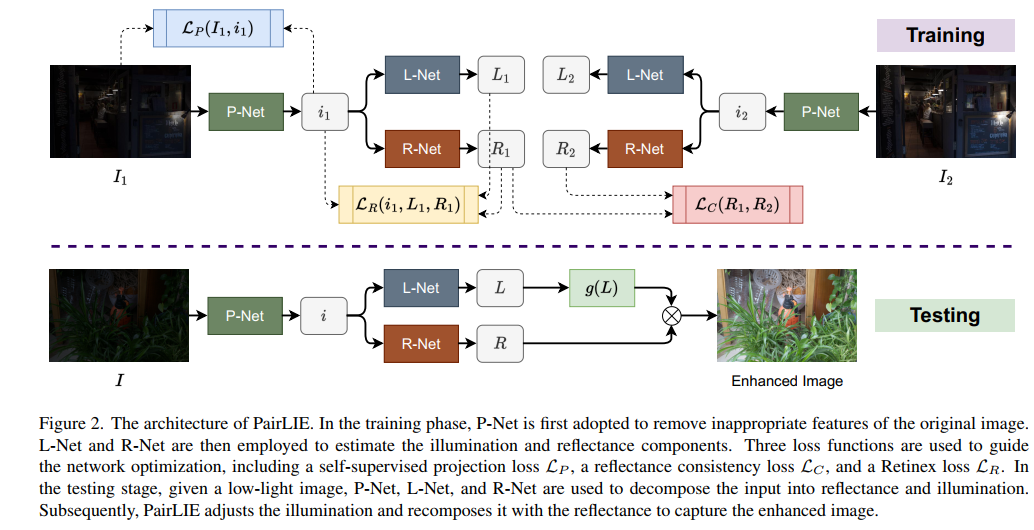
- 可以看到,训练过程有3个损失,一个是对P-Net的重建损失,其实只是对输入和输出进行L2 Loss而已(之所以P-Net能work,还需要依赖其它损失的监督),然后是retinex的重建损失(L*R=I),然后是两张暗图产生的R分量要相同的损失,如下:
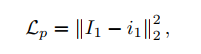
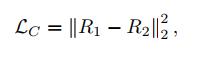
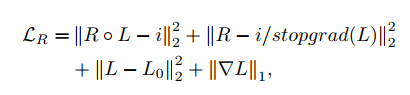
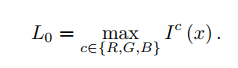
- retinex的重建损失比较特殊,由4项组成,第一、三、四项比较常规,就是常见的retinex先验损失。第二项是补充的,其中stopgrad表示梯度不传播到L中。
- 实验结果还不错
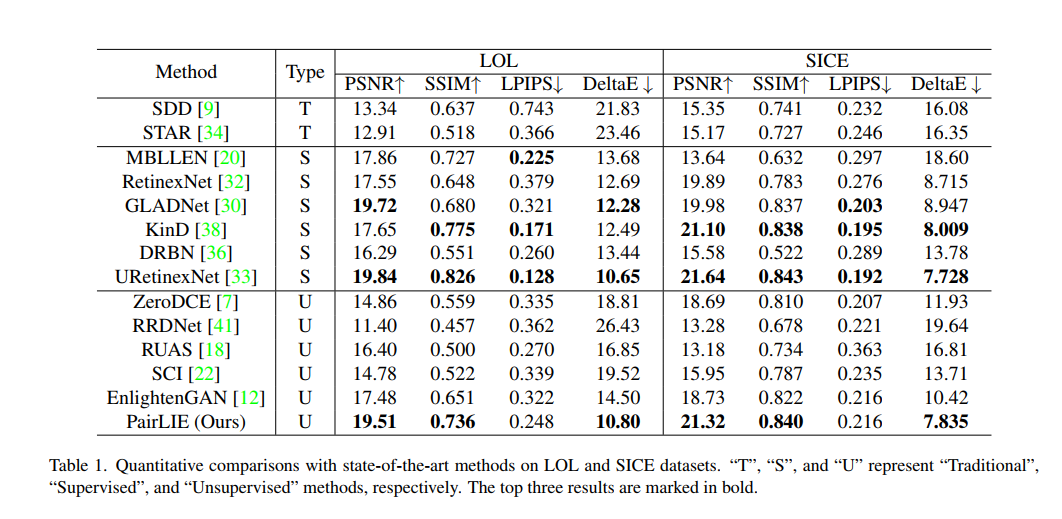

- 总结:我觉得文章的idea有点怪。我既然能对同一个场景获得两张图片,我为什么不一张暗图一张亮图呢。不过如果用neighbor2neighbor那种采样获得两张来训练也还行,但是又没有给出用这种方式训练的实验结果。其实创新点也一般,唯一是一个P-net借助retinex损失来对图片进行去噪挺有意思,其它的都是retinex方法常见的损失。