
- 这是CVPR2023的一篇有监督暗图增强的论文。用了对比学习、自蒸馏学习和progressive learning。
- 文章提出,手工设计的retinex先验总归不太准确,因此要抛弃手工设计的先验,所以缩减至如下目标函数:
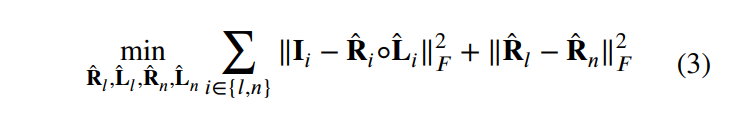
用网络来估计就是如下公式:
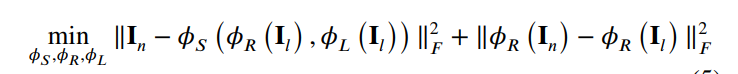
但仍不足够,直接估计R和L分量进行相乘,会导致一些误差,如下:
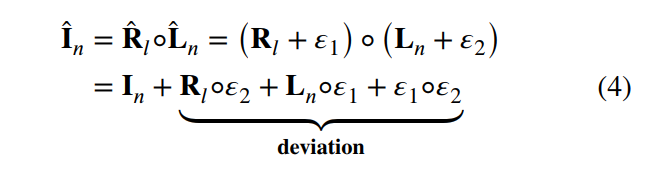
为此文章提出不要估计R 和L分量,而是隐式地估计R和L特征即可
对比学习
- 如果用缩减的retinex公式直接训练,会导致R分量给估计可能无效,因为他只要对所有的图片都预测一个相同的R分量即可。为此引入对比学习来监督R分量的估计。对一张输入的暗图 I l i I_{l_i} Ili,其对应的亮图 I n i I_{n_i} Ini作为positive sample,不对应的亮图 I n k I_{n_k} Ink作为negative sample。同时,为了避免数据集上可能出现相同或者相似场景,用 I n k I_{n_k} Ink和 I n i I_{n_i} Ini之间的SSIM ω i , k \omega_{i,k} ωi,k来进行归一化:
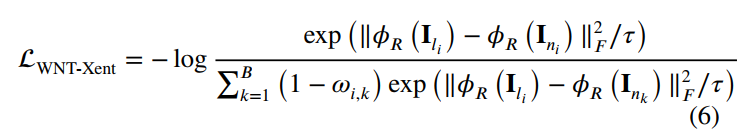
自蒸馏学习
- 作为对对比学习的补充,文章还提出了另一种训练方式(独立于前面的对比学习,也就是说要么用对比学习要么用自蒸馏学习)。利用亮图的R分量估计特征来蒸馏暗图的R分量估计特征(其实如果用的是同一个网络的话是可以不看做自蒸馏的,但是文章用的是两个相同结构不同参数的网络,一个作为教师网络学习亮图的R分量估计特征,一个作为学生网络学习暗图的R分量估计特征,这就和蒸馏学习的流程一摸一样了)
- 为了训练教师网络,用教师网络估计的R分量来预测最终结果,算reconstruction损失。而训练学生网络则是用教师网络的输出和学生网络的输出的距离来算损失。
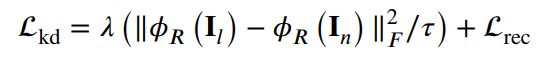
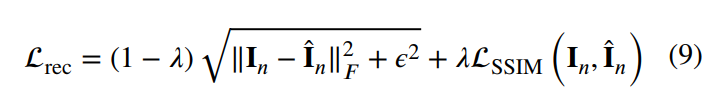
- 但是,在这一训练过程中,由于暗图和亮度差异过大,蒸馏是一个难问题。为此引入了progressive learning来降低蒸馏的难度。将暗图和对应的GT进行加权平均,并随着训练流程的进行增大暗图的权重,从而实现progressive的蒸馏:
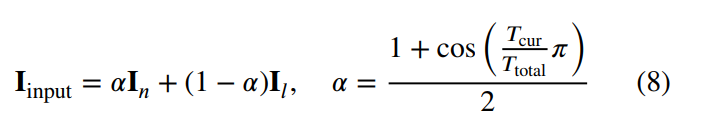
- 这里提出的progressive learning的策略同样也用在了前面的对比学习方法中作为一种数据增强手段。文章提出,用这一手段学习可以使得网络适应多曝光输入,从而应对各种亮度的图片都不容易产生过增强或欠增强,提高了网络的泛化性。
finetune
- 在用上述的对比学习或蒸馏学习的损失训练后,会进行finetune,这时则是直接只用暗图和亮图计算reconstruction损失进行训练,也就是上面的公式9
网络结构
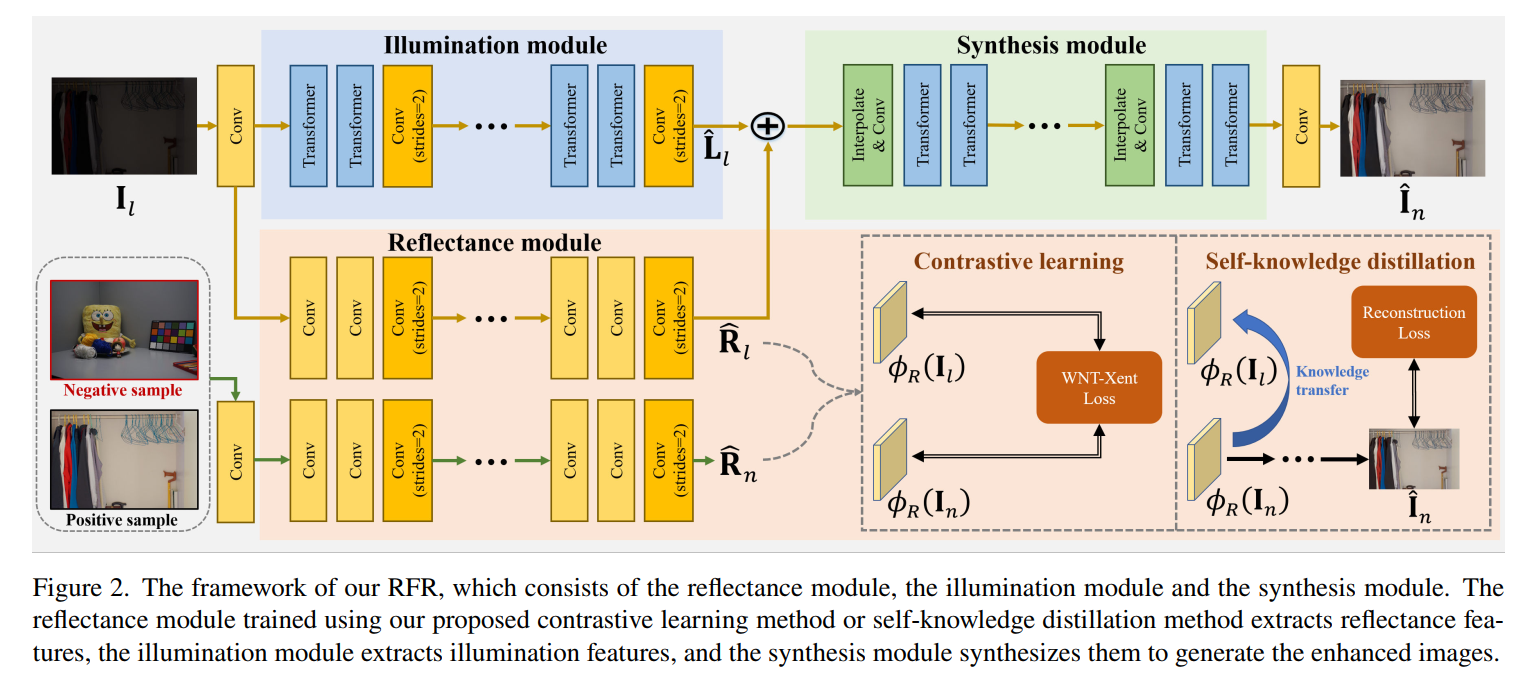
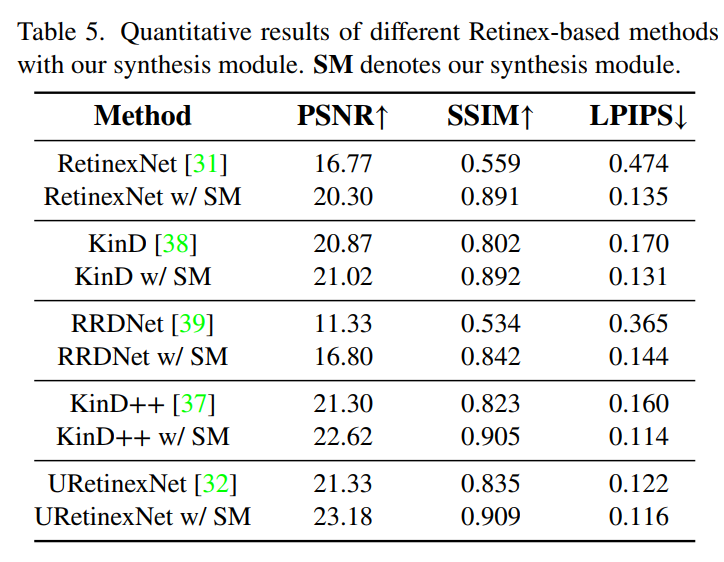
- 网络结构如上图所示,主要创新点在于,I和R估计出来后,并不直接相乘产生最终结果,而是concatenate到一起再用一个网络进一步处理成最终结果。从消融实验可以看到,这一模块作用还是很大的,用在很多retinex方法上都能产生性能的提高:
实验结果
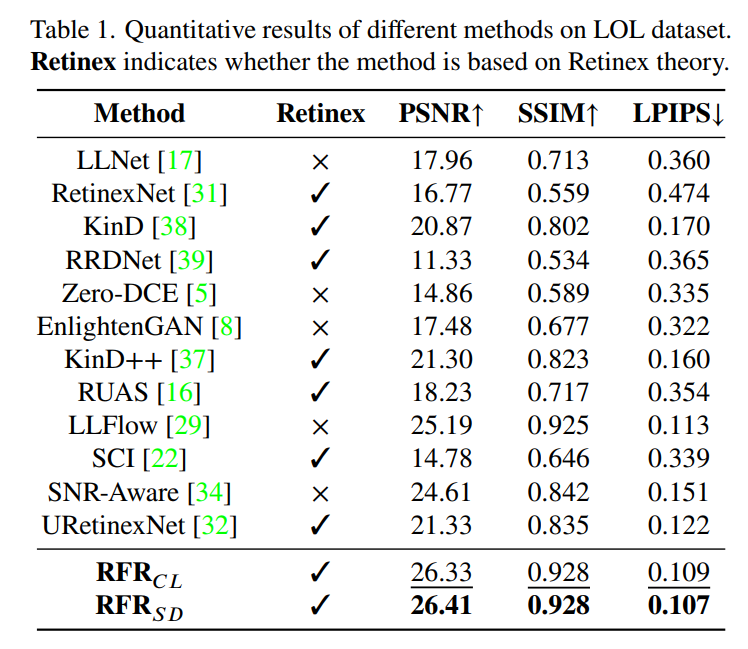
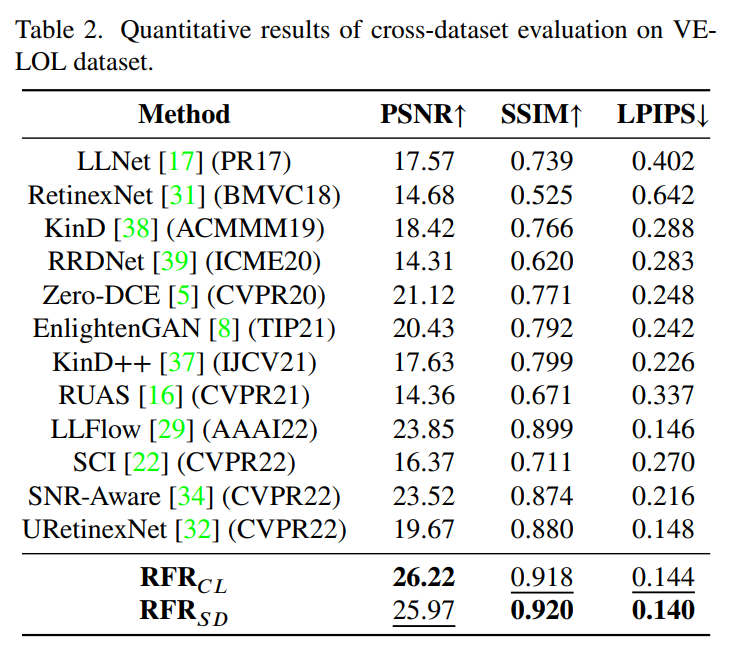
- 文章在LOL上训练,在LOL和VE-LOL两个数据集上测试。可以看到无论是对比学习还是蒸馏学习,训练出来的网络都具备较好的拟合能力(LOL)和泛化性(VE-LOL):
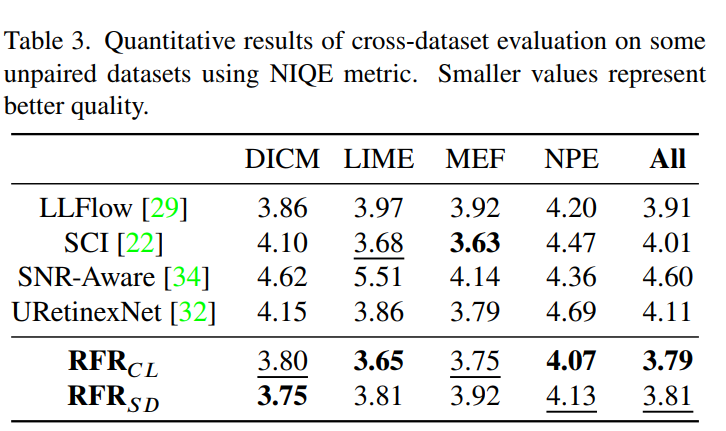
- NIQE指标也很不错:
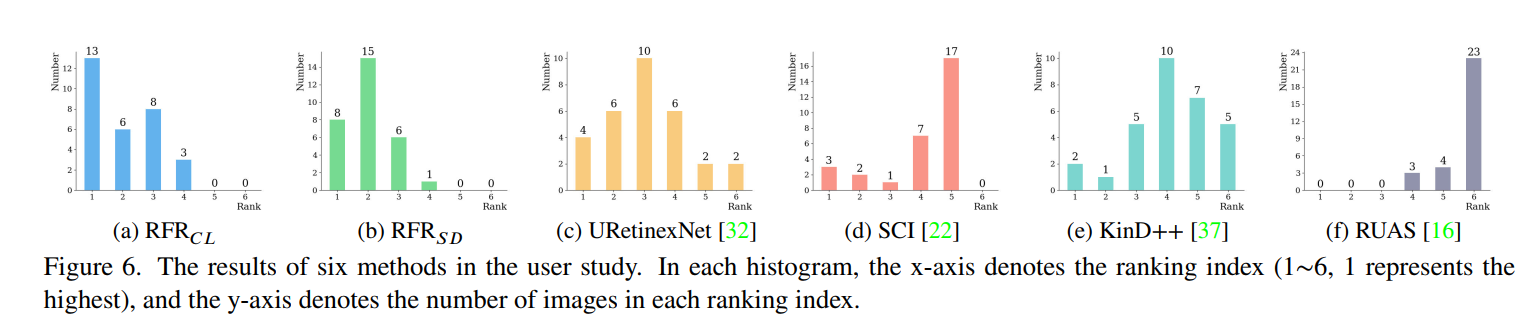
- 甚至还做了user study(LOL、VE-LOL、MEF、DICE、NPE、LIME里各选了5张一共30张图片,20个人进行评分):
- 视觉效果也挺好:

总结
- 我很喜欢这篇。利用自蒸馏和对比学习来提供额外监督虽然是个容易想到的idea,但是文章根据暗图增强任务进行了适应性的调整,最重要的是取得的效果也很好,实验也做得很充分。
- 怀疑点也不是没有,这里的主观评价实验,SCI效果有那么差吗,我自己实验出来效果还挺好的呀。还有就是,已经选了SCI还选RUAS干嘛,再选个别的嘛,enlightenGAN之类的。