AlexNet网络(2012年提出)
1. AlexNet网络详解
- AlexNet网络是2012年ILSVRC(ImageNet Large Scale Visual Recognition Challenge)竞赛(大规模视觉识别挑战赛)的冠军网络(分类赛冠军),分类准确率由传统的70%+提升到80%+。
出处:
- 作者:由Hinton和他的学生Alex Krizhevsky设计的。也是在2012年之后,深度学习开始迅速发展。使得卷积神经网络成为图像分类领域的核心算法模型。
- 论文原文:ImageNet Classification with Deep Convolutional Neural Networks
发展契机(得益于):
- 比LeNet更深的网络结构
- 抑制过拟合问题上的优秀表现
- 计算机硬件的飞速发展
贡献:
- 与LeNet相比,AlexNet结构更加复杂,并且各模块的功能更接近现在的神经网络
- AlexNet提出的ReLU激活函数、数据增广、随机失活等具有深远影响的网络构建模式与方法
- 并通过多GPU学习的方式,使得超大型神经网络模型成为现实。
地位:
- AlexNet网络让人们看到了深度学习在计算机视觉领域运用的可能性,所以在某种程度上来说,它开创了深度学习与计算机视觉融合的时代。
- 导致深度神经网络研究热潮的爆发
- 无论是从学术价值还是社会影响力上看,AlexNet可以被视为卷积神经网络发展历史中具有里程碑意义的成就
ImageNet数据集:是一个拥有超过22000个类别、1500万张图像的大规模数据集。
ILSVRC数据集:采用其中大约1000类不同目标、超过100万张高清图像。
(用于图像分类的数据集,是ImageNet数据集的子集)
- 训练集:1281167张已标注图片,分为1000个类别
- 验证集:50000张已标注图片
- 测试集:100000张未标注图片
- 该网络的亮点在于:
-
首次利用GPU进行网络加速训练(GPU的速度比CPU的速度快20-50倍)
AlexNet利用多GPU实现卷积神经网络的训练,大大提高了效率,使得更深、更大的网络能够实现。
目前,利用多GPU甚至GPU集群进行训练已经是实现超大规模神经网络的基本途径。
-
使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。
(自此以后,ReLU函数及其变种成了卷积神经网络激活函数的通用标准)
Sigmoid激活函数缺点:
- 求导的时候比较麻烦
- 当网络比较深的时候,会出现梯度消失的情况
ReLU就会解决这两个缺点
-
ReLU激活函数优点:
-
更简单。没有Sigmoid激活函数中的求幂运算
-
在不同的参数初始化方法下使模型更容易训练(这是由于当Sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数)
-
ReLU激活函数在正区间的梯度恒为1
(因此,若模型参数初始化不当,那么Sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练)
-
-
使用了LRN局部响应归一化
每一个卷积层中包含激励函数ReLU及局部响应归一化(Local Response Normalization,LRN)处理,然后再经过池化层处理,最后通过全连接层输出分类结果。)
LRN作用:用来对卷积层的输出进行规范化,促进网络收敛,增强泛化能力
注意:后来的研究中人们逐渐发现,局部相应归一化层的效果并不是很好,所以现在基本不再使用
-
随机失活
在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
原因:由于AlexNet是一个具有大量参数(6000万参数)的神经网络,如果不进行合适的正则化,网络很容易陷入严重的过拟合。
解决办法:随机失活是一种避免特征映射协同适应(coadatpion)的方法,也就是在每个训练周期中,随机选择一定比例的神经元并令其输出强制为0,使得这些神经元不再参与前向传播和反向传播。
- 由于神经元随机地关闭或者开启,这些神经元不再协同适应,而独立于其他神经元来学习特征。
- 从某种意义上说,每一个训练周期都是一个全新的网络结构,从而大大增强了网络的适应性。
- 此外,由于任何一个神经元都有可能失活,因此网络倾向于不依赖任一部分的神经元,导致学习出更加鲁棒、更加普适的特征,从而可以增强网络的泛化性能。
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。过度的拟合了训练数据,而没有考虑到泛化能力。
如图1(AlexNet在解决过拟合问题上进行大量工作,使其在大规模数据集上拥有优秀的表现)
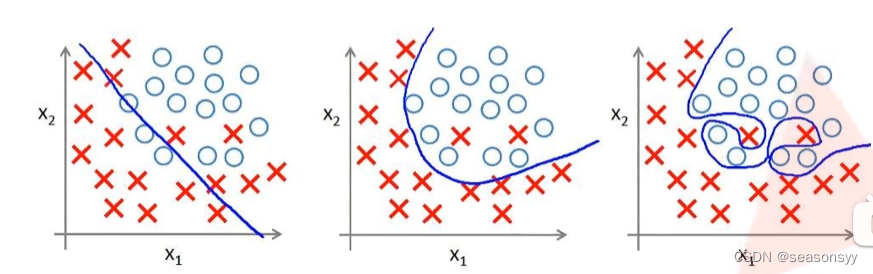
解决过拟合现象:
使用Dropout的方式在网络正向传播过程中随机失活一部分神经元。
如图2
>
图2左图:正常的全连接的正向传播过程,每个节点都与上层节点进行全连接
右图:使用了Dropout之后,在每一层当中随机失活一部分神经元。
可以理解为:Dropout操作变相的减少了网络训练的参数,从而达到减少网络过拟合现象的作用。
- 重叠池化操作
与LeNet池化层不同,采用的是无可学习参数的重叠池化操作。
普通池化操作的步长与核的尺寸一致,因此任意两步计算的区域并无重叠。
重叠池化操作是指在池化过程中会存在重叠的部分,即池化步长小于池化核的尺寸。
AlexNet中采用这样的做法,降低了错误率
- 数据增广(Data augmentation)
AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合)
定义:是指通过对现有数据进行处理而获得新的样本,并增大数据集容量的方法。
作用:数据增广可以丰富样本的多样性,通过裁剪、位移、缩放、翻转、颜色与亮度的调整等方法,增强网络对以上各种变化的鲁棒性。
操作:
- AlexNet将大小为256×256像素的图像裁剪成多个224×224像素的图像,裁剪位置随机。
- 对图像进行水平翻转,以便产生新的图像。通过随机裁剪和水平翻转,大大增加了训练样本的数量。
- 通过改变样本RGB三个通道中像素的值来产生新的样本,进一步增大了训练数据集,增强了模型对颜色和亮度变化的鲁棒性。
结果:实验证明,这有助于解决过拟合问题。目前,数据增广已经成为卷积神经网络应用过程中标准的步骤。
2.AlexNet网络结构
网络结构图如图3所示
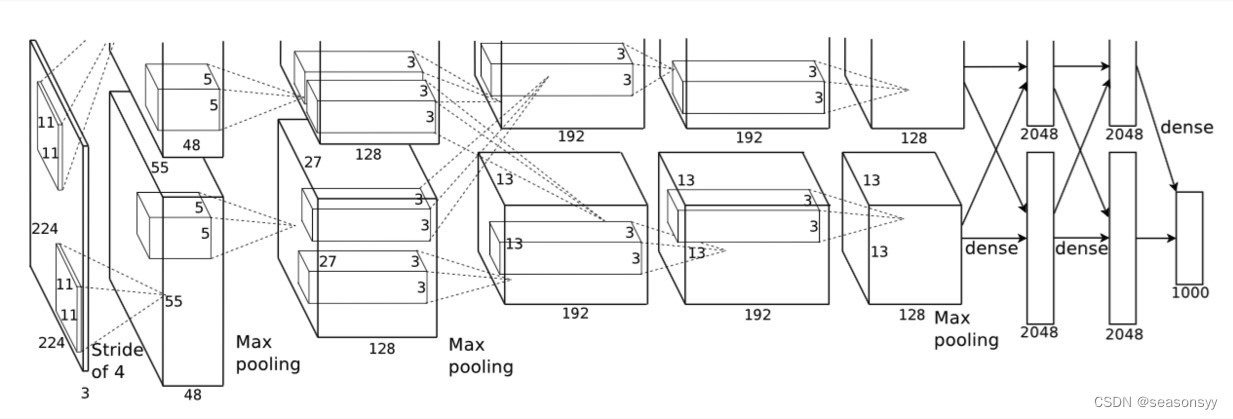
图3
AlexNet包含8层变换,其中有5个卷积层,3个全连接层(2个全连接隐藏层、1个全连接输出层),共有大约6000万个参数。
每一个卷积层中包含激励函数ReLU及局部响应归一化(Local Response Normalization,LRN)处理,然后再经过池化层处理,最后通过全连接层输出分类结果。)
LRN作用:用来对卷积层的输出进行规范化,促进网络收敛,增强泛化能力
注意:后来的研究中人们逐渐发现,局部相应归一化层的效果并不是很好,所以现在基本不再使用
由于早期显存的限制,最早的AlexNet使用双数据流的设计使一块GPU只需处理一半模型。
幸运的是,显存在过去几年得到了长足的发展,现在通常不需要这样的特别设计了。
这个网络可以看成两部分,因为作者使用了两个GPU进行并行运算。
我们只需要看一块就行,因为上下两个部分是一样的。
Input:从图3中可以看出,输入层的尺寸是224×224×3 ,但是,尺寸设置成227×227×3会更合理。所以后面以227×227×3为准。
注:图3所示的网络结构其实是基于两个GPU上的结构,所以所有的参数都是对半分开的;而下表则是将网络结构看成一个整体。
| layer_name | input | kernel_size | stride | padding | output | 参数量 |
|---|---|---|---|---|---|---|
| Input | 227×227×3 | 227×227×3 | ||||
| Conv1 | 227×227×3 | 11×11×96 | 4 | 0 | (227-11+0)/4+1=55 55×55×96 | (11×11 ×3+1) ×96 |
| MaxPooling1 | 55×55×96 | 3×3 | 2 | 0 | (55-3+0)/2+1=27 27×27×96 | |
| Conv2 (Same convolution) | 27×27×96 | 5×5×256 | 1 | 2 | (27-5+2×2)/1+1=27 27×27×256 | (5×5×96+1)×256 |
| MaxPooling2 | 27×27×256 | 3×3 | 2 | 0 | (27-3+0)/2+1=13 13×13×256 | |
| Conv3 (Same convolution) | 13×13×256 | 3×3×384 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×384 | (13×13×256+1)×384 |
| Conv4 (Same convolution) | 13×13×384 | 3×3×384 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×384 | (13×13×384+1)×384 |
| Conv5 | 13×13×384 | 3×3×256 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×256 | (3×3×384+1)×256 |
| MaxPooling3 | 13×13×256 | 3×3 | 2 | 0 | (13-3+0)/2+1=6 6×6×256 | |
| FC6 | 6×6×256=9216 | 4096 | 6×6×256×4096+1 | |||
| FC7 | 4096 | 4096 | 4096×4096+1 | |||
| FC8(Softmax) | 4096 | 1000 | 4096×1000+1 |
AlexNet第一层卷积层窗口大小为11×11。因为ImageNet中绝大多数图像的高和宽均是MNIST图像的高和宽的10倍以上,ImageNet图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。
AlexNet使用的卷积通道数也数十倍于LeNet中的卷积通道数。
AlexNet通过丢弃法控制全连接层的模型复杂度,而LeNet没有使用丢弃法
Same convolution:进行Same卷积,Same就是一种处理后特征图的尺寸不变的卷积(通道数可能改变)
Same卷积:
本质上仍是一种普通卷积,计算公式仍然是
o u t p u t = [ ( i n p u t − f i l t e r S i z e + 2 ∗ p a d d i n g ) / s t r i d e ] + 1 output=[(input-filterSize+2*padding)/stride]+1 output=[(input−filterSize+2∗padding)/stride]+1
好处:没有在卷积之后缩小图像尺寸,也没有放过原图像中任何一个信息进行卷积,所以提取出的特征图会更加完整。启发:当构建属于自己的网络的卷积神经网络的时候,在合适的时候采取Same卷积方法,可能会带来很好的性能,且代码十分简单,只需要按照Same卷积的要求设置响应的参数即可。
# 利用nn包构建采用Same卷积的卷积层 self.conv1=nn.Sequential( nn.Conv2d ( in_channels=1, out_channels=6, kernel_size=3, stride=1, # 步长一定要设置为1 padding=1 # padding设置成1就实现了加边界 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2) )输出层采用了softmax分类器,最终输出1000种分类的各自可能得概率。由于Softmax分类器的优势以及网络的良好特性,训练好的AlexNet模型不仅能区分出图像内容是否为猫,甚至还能区分猫的品种。
(AlexNet中最后输出1000种分类,即使每个输出的大小不同,但是经过Softmax分类器之后,输出的范围都回到了0~1,这也是采用了Softmax的好处之一)Softmax是Sigmoid二分类上的推广,只需要对数据进行两步处理:
- 首先利用指数函数将多分类的结果映射到零到正无穷
- 然后采取归一化方法得到结果映射的相应概率
假设现在需要对输出进行n种分类,那么该输出经过Softmax分类器之后就会得到n个概率,如下:
上式体现了Softmax分类器的本质:
- 分子代表处理的第一步:利用指数函数将多分类的结果映射到零到正无穷
- 分母:代表把所有的结果相加,对分子进行归一化
例子:假设网络需要输出一个三分类的结果,在一次训练过程中,网络输出了[12 26 -9]这样一个行向量,经过Softmax分类器的计算过程如下:
P2最接近1,表示第二种分类的可能性极大,已经接近100%,所以我们认为网络输出的分类结果为第二种分类。
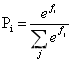

3.AlexNet代码
参考:
b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62
github:https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
代码位置:\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\pytorch_classification\Test2_alexnet
说明:这一部分是运行AlexNet代码
本次训练所需要的数据集:花分类数据集
这个数据集一共有5个类别:
- daisy雏菊
- dandelion蒲公英
- roses玫瑰:
- sunflower向日葵
- tulips郁金香
下载花分类数据集步骤如下:
- (1)在data_set文件夹下创建新文件夹"flower_data"
- (2)点击链接下载花分类数据集 https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
- (3)解压数据集到flower_data文件夹下
- (4)执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val
├── flower_data
├── flower_photos(解压的数据集文件夹,3670个样本)
├── train(生成的训练集,3306个样本) 9 :
└── val(生成的验证集,364个样本) 1
在deep-learning-for-image-processing-master\data_set目录下进入到powershell命令里面(在此目录下按住shift点击右键会出现进入选项)
然后输入“python split_data.py”,点击回车,就会运行这个脚本,把训练集按照9:1分成训练集和验证集。
如图4
图4

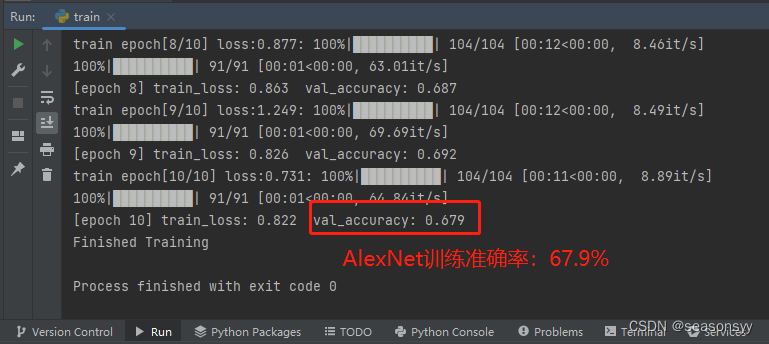
运行结果:
运行train.py之后,会把效果最好的保存为Alex.pyh
验证:弄一张图片放到这个文件夹中,然后注意图片的路径
然后运行predict.py文件
AlexNet训练准确率:67.9%
运行错误:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
参考ChatGPT
错误原因:
这个错误是因为在程序中链接了多个OpenMP运行时库,这可能会降低性能或导致错误的结果。
解决办法:
最好的解决方法是确保只有一个OpenMP运行时库被链接到进程中,检查编译选项和链接库的设置,确保没有重复链接OpenMP库。例如避免在任何库中进行静态链接OpenMP运行时。作为一种不安全、不支持、未记录的解决方法,您可以设置环境变量KMP_DUPLICATE_LIB_OK=TRUE来允许程序继续执行,但这可能会导致崩溃或产生错误的结果。更多信息请参考http://www.intel.com/software/products/support/。
解决步骤:
-
如果您使用的是Visual Studio编译器,可以在项目属性的"C/C++" -> “代码生成"中将"Open MP支持"设置为"是”。
-
如果您在使用其他编译器,请参考该编译器的文档,查找关于OpenMP的配置选项,并确保只链接一个OpenMP运行时库。
-
如果以上步骤没有解决问题,您可以尝试设置环境变量KMP_DUPLICATE_LIB_OK=TRUE。请注意,这是一个不受支持的解决方法,可能会导致其他问题。
我使用的是pycharm编译器
在PyCharm编译器中,您可以尝试以下步骤来解决这个问题:
-
打开PyCharm,进入您的项目。
-
在顶部菜单栏中选择"Run" -> “Edit Configurations”。
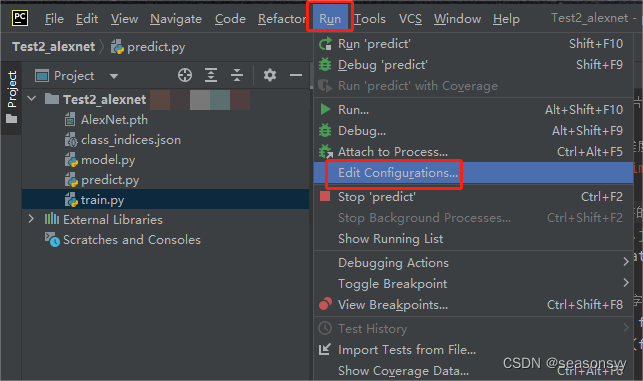
图5
-
在弹出的对话框中,找到您要运行的配置文件,并选择它。
-
在右侧窗格中的"Environment variables"部分,添加一个新的环境变量。
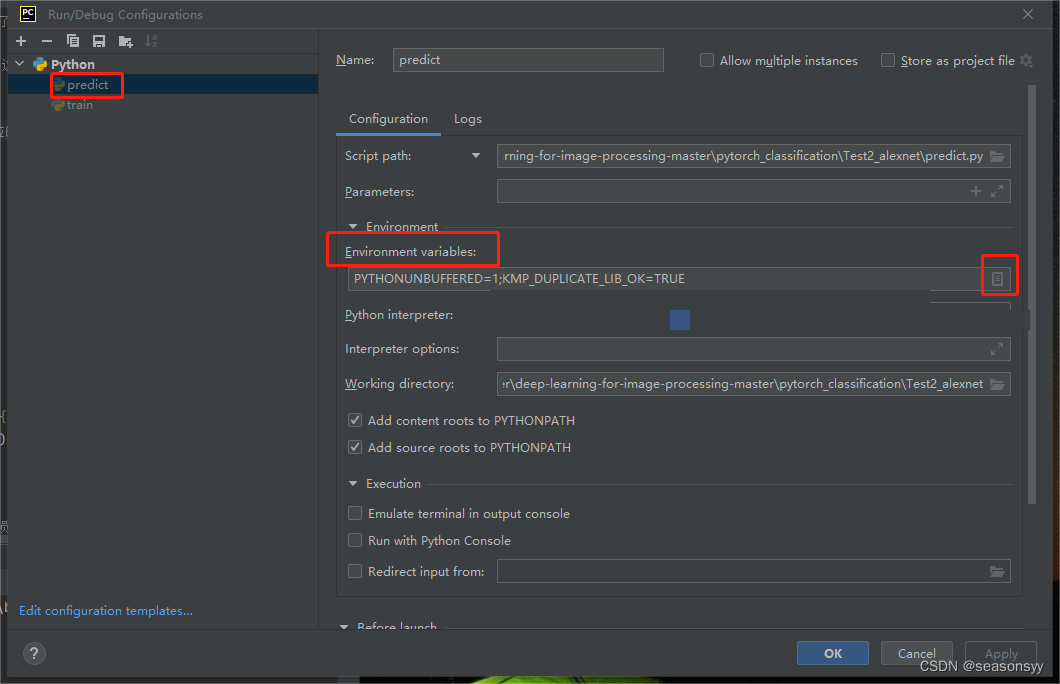
图6
- 将变量名设置为
KMP_DUPLICATE_LIB_OK,将变量值设置为TRUE。
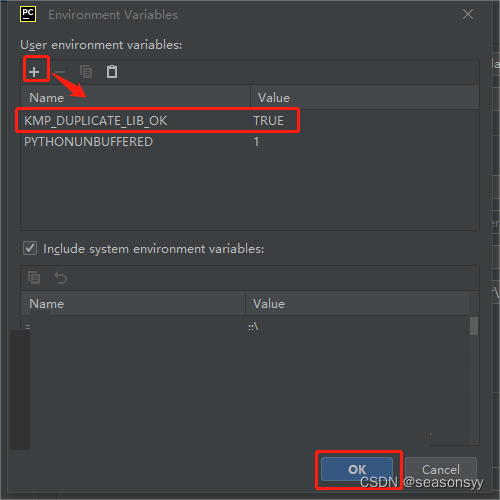
图7
-
单击"OK"保存更改。
-
现在再次尝试运行您的程序,看看是否仍然出现相同的错误。将此环境变量设置为"TRUE"可能会使程序继续执行,但请注意,这可能会导致崩溃或产生错误的结果。
如果通过上述步骤仍无法解决该问题,请查阅PyCharm的文档或与PyCharm支持团队联系以获得更准确的帮助和指导。
解决结果:成功
预测结果如图所示:(图8-图9)
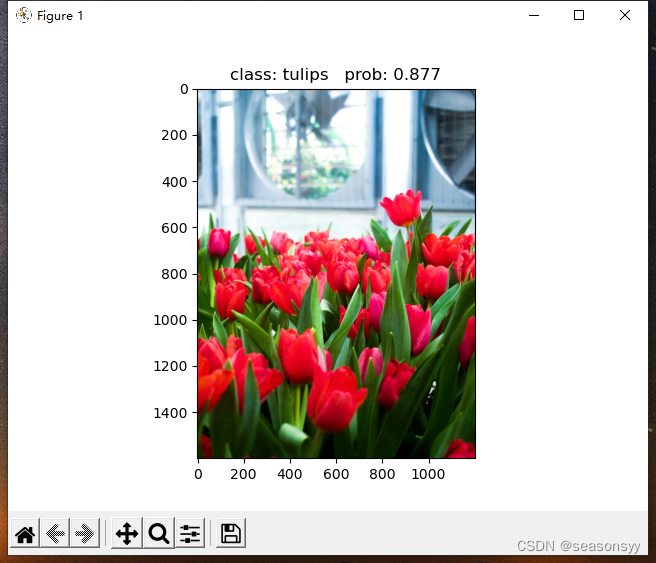
图8
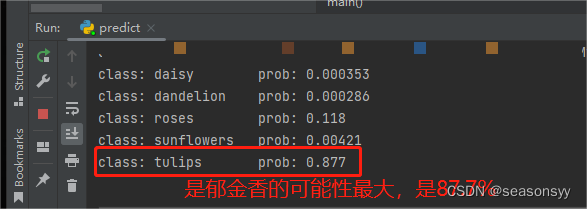
图9
4.如何使用AlexNet网络训练自己的数据集
参考:
b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1W7411T7qc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62
github:https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
我们刚才运行的AlexNet代码用的是flower数据集,我们可以把下面地址的flower_photos这个文件夹里面的5种类别删掉,然后换成自己的数据集,调用split.py页面,将其按照9:1的比例分成训练集和测试集,然后使用train.py进行训练即可。
flower数据集:
deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\data_set\flower_data\flower_photos
需要修改的地方:
train.py中:图10

图10
predict.py中:图11

图11
5.参考文献
- 《深度学习与神经网络》 赵眸光 编著
出版社:电子工业出版社 2023年1月第一版
ISBN: 978-7-121-44429-6
- 《深度卷积神经网络 原理与实践》周浦城 李从利 王勇 韦哲 编著
出版社:北京:电子工业出版社,2020.10
ISBN: 978-7-121-39663-2
- 《Python神经网络 入门与实践》 王凯 编著
出版社:北京大学出版社
ISBN: 9787301316290
- b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62