第一部分讲解网络的构建,建立的方式和Tensorflow的官方中文教程的方式略微不同,由于网路结构小,各个隐层并未放入命名空间中,但逻辑顺序依然一样。
1.Alexnet
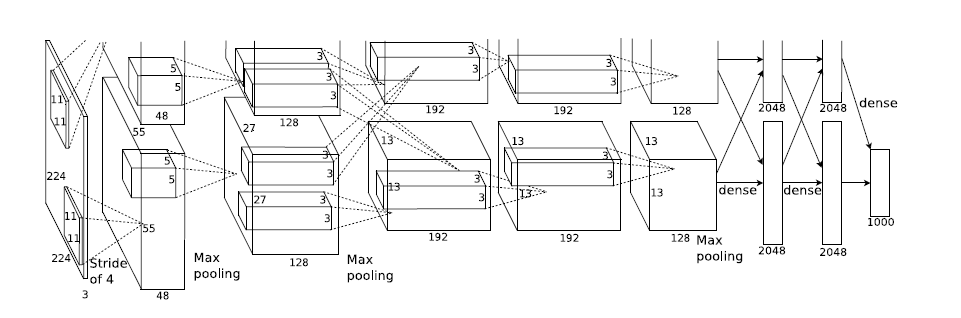
用一张图先展示一下CNN的经典网络结构Alexnet,可以看出它由五层卷积、三层池化和两层全连接组成,我会在网络中加入BN层。
2.TensorFlow运作方式
1.输入与占位符(Inputs and Placeholders) :placeholder_inputs()函数将生成两个tf.placeholder操作,定义传入图表中的shape参数,shape参数中包括batch_size值
2.构建图表 :inference()函数会尽可能地构建图表,做到返回包含了预测结果(output prediction)的Tensor。它接受图像占位符为输入,在此基础上借助ReLu(Rectified Linear Units)激活函数(也可替换成其他激活函数),构建一对完全连接层(layers),以及一个有着n个结点(n一般是你的分类数目)、指明了输出logtis模型的线性层。每一层都创建于一个唯一的tf.name_scope之下,创建于该作用域之下的所有元素都将带有其前缀,使用如:
with tf.name_scope('hidden1') as scope:
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases 3.损失函数:如果你的标签是one-hot编码则可以省略这一步骤,如果不是,tensorflow也可以帮你转换成one-hot编码,例如,如果类标识符为“3”,那么该值就会被转换为:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
batch_size = tf.size(labels)
labels = tf.expand_dims(labels, 1)
indices = tf.expand_dims(tf.range(0, batch_size, 1), 1)
concated = tf.concat(1, [indices, labels])
onehot_labels = tf.sparse_to_dense(
concated, tf.pack([batch_size, NUM_CLASSES]), 1.0, 0.0)之后添加一个tf.nn.softmax_cross_entropy_with_logits操作,用来比较inference()函数与1-hot标签所输出的logits Tensor,并使用tf.reduce_mean函数,计算batch维度(第一维度)下交叉熵(cross entropy)的平均值,将将该值作为总损失。
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits,
onehot_labels,
name='xentropy')
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')3.网络结构
上述内容是tensorflow中文教程的搬运,详细的大家可以去看,下面的代码是可以直接用的,但是要修改代码中的数据尺寸,而且还需要配合之后的训练文件才可以使用。
# -*- coding: utf-8 -*-
import tensorflow as tf
class Network:
def weight_variable(self,shape): # weight
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(self,shape): # bias initial
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(self,x, W): # convolution
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME")
#strides矩阵中间两个是滑动步长
def max_pool(self,x): # pooling
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# ksize:池化窗口设置 同上 strides
# ksize=[1,2,2,1] 每次池化一个批次,池化窗口2*2,每次池化一个频道
# 由于池化窗口的设置为2*2,所以池化窗口的移动也是 2,2
def __init__(self):
self.BITCH_SIZE = 1
self.IMAGE_SIZE_X = 60
self.IMAGE_SIZE_Y = 60
self.CHANNEL = 3
self.epsilon = 1e-4
self.class_num = 2
self.tf_x = tf.placeholder(tf.float32, [self.BITCH_SIZE,self.IMAGE_SIZE_X,self.IMAGE_SIZE_Y,self.CHANNEL])
self.tf_y = tf.placeholder(tf.float32,[self.BITCH_SIZE,self.class_num])
self.learning_rate = tf.placeholder(tf.float32)
# 第一层 卷积+归一+池化
self.W_conv1 = self.weight_variable([6, 6, 3, 64])
self.b_conv1 = self.bias_variable([64])
self.h_conv1 = self.conv2d(self.tf_x, self.W_conv1) + self.b_conv1 # x*W+b
#下面几步为BN层
axis1 = list(range(len(self.h_conv1.get_shape()) - 1))
batch_mean, batch_var = tf.nn.moments(self.h_conv1, axis1, keep_dims=True)
shift = tf.Variable(tf.zeros([64]))
scale = tf.Variable(tf.ones([64]))
BN_out1 = tf.nn.relu(tf.nn.batch_normalization(self.h_conv1, batch_mean, batch_var, shift, scale, self.epsilon))
h_pool1 = self.max_pool(BN_out1) # max pooling
# 第二层 卷积+归一
self.W_conv2 = self.weight_variable([6, 6, 64, 128])
self.b_conv2 = self.bias_variable([128])
h_conv2 = self.conv2d(h_pool1, self.W_conv2) + self.b_conv2 # x*W+b
axis2 = list(range(len(h_conv2.get_shape()) - 1))
batch_mean, batch_var = tf.nn.moments(h_conv2, axis2, keep_dims=True)
shift = tf.Variable(tf.zeros([128]))
scale = tf.Variable(tf.ones([128]))
BN_out2 = tf.nn.relu(tf.nn.batch_normalization(h_conv2, batch_mean, batch_var, shift, scale, self.epsilon))
# 第三层 卷积+归一
self.W_conv3 = self.weight_variable([3, 3, 128, 256])
self.b_conv3 = self.bias_variable([256])
h_conv3 = self.conv2d(BN_out2, self.W_conv3) + self.b_conv3 # x*W+b
axis3 = list(range(len(h_conv3.get_shape()) - 1))
batch_mean, batch_var = tf.nn.moments(h_conv3, axis3, keep_dims=True)
shift = tf.Variable(tf.zeros([256]))
scale = tf.Variable(tf.ones([256]))
BN_out3 = tf.nn.relu(tf.nn.batch_normalization(h_conv3, batch_mean, batch_var, shift, scale, self.epsilon))
# 第四层 卷积+归一
self.W_conv4 = self.weight_variable([3, 3, 256, 512])
self.b_conv4 = self.bias_variable([512])
h_conv4 = self.conv2d(BN_out3, self.W_conv4) + self.b_conv4 # x*W+b
axis4 = list(range(len(h_conv4.get_shape()) - 1))
batch_mean, batch_var = tf.nn.moments(h_conv4, axis4, keep_dims=True)
shift = tf.Variable(tf.zeros([512]))
scale = tf.Variable(tf.ones([512]))
BN_out4 = tf.nn.relu(tf.nn.batch_normalization(h_conv4, batch_mean, batch_var, shift, scale, self.epsilon))
# 第五层 卷积+归一+池化
self.W_conv5 = self.weight_variable([3, 3, 512, 1024])
self.b_conv5 = self.bias_variable([1024])
h_conv5 = self.conv2d(BN_out4, self.W_conv5) + self.b_conv5
axis5 = list(range(len(h_conv5.get_shape()) - 1))
batch_mean, batch_var = tf.nn.moments(h_conv5, axis5, keep_dims=True)
shift = tf.Variable(tf.zeros([1024]))
scale = tf.Variable(tf.ones([1024]))
BN_out5 = tf.nn.relu(tf.nn.batch_normalization(h_conv5, batch_mean, batch_var, shift, scale, self.epsilon))
h_pool5 = self.max_pool(BN_out5) # max pooling
# 第六层 全连层,输出为1024
self.W_fcl = self.weight_variable([ 15 * 1024 * 15, 1024]) # 此时,照片的尺寸减小到15*15
self.b_fcl = self.bias_variable([1024])
h_pool5_flat = tf.reshape(h_pool5, [-1, 15 * 15 * 1024]) # 将第二个卷基层铺平
h_fcl = tf.nn.relu(tf.matmul(h_pool5_flat, self.W_fcl) + self.b_fcl)
# dropout层
self.keep_prob = tf.placeholder(tf.float32) # keep_prob: 一个神经元的输出在dropout中保持不变的概率。
h_fcl_drop = tf.nn.dropout(h_fcl,self.keep_prob) # dropout
# 第七层
self.W_fc2 = self.weight_variable([1024, 1024])
self.b_fc2 = self.bias_variable([1024])
h_fc2 = tf.nn.relu(tf.matmul(h_fcl_drop, self.W_fc2) + self.b_fc2)
# dropout层
h_fc2_drop = tf.nn.dropout(h_fc2,self.keep_prob) # dropout
# 第八层
self.W_fc3 = self.weight_variable([1024, 2])
self.b_fc3 = self.bias_variable([2])
self.y_conv = tf.nn.softmax(tf.matmul(h_fc2_drop, self.W_fc3) + self.b_fc3) # 套上softmax
#定义损失函数
self.cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=self.tf_y,logits=self.y_conv)
self.train = tf.train.AdamOptimizer(self.learning_rate).minimize(self.cross_entropy)
self.correct_pre = tf.equal(tf.argmax(self.y_conv, 1), tf.argmax(self.tf_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre, tf.float32))
self.summary_accuracy = tf.summary.scalar('cross_entropy', self.accuracy)
self.merged = tf.summary.merge_all()