1. ReLU Nonlinearity
标准的L-P神经元的输出一般使用tanh 或 sigmoid作为激活函数。但是这些饱和的非线性函数在计算梯度的时候都要比非饱和的现行函数f(x)=max(0,x)慢很多,在这里称为 Rectified Linear Units(ReLUs)。在深度学习中使用ReLUs要比等价的tanh快很多。
一般神经元的激活函数会选择sigmoid函数或者tanh函数,然而Alex发现在训练时间的梯度衰减方面,这些非线性饱和函数要比非线性非饱和函数慢很多。在AlexNet中用的非线性非饱和函数是f=max(0,x),即ReLU。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
2. LRN局部响应归一化
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。
ReLU本来是不需要对输入进行标准化,但本文发现进行局部标准化能提高性能。
其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LPN形成了一种横向抑制机制。
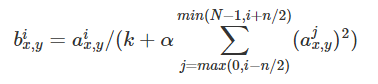
3. Overlapping Pooling
池层是相同卷积核领域周围神经元的输出。池层被认为是由空间距离s个像素的池单元网格的组成。也可以理解成以大小为步长对前面卷积层的结果进行分块,对块大小为的卷积映射结果做总结,这时有。然而,Alex说还有的情况,也就是带交叠的Pooling,顾名思义这指Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用 带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用。
4.数据增益
增强图片数据集最简单和最常用的方法是在不改变图片核心元素(即不改变图片的分类)的前提下对图片进行一定的变换,比如在垂直和水平方向进行一定的唯一,翻转等。
AlexNet用到的第一种数据增益的方法:是原图片大小为256256中随机的提取224224的图片,以及他们水平方向的映像。
第二种数据增益的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到 方法为PCA。对于图像每个像素,增加以下量 :
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。此方法降低top-1错误率1%。
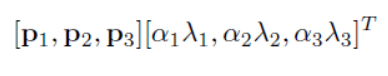
5.Dropout
结合多个模型的预测值是减少错误的有效方法,但是对于训练时间用好几天的大型神经网络太耗费时间。Dropout是有效的模型集成学习方法,具有0.5的概率讲隐藏神经元设置输出为0。运用了这种机制的神经元不会干扰前向传递也不影响后续操作。因此当有输入的时候,神经网络采样不用的结构,但是这些结构都共享一个权重。这就减少了神经元适应的复杂性。测试时,用0.5的概率随机失活神经元。dropout减少了过拟合,也使收敛迭代次数增加一倍。
6.学习细节
AlexNet训练采用的是随机梯度下降 (stochastic gradient descent),每批图像大小为128,动力为0.9,权重衰减为0.005
