该图是上下两部分,使用了两个GPU
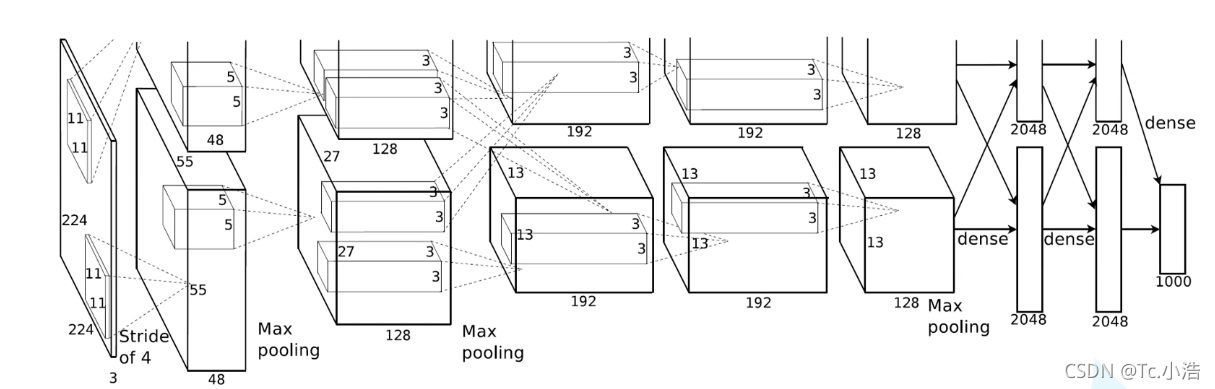
网络层分析
首先这幅图分为上下两个部分的网络,论文中提到这两部分网络是分别对应两个GPU,只有到了特定的网络层后才需要两块GPU进行交互,这种设置完全是利用两块GPU来提高运算的效率,其实在网络结构上差异不是很大。为了更方便的理解,我们假设现在只有一块GPU或者我们用CPU进行运算,我们从这个稍微简化点的方向区分析这个网络结构。网络总共的层数为8层,5层卷积,3层全连接层。
-
第一层:卷积层1,输入为 224 × 224 × 3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11 × 11 × 3; stride = 4, stride表示的是步长, padding = 0, 表示不扩充边缘;
卷积后的图形大小是怎样的呢?
wide = (224 + 2 * padding - kernel_size) / stride + 1 = 54
height = (224 + 2 * padding - kernel_size) / stride + 1 = 54
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map
最终第一层卷积的总输出为55x55x96,一个GPU的输出为55x55x48 -
第二层:卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5 × 5 × 48; pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3), stride = 2;
-
第三层:卷积3, 输入为第二层的输出,卷积核个数为384, kernel_size = (3 × 3 × 256), padding = 1, 第三层没有做LRN和Pool
-
第四层:卷积4, 输入为第三层的输出,卷积核个数为384, kernel_size = (3 × 3), padding = 1, 和第三层一样,没有LRN和Pool
-
第五层:卷积5, 输入为第四层的输出,卷积核个数为256, kernel_size = (3 × 3), padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
-
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
AlexNet网络的亮点:
- 首次利用CPU进行网络加速训练
- 使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数
- 使用了LRN局部响应归一化
- 在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
过拟合
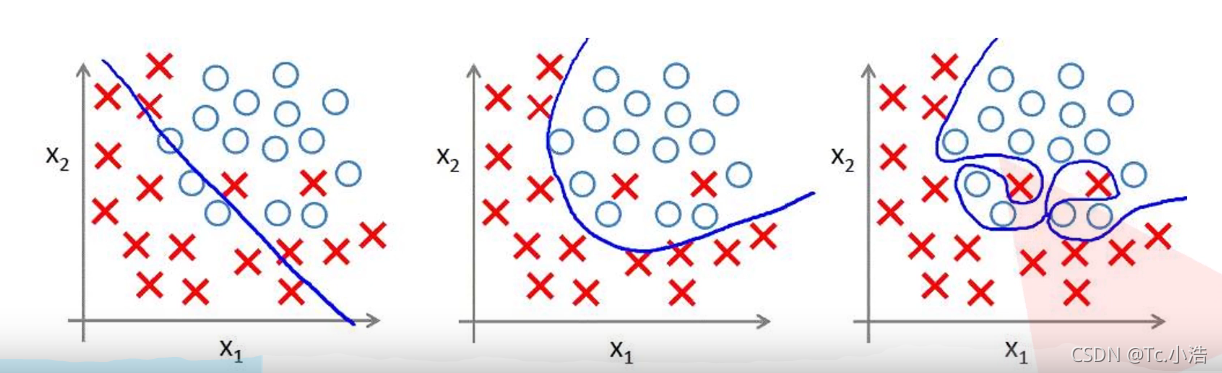
根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集(在第三个图中,训练得到的函数100%区分类别),但对新数据的测试集预测结果差。过度的拟合了训练数据,而没有考虑到泛化能力。
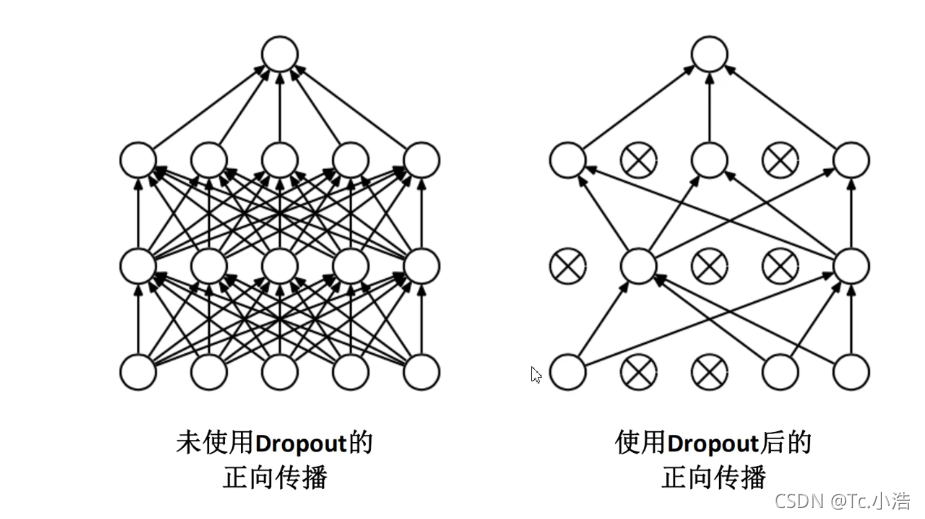
解决过拟合(Dropout)
使用Dropout的方式在网络正向传播过程中随机失活一部分神经元,变相的减少了网络训练的参数。
代码
import torch
from torch import nn
class AlexNet(nn.Module):
def __init__(self,num_classes=1000,init_weights=False):
super(AlexNet,self).__init__()
#使用nn.Sequential进行打包
self.features=nn.Sequential(
#第一层
nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
#第二层
nn.Conv2d(48,128,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
#下采样
nn.MaxPool2d(kernel_size=3,padding=2),
#第三层
nn.Conv2d(128,192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
#第四层
nn.Conv2d(192,192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
#第五层
nn.Conv2d(192,128,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,padding=2)
)
self.classifier=nn.Sequential(
#防治过拟合,p表示随机失活的比例
nn.Dropout(p=0.5),
#第六层全连接
nn.Linear(128*6*6,2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
#第七层全连接
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
#第八层全连接
nn.Linear(2048,num_classes)
)
if init_weights:
self._initialize_weights()
#向前传播
def forward(self,x):
x=self.features(x)
#展平处理,batch,channel,w,h,从channel开始展平
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
def _initialize_weights(self):
#self.modules会迭代定义的每一层网络结构
for m in self.modules():
#isinstance表示m是否是给定的nn.Conv2d
if isinstance(m,nn.Conv2d):
#kaiming_normal_初始化变量方法
nn.init.kaiming_normal_(m.weight,mode='fan_out')
#偏置不为None,设置为0
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
#正态分布,均值为0,方差为0.01
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias,0)