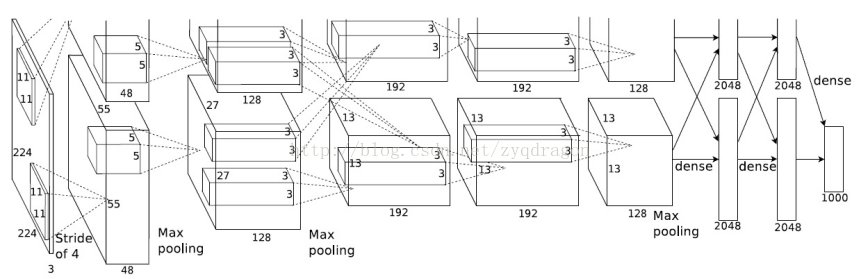
图中所给关于卷积核的尺寸来自于Alex在2012年发表的经典文章。
Alex在2012年提出的alexnet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。AlexNet 该模型一共分为八层,5个卷积层,,以及3个全连接层,在每一个卷积层中包含了激励函数RELU以及局部响应归一化(LRN)处理,然后在经过降采样(pool处理),下面我们对每一层开始详细的分析。以下代码块来自Caffe源码:
1.conv1层:
layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 kernel_size: 11 stride: 4 } } layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } layer { name: "norm1" type: "LRN" bottom: "conv1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "pool1" type: "Pooling" bottom: "norm1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 } }
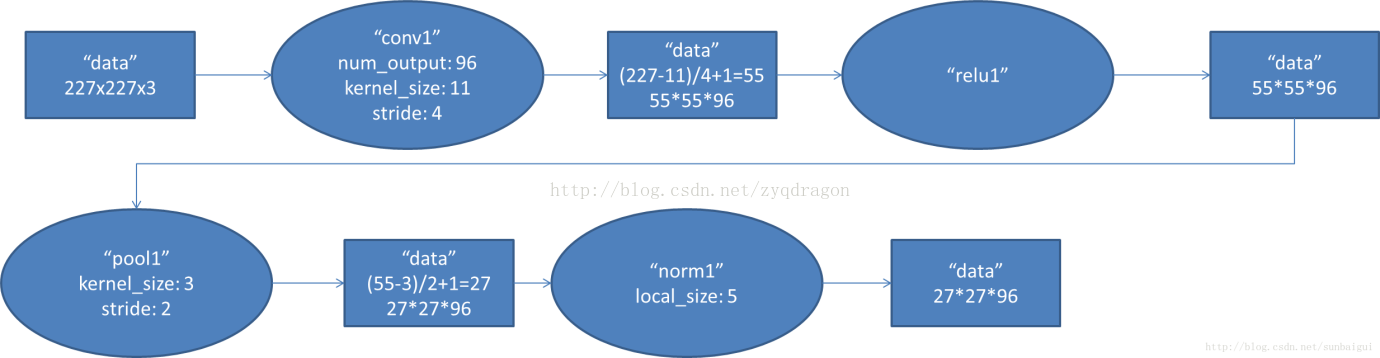
1.输入的图像为彩色图片(RGB图像):224 * 224 * 3 ,实际上会经过预处理变为227 * 227 * 3,这个图像被96个大小规格为11 * 11 * 3(同样也是三通道了)的卷积核,进行特征提取,96个卷积核分成2组(因为采用了2个GPU服务器进行处理),每组48个卷积核;
2.卷积核对原始图像的每次卷积都生成一个新的像素。卷积核沿原始图像的x轴方向和y轴方向两个方向移动,stride移动的步长是4个像素。因此,卷积核在移动的过程中会生成(227-11)/4+1=55个像素(卷积的计算方式,详见本博主以前发的lenet网络),注意这里提取到的特征图是彩色的.这样得到了96个55 * 55大小的特征图了,并且是RGB通道的.96个卷积核分成2组,每组48个卷积核。对应生成2组55 * 55 * 48的卷积后的像素层数据。这些像素层经过relu1单元的处理,生成激活像素层,尺寸仍为2组55 * 55 * 48的像素层数据。
需要特别说明的一点是,我们在使用卷积核和数据进行卷积时(ps: 卷积就是[1,2,3][1,1,1] = 11+21+31=6,也就是对应相乘并求和),而且我们使用的卷积核尺寸是11 * 11,也就是采用的是局部链接,每次连接11 * 11大小区域,然后得到一个新的特征,再次基础上再卷积,再得到新的特征,也就是将传统上采用的全链接的浅层次神经网络,通过加深神经网路层次也就是增加隐藏层,然后下一个隐藏层中的某一个神经元是由上一个网络层中的多个神经元乘以权重加上偏置之后得到的,也就是所谓的权值共享,通过这来逐步扩大局部视野,(形状像金字塔),最后达到全链接的效果. 这样做的好处是节约内存,一般而言,节约空间的同时,消耗时间就会相应的增加,但是近几年的计算机计算速度的提升,如GPU.已经很好的解决了这个时间的限制的问题.
3.使用RELU激励函数,来确保特征图的值范围在合理范围之内,比如{0,1},{0,255},这些像素层经过relu1单元的处理,生成激活像素层,尺寸仍为2组55 * 55 * 48的像素层数据。
4.这些像素层经过pool运算(最大池化)的处理,池化运算的尺度为3 * 3,stride移动的步长为2,则池化后图像的尺寸为(55-3)/2+1=27。 即池化后像素的规模为27 * 27 * 96;
5.然后经过归一化处理,归一化运算的尺度为5 * 5;第一卷积层运算结束后形成的像素层的规模为27 *2 7 * 96。分别对应96个卷积核所运算形成。这96层像素层分为2组,每组48个像素层,每组在一个独立的GPU上进行运算。
2.conv2
layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 2 kernel_size: 5 group: 2 } } layer { name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" } layer { name: "norm2" type: "LRN" bottom: "conv2" top: "norm2" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 } } layer { name: "pool2" type: "Pooling" bottom: "norm2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 } }
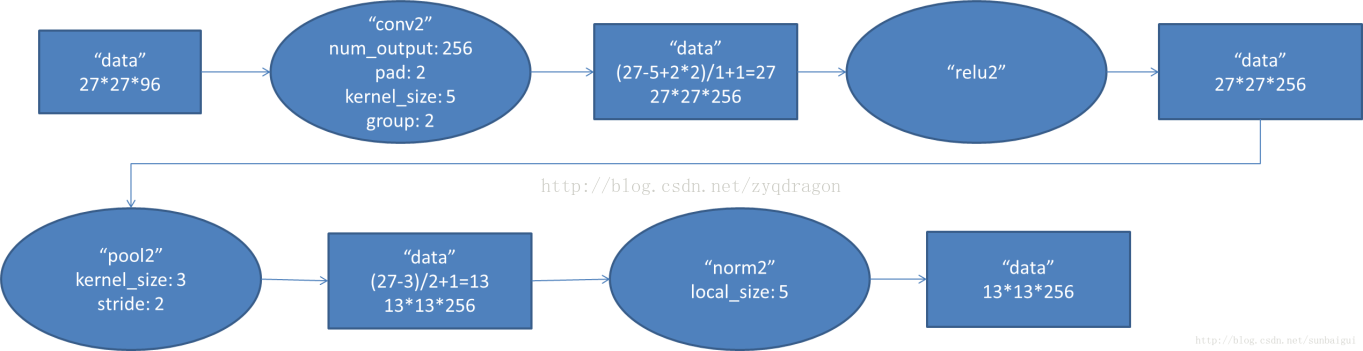
1.conv2中使用256个5 * 5大小的过滤器filter对96 * 27 * 27个特征图,进行进一步提取特征第二层输入数据。第一层输出的27 * 27 * 96的像素层,为便于后续处理,每幅像素层的左右两边和上下两边都要填充2个像素27 * 27 * 96的像素数据分成27 * 27 * 48的两组像素数据,两组数据分别再两个不同的GPU中进行运算。每组像素数据被5 * 5 * 48的卷积核进行卷积运算,卷积核对每组数据的每次卷积都生成一个新的像素。在卷积的过程中,因为步长是1个像素。因此,卷积核在移动的过程中会生成(27-5+2 * 2)/1+1=27个像素。(加上上下、左右各填充的2个像素,即生成27个像素,),行和列的27 * 27个像素形成对原始图像卷积之后的像素层。共有256个5 * 5 * 48卷积核;这256个卷积核分成两组,每组针对一个GPU中的27 * 27 * 48的像素进行卷积运算。会生成两组27 * 27 * 128个卷积后的像素层。
2.这些像素层经过relu2单元的处理,生成激活像素层,尺寸仍为两组27 * 27 * 128的像素层。
3.这些像素层经过pool运算(最大池化)的处理,池化运算的尺度为3 * 3,运算的步长为2,则池化后图像的尺寸为(57-3)/2+1=13。 即池化后像素的规模为2组13 * 13 * 128的像素层。
4.最后经过归一化处理,归一化运算的尺度为5 * 5;第二卷积层运算结束后形成的像素层的规模为2组13 * 13 * 128的像素层。分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
3.conv3
layer { name: "conv3" type: "Convolution" bottom: "pool2" top: "conv3" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 } } layer { name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" }

1.第三层没有使用池化层,只有一个卷积层与另外一个激活函数。
2.输入数据为第二层输出的2组13 * 13 * 128的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有192个卷积核,每个卷积核的尺寸是3 * 3 * 256。因此,每个GPU中的卷积核都能对2组13 * 13 * 128的像素层的所有数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。stride步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1 * 2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU中共13 * 13 * 192个卷积核。2个GPU中共13 * 13 * 384个卷积后的像素层。
3.这些像素层经过激活函数relu3,尺寸仍为2组13 * 13 * 192像素层,共13 * 13 * 384个像素层。
4.conv4
layer { name: "conv4" type: "Convolution" bottom: "conv3" top: "conv4" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 384 pad: 1 kernel_size: 3 group: 2 } } layer { name: "relu4" type: "ReLU" bottom: "conv4" top: "conv4" }

1.本卷积层没有使用池化降采样层,这一层的内容与第三层一致,就不赘述了。
5.conv5
layer { name: "conv5" type: "Convolution" bottom: "conv4" top: "conv5" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 256 pad: 1 kernel_size: 3 group: 2 } } layer { name: "relu5" type: "ReLU" bottom: "conv5" top: "conv5" } layer { name: "pool5" type: "Pooling" bottom: "conv5" top: "pool5" pooling_param { pool: MAX kernel_size: 3 stride: 2 } }
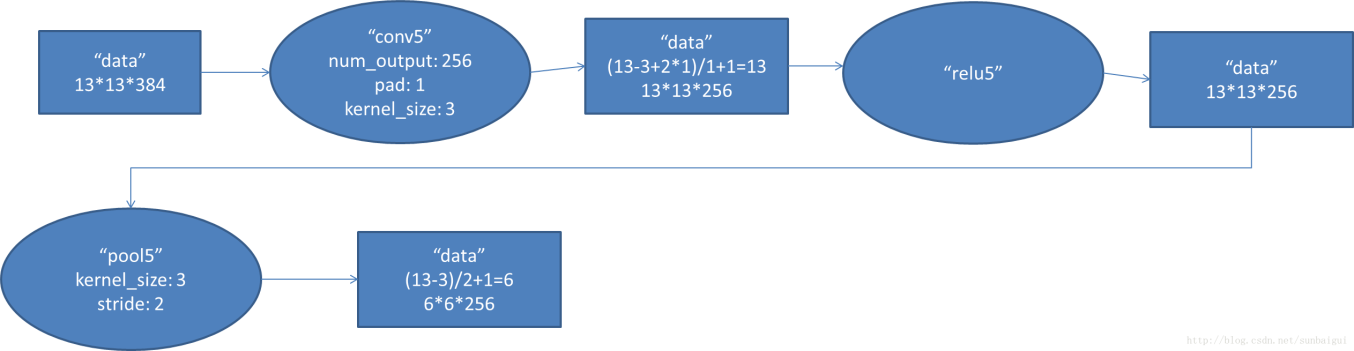
1.输入数据2组13 * 13 * 192的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有128个卷积核,每个卷积核的尺寸是3 * 3 * 192。因此,每个GPU中的卷积核能对1组13 * 13 * 192的像素层的数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。stride步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1 * 2)/1+1=13(在加上上下、左右各填充的1个像素,共生成13个像素),每个GPU中共1313128个卷积核。2个GPU中共13 * 13 * 256个卷积后的像素层。
2.这些像素层经过激活函数relu5单元处理,尺寸仍为2组13 * 13 * 128像素层,共13 * 13 * 256个像素层。
3.2组13 * 13 * 128像素层分别在2个不同GPU中进行池化(最大池化)处理。池化运算的尺度为3 * 3,运算的步长为2,则池化后图像的尺寸为(13-3)/2+1=6。 即池化后像素的规模为两组6 * 6 * 128的像素层数据,共6 * 6 * 256规模的像素层数据。
6.fc6
layer { name: "fc6" type: "InnerProduct" bottom: "pool5" top: "fc6" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 } } layer { name: "relu6" type: "ReLU" bottom: "fc6" top: "fc6" } layer { name: "drop6" type: "Dropout" bottom: "fc6" top: "fc6" dropout_param { dropout_ratio: 0.5 } }
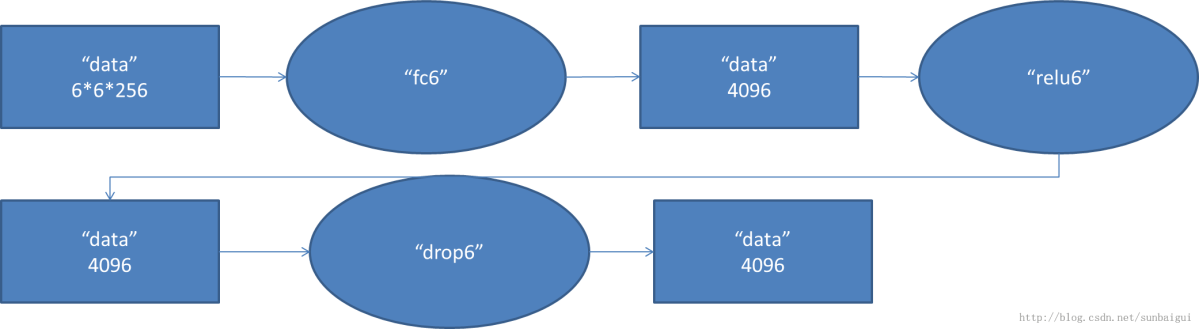
1.Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作。
2.输入数据的尺寸是6 * 6 * 256,采用6 * 6 * 256尺寸的滤波器对输入数据进行卷积运算;每个6 * 6* 256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6 * 6 * 256尺寸的滤波器对输入数据进行卷积运算,通过4096个神经元输出运算结果;
3.这4096个运算结果通过relu激活函数生成4096个值;
4.在dropout中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。通过drop运算后输出4096个本层的输出结果值。
7.fc7
layer { name: "fc7" type: "InnerProduct" bottom: "fc6" top: "fc7" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 4096 } } layer { name: "relu7" type: "ReLU" bottom: "fc7" top: "fc7" } layer { name: "drop7" type: "Dropout" bottom: "fc7" top: "fc7" dropout_param { dropout_ratio: 0.5 } }
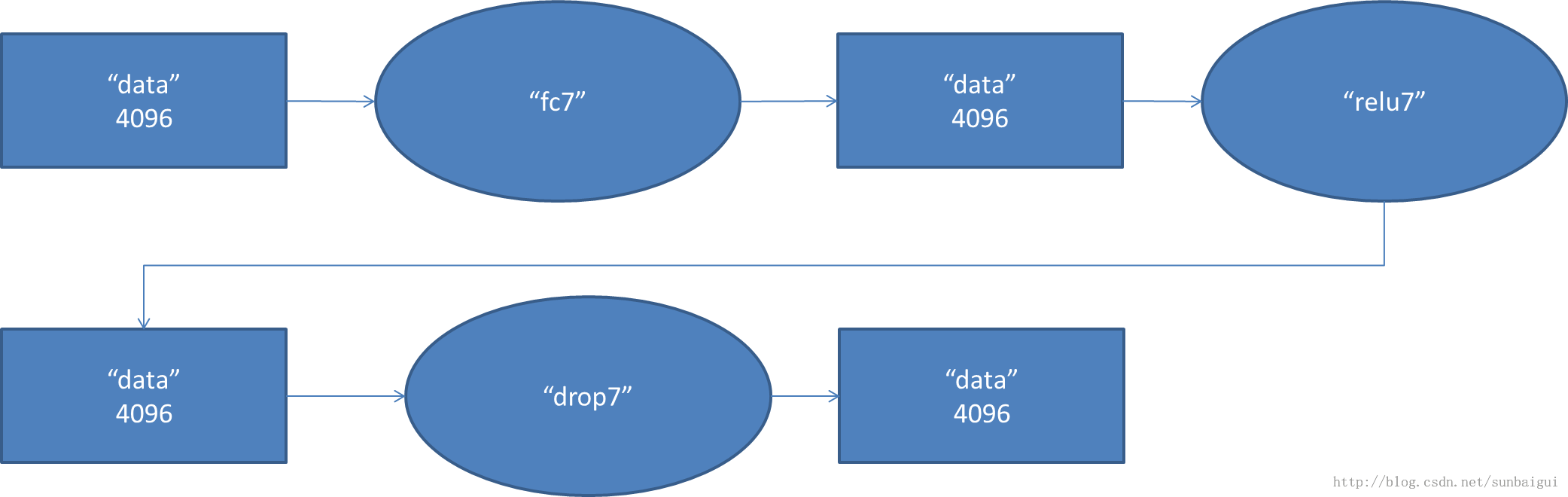
1.输入的4096个数据与第七层的4096个神经元进行全连接;
2.操作如同然后上一层一样经由relu7进行处理后生成4096个数据;
3.再经过dropout7(同样是以0.5的概率)处理后输出4096个数据。
8.fc8
layer { name: "fc8" type: "InnerProduct" bottom: "fc7" top: "fc8" param { lr_mult: 1 decay_mult: 1 } param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 1000 } } layer { name: "prob" type: "Softmax" bottom: "fc8" top: "prob" }

1.第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出被训练的数值。
附注:
ReLU和多个GPU
为了提高训练速度,AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题.
重叠的pool池化
提高精度, 不容易产生过拟合,在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性.
局部响应归一化
提高精度,局部响应归一化,对局部神经元创建了竞争的机制,使得其中响应小打的值变得更大,并抑制反馈较小的.
数据增益 Dropout
减少过拟合,使用数据增强的方法缓解过拟合现象
各个网络层的作用简析:
卷积层:
卷积层是整个神经网络中最重要的一层,该层最核心的部分为过滤器,或者称为卷积核,卷积核有大小和深度两个属性,大小常用的有3X3、5X5,也有11X11的卷积核,而深度通俗一点理解就是卷积核的个数。卷积核的大小和深度均由人工指定,而权重参数则在初始化的时候由程序随机生成,并在后期训练过程中不断优化这些权重值,以达到最好的分类效果。卷积的过程就是用这些权重值不断的去乘这些图片的RGB值,以提取图片数据信息。卷积不仅提取了图片信息,也可以达到降维效果。如果希望卷积后的特征值维度和原图片一致,需要设置padding值(全零填充)为SAME(如果为VALID表示不填充),其中i为输入图片,k为卷积核大小,strides为移动步长(移动步长>1也可以达到降维的效果)。
在卷积层中,过滤器中的参数是共享的,即一个过滤器中的参数值在对所有图片数据进行卷积过程中保持不变,这样卷积层的参数个数就和图片大小无关,它只和过滤器的尺寸,深度,以及当前层节点的矩阵深度有关。比如,以手写图片为例,输入矩阵的维度是28X28X1,假设第一层卷积层使用的过滤器大小为5X5,深度为16,则该卷积层的参数个数为5X5X1X16+16=416个,而如果使用500个隐藏节点的全链层会有1.5百万个参数,相比之下,卷积层的参数个数远远小于全链层,这就是为什么卷积网络广泛用于图片识别上的原因。
卷积计算完成后,往往会加入一个修正线性单元ReLU函数,也就是把数据非线性化。为什么要把数据进行非线性化呢,这是因为非线性代表了输入和输出的关系是一条曲线而不是直线,曲线能够刻画输入中更为复杂的变化。比如一个输入值大部分时间都很稳定,但有可能会在某个时间点出现极值,但是通过ReLU函数以后,数据变得平滑,这样以便对复杂的数据进行训练。 ReLU是分段线性的,当输入为非负时,输出将与输入相同;而当输入为负时,输出均为0。它的优点在于不受“梯度消失”的影响,且取值范围为[0,+∞];其缺点在于当使用了较大的学习速率时,易受达到饱和的神经元的影响。
池化层:
卷积层后一般会加入池化层,池化层可以非常有效地缩小矩阵的尺寸,从而减少最后全链层中的参数,使用池化层既可以加快计算速度也有防止过拟合问题的作用。 池化层也存在一个过滤器,但是过滤器对于输入的数据的处理并不是像卷积核对输入数据进行节点的加权和,而只是简单的计算最大值或者平均值。过滤器的大小、是否全0填充、步长等也是由人工指定,而深度跟卷积核深度不一样,卷积层使用过滤器是横跨整个深度的,而池化层使用的过滤器只影响一个深度上的节点,在计算过程中,池化层过滤器不仅要在长和宽两个维度移动,还要在深度这个维度移动。使用最大值操作的池化层被称之为最大池化层,这种池化层使用得最多,使用平均值操作的池化层被称之为平均池化层,这种池化层的使用相对要少一点。
全连接层:
在KNN或线性分类中有对数据进行归一化处理,而在神经网络中,也会做数据归一化的处理,原因和之前的一样,避免数据值大的节点对分类造成影响。归一化的目标在于将输入保持在一个可接受的范围内。例如,将输入归一化到[0.0,1.0]区间内。在卷积神经网络中,对数据归一化的处理我们有可能放在数据正式输入到全链层之前或之后,或其他地方,每个网络都可能不一样。
全链层的作用就是进行正确的图片分类,不同神经网络的全链层层数不同,但作用确是相同的。输入到全链层的神经元个数通过卷积层和池化层的处理后大大的减少了,比如以AlexNet为例,一张227*227大小,颜色通道数为3的图片经过处理后,输入到全链层的神经元个数有4096个,最后softmax的输出,则可以根据实际分类标签数来定。
在全链层中,会使用dropout以随机的去掉一些神经元,这样能够比较有效地防止神经网络的过拟合。相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个人不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束。
参考文章:
https://www.cnblogs.com/gongxijun/p/6027747.html
https://blog.csdn.net/hjimce/article/details/50413257https://blog.csdn.net/taoyanqi8932/article/details/71081390