遇到问题
计算机视觉之图像分类问题
- 输入:图片
- 输出:类别。
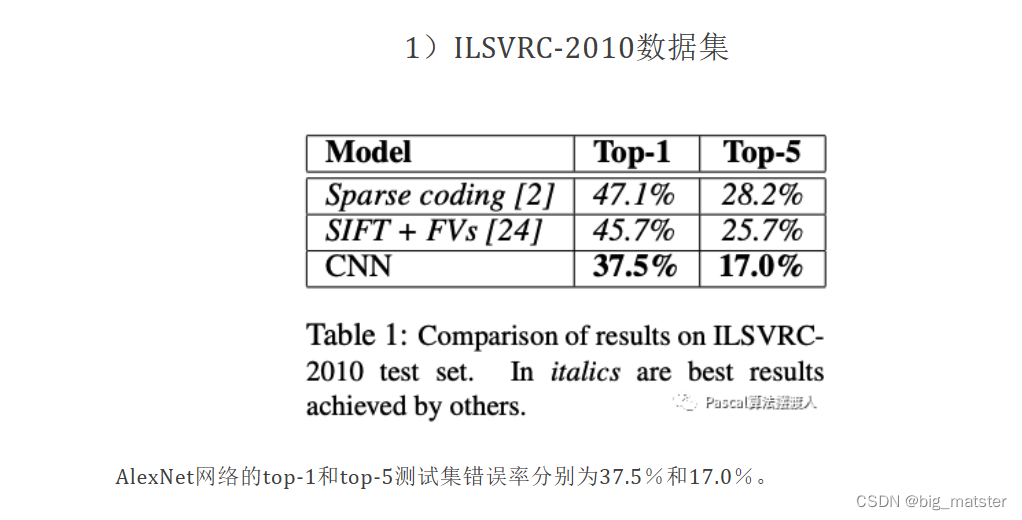
- 在ImageNet LSVRC-2010比赛中的120万张高分辨率图像分为1000个不同的类别。
- 训练一个庞大的深层卷积神经网络
- 在测试数据上,我们取得了37.5%和17.0%的top-1和top-5的错误率,这比以前的先进水平要好得多
图像分类
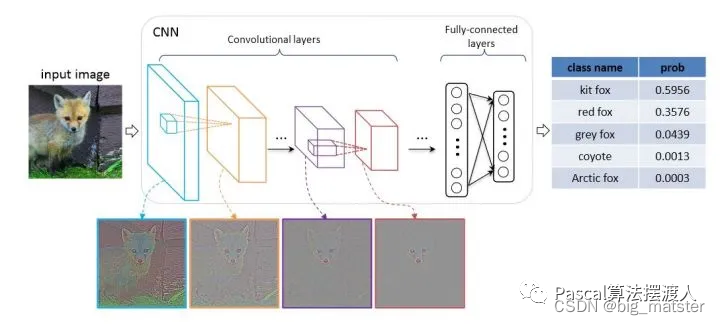
- 输入:图像image
- 图像的特征提取: 深度学习(自动提取特征)——卷积神经网络(CNN)、自注意机制(Transformer)等。
- 分类器,图片特征进入全连接层即MLP,加上softmax,
- 输出类别: label.
ILSVRC数据集
从2010年开始,每年举行一次名为ImageNet大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)的竞赛,ILSVRC使用ImageNet的子集。

ImageNet数据集是具有超过1500万幅带标签的高分辨率图像的数据集,这些图像大约属于22000个类别,这些图像从互联网收集,并由人工使用其亚马逊其众包工具贴上标签。
- 每1000个类别当中大约有1000个图像
- 总共有大约120万张训练图像,、
- 50,000张验证图像
- 150,000张测试图像
- 在ImageNet上使用两种评价指标
- top-1错误率
- top-5错误率
LeNet5模型
LeNet模型(LeCun等,1998)是最早提出的卷积神经网络模型。
主要用于MNIST(modified NIST)数据集中手写数字识别(0~9)。
模型结构如图所示,其中包含3个卷积层、2个池化层和2个全连接层。每个卷积层和全连接层均有可训练的参数,为深度卷积神经网络发展奠定了基础。
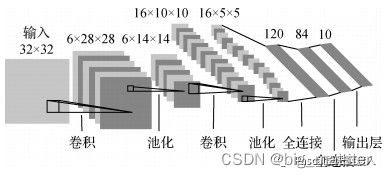
尽管LeNet在小规模MNIst数据集上取得了不错的效果,但复杂的图像分类任务需要大规模的数据集以及学习能力更强的网络模型。
AlexNet网络
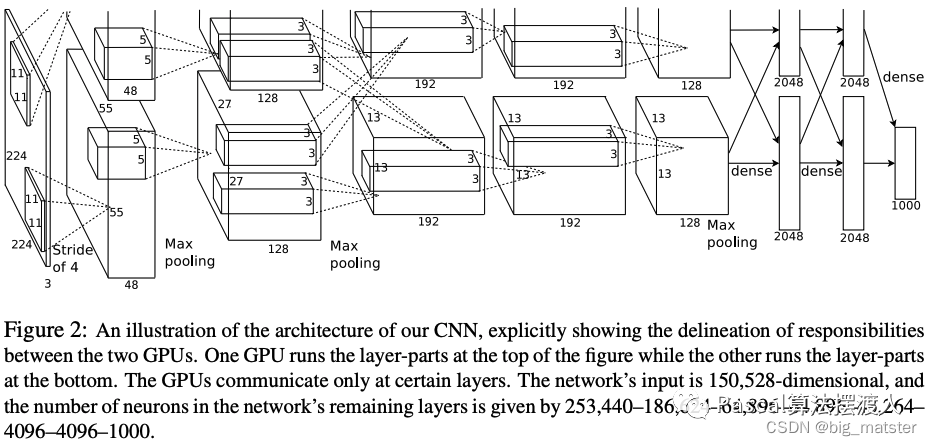
这个网络包含了八层权重:
- 前五层是卷积层+激活函数。
- 后三层为全连接层。
- 最后的全连接层输出被送到1000维的softmax函数。
预测1000个类别。 - 我们的网络最大化多项逻辑回归目标,这相当于在预测分布下最大化训练样本中正确标签对数概率的平均值。
- 输入 224 × 224 × 3 224 \times 224 \times 3 224×224×3图像
- 第一个卷积层使用96个卷积核,其大小为 11 × 11 × 3 11 \times 11 \times 3 11×11×3,步长为4.(步长表示内核映射中相邻神经元感受野中心之间的距离)的卷积核来处理输入图像。
- 第二个卷积层,将第一个卷积层的输出(相应归一化以及池化)作为输入,并使用256 个内核处理图像。每个内核大小 5 × 5 × 48 5 \times 5 \times 48 5×5×48
- 第三个、第四个和第五个卷积层彼此连接而中间没有任何池化或归一化层。
- 第三个卷积层有384个内核,每个大小为 3 × 3 × 256 3 \times3 \times 256 3×3×256其输入为第二个卷积层输出。
- 第四个卷积层有384个内核,每个内核大小为3×3×192
- 第五个卷积层有256个内核,每个内核大小为3×3×192。
- 全连接层各有4096个神经元。
激活函数ReLU
我们将这种非线性单元称为——修正非线性单元(Rectified Linear Units (ReLUs))。
使用ReLUs做为激活函数的卷积神经网络比起使用tanh单元作为激活函数的训练起来快了好几倍。
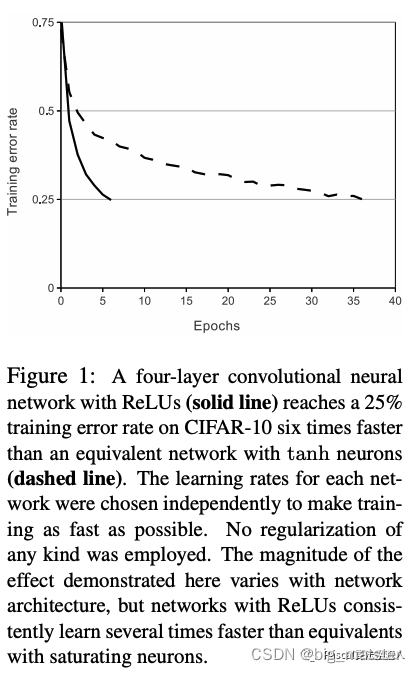
这个结果从图1中可以看出来,该图展示了对于一个特定的四层CNN**,CIFAR-10数据集训练中的误差率达到25%所需要的迭代次数**。
从这张图的结果可以看出,如果我们使用传统的饱和神经元模型来训练CNN,那么我们将无法为这项工作训练如此大型的神经网络。
局部响应归一化LRN

重叠池化
带交叠Pooling, 顾明思义指的是 P o o l i n g Pooling Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元输入的影响,也就是提取出来的结果可能是有重复的,实验表示使用带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用(获得了更多的感受野之间依赖关系的信息,提升了特征的丰富性)。
优化技巧
数据增强
- 第一种形式包括平移图像和水平映射,通过从 256 × 256 256 \times 256 256×256图像中,随机提取 224 × 224 224 \times 224 224×224图像块,(及其水平映射)并在这些提取的图像快上训练我们的网络来做到这一点。
- 第二种 形式的数据增强包括改变训练图像中RGB图像的灰度,在整个Image训练集的图像上 R G B RGB RGB像素值上使用PCA。
Dropout
- 新发现的技术叫做“Dropout”[10],它会以50%的概率将隐含层的神经元输出置为0。
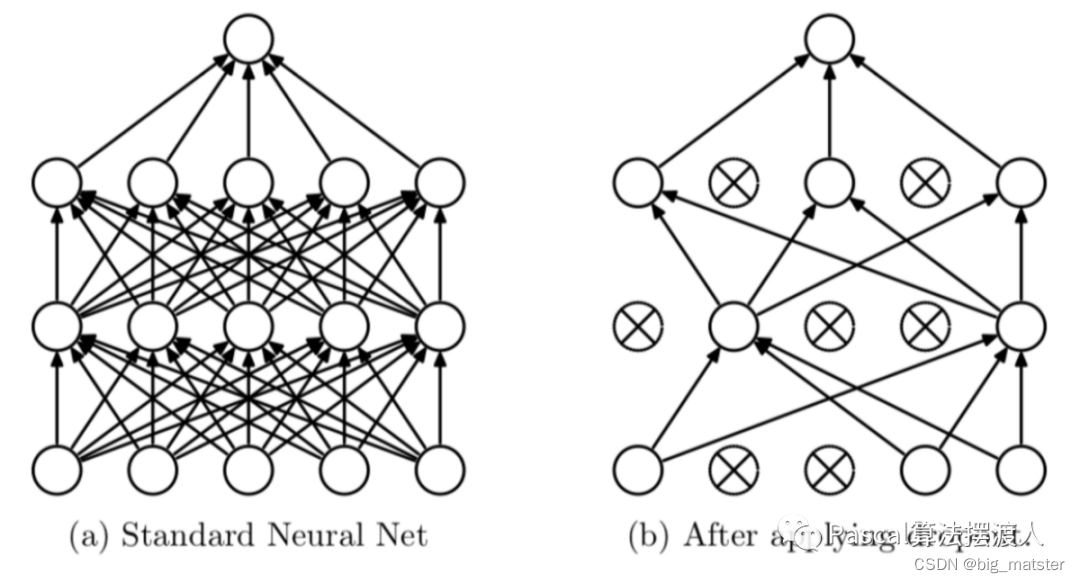
以这种方法被置0的神经元不参与网络的前馈和反向传播。
因此,每次给网络提供了输入后,神经网络都会采用一个不同的结构,但是这些结构都共享权重。
训练细节
在多个GPU上训练
单个GTX 580 GPU只有3GB内存,这限制了可以在其上训练的网络的最大尺寸。事实证明**,120万个训练样本足以训练那些因规模太大而不适合**使用一个GPU训练的网络。
因此**,我们将网络分布在两个GPU上**。

结论
想法
- 计算机视觉之图像分类问题
- 在ImageNet LSVRC-2010比赛中120万张高分辨率图像分为1000个不同的类别。
- 在设计AlexNet网络,其网络结构设计使用激活函数ReLU、LRN、重叠池化以及优化技巧数据增强和Dropout。
- 一个大的深层卷积神经网络在监督学习下是有效果的。当然,目前的项目中已经很少使用了。
经验
- 今天的学习到这里,明天将代码继续研读以下,不会的自己选择咨询导师。