论文地址
一.Abstract
1.提出了一个新的框架,即3D生成对抗网络(3D- gan),它利用体卷积网络和生成对抗网络的最新进展,从概率空间生成三维对象.
2.首先,使用对抗准则代替传统的启发式准则,使生成器能够隐式地捕获对象结构,并同步大小相同的高质量3D对象.
3.生成器G建立了一个从低维概率空间到三维对象空间的映射,使我们可以在没有参考图像或CAD模型的情况下对对象进行采样,并探索三维对象流形.
4.对抗识别器提供了一种强大的三维形状描述,无需监督即可学习,在三维物体识别中有着广泛的应用
二.Introduction
1.传统方法都是从CAD库中寻找组件生成新的物体,因此生成的很真实却不新颖
2.作者的方法对于三维对象建模来说可能是一个特别有利的框架:由于三维对象是高度结构化的,一个生成对抗准则,而不是一个体素独立的启发式准则,有可能捕获两个三维对象的结构差异(GAN的特点,整个数据集放入D网络)。使用生成对抗损失还可以避免可能依赖准则的过度拟合
1.GAN是基于图像整体作为loss学的是整个数据集的分布函数
2.基于范数的方法目标函数是基于单个像素点操作,约束了物体的轮廓,而GAN对图像整体作为约束并没有对物体轮廓进行约束。
3.以生成的方式建模3D对象提供了额外的独特优势。首先,有可能从概率潜在空间(如高斯分布或均匀分布)中采样新的三维对象
4.判别器具有良好的三维目标识别信息特征,G,D分别可以作为生成器和识别器
5.我们展示了我们的网络可以与一个变分自编码器相结合来直接重构
三.Related Work
1.建模和合成3D形状:
早期通过从数据库中检索和组合形状和部件来合成新对象。最近,Huang等人[2015]探索了使用预训练的模板生成3D形状,并同时生成对象结构和表面几何。我们的框架不需要显式地从存储库中借用部件来合成对象,并且在培训期间不需要监督
2. 3D数据 深度学习
噼里啪啦的说大规模数据的深度学习对视觉问题的影响
3.对抗网络的学习
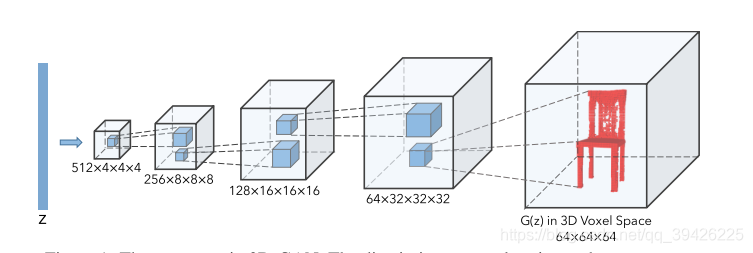
四.Modeling
1.论文介绍用于3D对象生成的模型。我们首先讨论如何构建我们的框架,3D生成对抗网络(3D- gan),利用之前在体卷积网络和生成对抗网络方面的进展。论文中展示了如何同时训练一个变分自编码器[Kingma和Welling, 2014],这样框架就可以捕获从2D图像到3D对象的映射
2.生成对抗网络(GAN)由一个生成器和一个鉴别器组成,鉴别器试图对真实对象和生成器合成的对象进行分类,而生成器试图混淆鉴别器。在我们的三维生成对抗网络(3D- gan)中,生成器G将一个随机抽取的200维潜在向量z映射到一个64×64×64的立方体中,表示三维体素空间中的一个对象G(z)。鉴别器D输出三维物体输入x是否为real的置信值D(x)
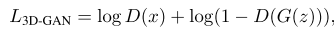
D(x)表示真实图像的置信度,D(x)越高Loss越低,D(G(z))越高Loss越高
3.网络架构
全卷积神经网络来生成3D对象。如网络结构图所示,生成器由5个容量全卷积层组成,分别为kernel size 4×4×4和steps 2,中间添加batch归一化层和ReLU层,最后添加一个Sigmoid层。鉴别器基本上是镜像发生器,除了它使用Leakly ReLU

4.3D-VAE-GAN
(1)引入3D-VAE-GAN作为3D-GAN的扩展。我们增加了一个额外的图像编码器E,它以一个二维图像x作为输入,输出潜在的表示向量z,这是受到[Larsen et al., 2016]提出的VAE-GAN的启发,它通过共享VAE的解码器和GAN的生成器来将VAE和GAN结合起来
(2)Loss函数为物体重建损失L(recon),一个用于3D-GAN的交叉熵损失L(3D-GAN),以及一个KL散度损失L(KL)
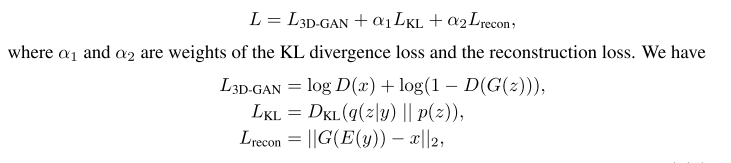
x是训练集的三维形状,y是它对应的二维图像,q(z|y)是向量z的变分分布,kl -散度将这个变分分布q(z|y)推向先验分布p(z)进行学习,我们选择了一个具有零均值和单位方差的多元高斯分布p(z)
五.Experiment
数据集:IKEA
1.3D Object Generation(使用生成器G)

3D- gan可以合成具有详细几何图形的高分辨率3D对象,合成低分辨率的物体相对容易,但是由于3D空间的快速增长,合成高分辨率的物体要困难得多。然而,对象细节只能在高分辨率下显示

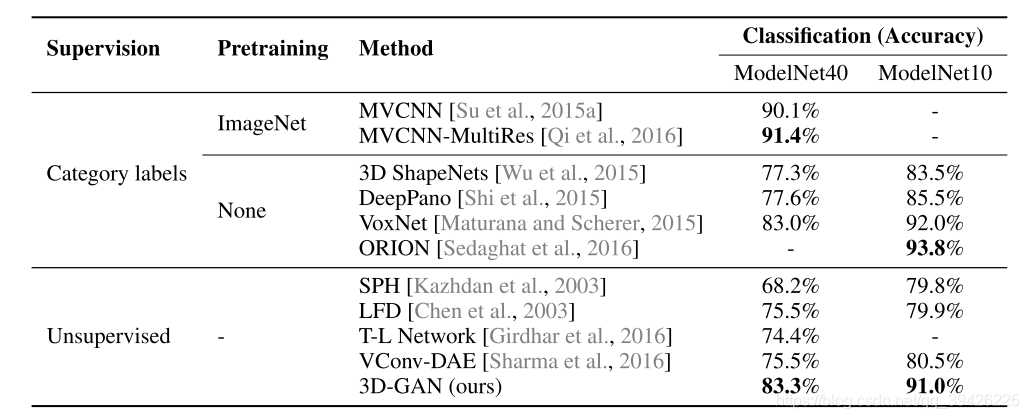
2. 3D Object Classification(使用鉴别器D)
为了获得输入3D对象的特征,我们将鉴别器中的第二层、第三层和第四层卷积层的响应连接起来,并分别应用内核大小为{8,4,2}的最大池。我们使用线性支持向量机进行分类
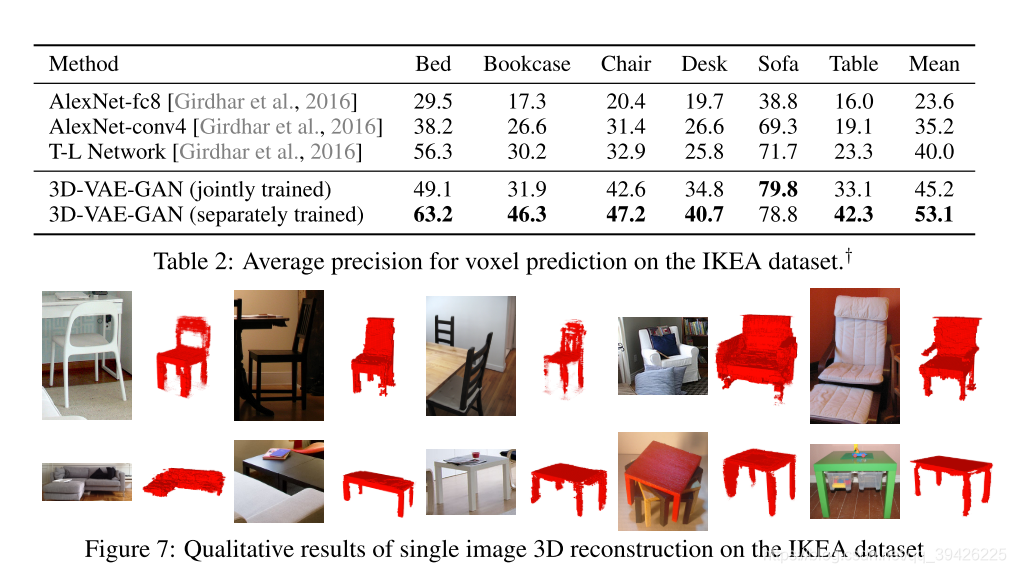
3.Single Image 3D Reconstruction(使用3d-vae-gan)
(1)单个3D-VAE-GAN的性能在所有6个类别上进行了联合训练
(2)另外还有6个3D-VAE-GANs在每个类别上单独训练的结果
六.Analyzing Learned Representation
1.可视化物体向量:
为了可视化向量Z每个维度的语义意义,我们逐步增加其值,观察其如何影响生成的三维对象。每一列对应于对象向量的一个维度,其中红色区域标记受该维度值变化影响的体素。我们观察到,对象向量中的某些维度承载着对象的语义知识,如表面的厚度或宽度

2.插值法:
本文展示了两个目标向量之间的插值结果。较早的工作演示了同一类别的两个2D图像之间的插值[Dosovitskiy et al., 2015, Radford et al., 2016]。这里我们展示了对象类别内和跨对象类别的内插。我们观察到,在这两种情况下,在隐空间中缓慢改变值域都能使物体之间产生平滑的过渡

3.算法
另一种探索学习表征的方法是在潜在隐空间中显示算法。之前,Dosovitskiy等[2015]、Radford等[2016]提出他们的生成网络能够在潜在空间中对椅子或人脸图像的语义知识进行编码;Girdhar等[2016]也证明了三维物体的学习表示具有相似的行为。我们展示了我们的形状算法。与Girdhar等[2016]不同,我们所有的对象都是随机采样的,不需要现有的3D CAD模型作为输入

4激活神经元可视化

对于鉴别器倒数第二卷积层的每个神经元,我们遍历了所有的训练对象,并展示了激活单元最强烈的训练对象。我们进一步使用引导反向传播[Springenberg等人,2015]来可视化产生激活的部分
