论文:基于激光雷达与单目视觉融合的SLAM与三维语义重建
来源:sensors
链接:dblp: SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision.
0、摘要
单目相机和激光雷达是无人驾驶车辆中最常用的两种传感器。将两者的优势相结合是当前SLAM和语义分析的研究重点。本文提出了一种改进的基于激光雷达和单目视觉融合的SLAM和语义重建方法。我们将语义图像与低分辨率三维激光雷达点云融合,生成密集的语义深度图。通过视觉测程选择具有深度信息的ORB特征点,提高定位精度。我们的方法使用并行线程来聚合三维语义点云,同时定位无人驾驶汽车。在公共的cityscape和KITTI Visual Odometry数据集上进行了实验,结果表明:与ORB-SLAM2和DynaSLAM相比,我们的定位误差大约降低了87%;与DEMO和DVL-SLAM相比,我们的定位精度在大多数序列上都有所提高。我们的三维重建质量优于DynSLAM,且包含语义信息。该方法在无人驾驶汽车领域具有工程应用价值。
1、引言
SLAM (simultaneous localization and mapping)技术主要利用相机、Lidar、IMU、GPS等传感器对未知环境中的移动机器人进行定位,同时对地图进行定位。SLAM根据外部传感器的不同,可分为视觉SLAM和激光雷达SLAM。
在视觉SLAM中,通常使用相机获取丰富的视觉信息,在目标检测、识别、环境语义理解等方面具有很大的优势和潜力。然而,相机采集的图像质量受光线的影响很大,因此,视觉SLAM在光照较差的场景中定位精度较低。另一方面,激光雷达采集的目标信息被表示为一系列具有精确角度和距离信息的散点云。由于激光雷达扫描包含深度信息,基于激光雷达的SLAM可以帮助移动机器人执行路径规划和导航等任务。而非结构化的激光雷达点不能呈现场景纹理;低纹理环境,如长走廊将给激光雷达SLAM[2]带来麻烦。因为它们看起来是互补的,它们的融合将能够平衡各自的主要弱点。同时使用视觉和激光雷达传感器可以降低局部不确定性和累积漂移[3]。
在三维重建过程中,从数据中提取语义和属性的工作量最大。考虑到户外驾驶环境的快速变化,人工标注的语义地图可能会导致车辆环境识别操作不足,造成不安全的情况。自动化的三维语义重建可以降低人工成本,提高驾驶安全性。为了提高重建地图的定位精度和质量,需要考虑语义图像与激光雷达的融合。
本文提出了一种基于激光雷达和单目视觉融合的SLAM和三维语义重建方法,该方法方便、高效地融合了室外环境下的单目图像和激光雷达点云。我们结合图像特征和精确的深度信息,实现无人驾驶汽车的鲁棒、高精度定位,结合语义图像和激光雷达点云,以方便、直观的方式重建高质量的大型户外场景3D地图。这些贡献如下:
(1)提出了一种投影插值方法,将低密度激光雷达点云与语义分割图像融合,并对语义图像对应的点云进行语义化处理。
(2)提出了一种基于激光雷达和单目视觉融合的SLAM方法,利用上采样点云为图像特征点提供深度信息,提高定位精度。
(3)针对映射的稀疏性问题,提出了一种三维密集重构方法,该方法在定位的同时,利用融合数据重构户外环境的密集语义图。
2、相关工作
2.1. Single-Sensor SLAM 单传感器SLAM
视觉SLAM主要利用相机作为外部传感器,获取丰富的纹理、颜色、形状等环境信息。ORB-SLAM[5]是一种基于ORB特征点的单目视觉SLAM。整个系统包括跟踪、局部映射和闭环检测三个并行线程。通过外极约束、三角剖分、非线性优化和基于词包的方法,实现了稀疏点云的实时重构。ORB-SLAM2[6]增加了立体匹配和优化算法,使用立体摄像机和RGB-D摄像机实现实时定位和稀疏重建。Bescos等人提出了DynaSLAM[7]算法,该算法结合Mask R-CNN[8]和多视图几何实现动态对象的剔除,修复被动态对象遮挡的背景,在KITTI Visual Odometry[9]数据集上的实验结果表明,该算法具有较高的定位精度。但是,由于网络层较多,这种方法不是实时的。Cui等人提出了SDF-SLAM[10]。他们开发了一种语义深度过滤器,使SLAM算法在动态环境中的定位更加准确。他们在室内场景中使用TUM数据集进行模拟,因此算法在更具挑战性的室外场景中的性能无法被表示出来。
与视觉SLAM相比,基于lidar的SLAM不能感知环境的颜色和纹理,但具有较强的抗光干扰能力,可以利用深度信息提高定位精度。Shan等人[11]提出的LeGo-LOAM通过对激光雷达点云进行分割,过滤出无人驾驶汽车行驶时产生的噪声,然后提取点云中的平面和边缘特征,减少定位误差,实现了利用嵌入式系统对无人驾驶汽车进行定位和构建稀疏地图。在地面上点云较少的情况下,该算法很容易崩溃。Plane-LOAM由´Cwian et al.[12]提出,从Lidar点云中提取平面和线段构建地图,并利用因子图优化无人驾驶车辆轨迹和稀疏地图。上述方法对精确激光雷达点云的成像效果都很好,但由于点云的稀疏性,导致成像的可见性较差。
2.2. Multi-Sensor Fusion SLAM
基于多传感器融合的SLAM可以有效克服单传感器的性能限制。Qin等人提出的VINS-Mono[13]系统结合了单目相机和IMU,设计了一个紧耦合的视觉惯性里程计系统。该方法提出的IMU预集成算法有效降低了光照变化、纹理缺失等因素对定位精度的负面影响,有助于稀疏地图的构建。ORB-SLAM3[14]在IMU初始化过程中采用最大后验概率估计,实现在各个场景中稳定运行;基于场景重新识别的多地图系统使算法能够在隧道和室内等低纹理环境中工作。它是一种鲁棒操作,但具有较大的计算成本。Ku等人[15]设计的方法使用RGB图像完成激光雷达扫描,在一定程度上可以弥补激光雷达扫描仪扫描角度不足的不足。LIMO由Graeter等人[16]提出,通过点云和帧的投影将激光雷达与图像数据相关联,获得视觉特征的深度估计。稀疏激光雷达点云只起补充作用,因此LIMO只能构建稀疏地图。
视觉特征常常不能与深度图或激光雷达点云完全匹配。De Silva et al.[17]提出的工作在计算视觉和激光雷达传感器之间的几何变换后,使用高斯过程回归插值缺失值。因此,使用激光雷达对图像中直接检测到的特征进行初始化。但是,该方法在有限的空间内进行传感器融合,在实时数据集上的实验中不能准确完成,与其他方法相比也不理想。Zhang等人提出的视觉里程计DEMO[18]将单目视觉和深度信息相结合,将特征点分类为深度信息匹配的特征点、三角剖分得到的带深度的特征点和不带深度信息的特征点,然后组合起来进行姿态估计。在KITTI Visual Odometry数据集上进行了实验,结果表明,该方法的定位精度甚至高于某些立体定位方法,但DEMO对特定角度的特征更为敏感。Shin等人提出的DVL-SLAM[19]基于直接法,融合了多线激光和单目图像,使用具有深度信息的像素而不是特征。该算法通过滑动窗口优化减小了激光雷达点与图像的匹配误差。实验结果表明,该算法具有较高的定位精度,可以进行三维重建。与基于特征的方法相比,DVL-SLAM计算量更大,更容易受到梯度变化的影响。
2.3. Semantic SLAM
语义SLAM结合深度学习,可以利用场景中物体的语义来提高在动态环境中的性能,这有助于更复杂的任务,如识别和避障[2]。Fusion++[20]利用深度图,结合Mask R-CNN和TSDF(截断符号距离函数)实现室内物体的三维重建。但该算法仅适用于室内静态环境。MaskFusion[21]利用Mask R-CNN对实例进行分割,并提出了一种基于几何的分割算法,该算法根据图像的深度和表面法线线索提供更精确的掩模,实现动态环境下的实时跟踪、重构,并为重构后的地图分配语义标签。Bârsan等人提出的DynSLAM[22]利用卷积神经网络MNC对图像背景和运动目标进行检测和分类,在一定程度上减少了动态目标的干扰,然后完成了KITTI数据集的三维重建。然而,它受到传感器性能和GPU内存的严重限制。
由于激光雷达点云具有非结构化、无序和不规则的特点,对其进行卷积和重构语义图具有相当大的挑战性。Milioto等人[23]提出的RangeNet++对点云的二维球面投影进行语义分割,然后使用kNN搜索算法对分割结果进行后处理,最后将分割结果重新投影回三维点云。后处理算法可以减少离散性引起的误分类,但同时也增加了算法的计算量。Chen等人提出的SuMa++[24]利用RangeNet++对激光雷达点进行语义分割,并采用泛洪填充算法减少语义误分类。该算法结合点云的语义信息,过滤出动态目标,并在ICP(迭代最近点)算法中添加约束,提高了定位精度,建立了基于面元surfel-based 3D三维语义地图。但该方法具有较高的复杂度和计算成本。
综上所述,在数据层面,光度的变化、运动物体的干扰、环境中纹理的缺乏等都会影响特征-匹配精度,导致定位精度下降甚至定位失败。 在任务层面,由于缺乏精确的深度信息,仅使用单目视觉很难重建密集的三维地图。 基于深度学习的语义SLAM算法可以利用激光雷达点云或其球面投影实现三维语义重建。 然而,不规则的激光雷达点云导致深度学习计算量大、复杂度高,球面投影缺少场景中的结构信息。
针对上述问题,我们提出了一种基于激光雷达和单目视觉融合的SLAM和三维语义重建方法。 第三部分给出了算法的总体框架,提出了一种稀疏点云的上采样方法,并利用上采样结果优化定位精度。 利用语义分割网络对二维图像进行分割,并与上采样的激光雷达点云对应,提供语义信息。 然后介绍了映射方法,利用融合数据完成三维重建。 在第四节中,我们在KITTI视觉里程数据集上评估了我们的算法的准确性,并与其他V-SLAM和基于融合的SLAM方法进行了比较。 最后,在第五节中得出结论。
3. Methods
图1表示了我们方法的总体框架,其中包括以下步骤。 (1)语义切分。 利用Bisenetv2训练的[25]模型对KITTI视觉里程数据集的二维单目图像序列的第i帧进行语义分割,得到第i帧语义二维图像。 (2)融合。 通过标定参数,将第i个三维激光雷达点投影到对应的第i个语义二维图像中,生成第i个语义稀疏三维深度图。 (3)插值。 利用深度插值算法对语义稀疏的三维深度图进行上采样,使低分辨率激光雷达点与球体特征点相匹配,输出第i次密集的三维点深度图。 (四)定位和优化。 以多线程并行执行实时定位和映射(ORB-SLAM2[6]),生成姿态/轨迹和语义三维点云重建。 (5)噪声滤除。 结合POSES重建单帧三维点云,并利用统计滤波器消除离群点。 (6)增量式地图配准。 利用位姿信息,对每一帧的三维点云进行增量拼接,得到过量的三维点云重建。 (7)冗余过滤。 利用体素网格滤波器减少冗余,得到完整语义的三维点云重建,包括完整的位姿和轨迹图。
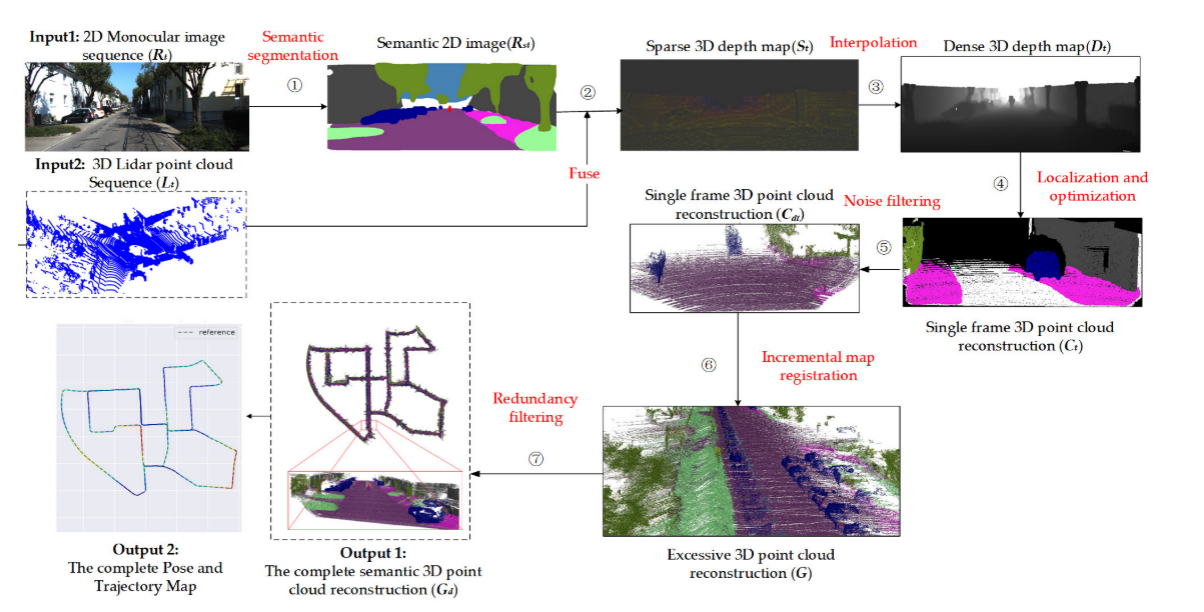
3.1. Data Fusion and Depth Interpolation
对于现有的降维方法,激光雷达点云的球面投影和鸟瞰投影是将三维点云数据表示为二维图像数据的常用方法,并且通常用于深度学习任务[23]。 然而,这些方法都有一个严重的局限性:由于点云非常稀疏,大多数点云不能直接匹配到二维图像来提供深度信息,而且点云的低密度也导致融合数据中的几何结构缺失。 此外,这些方法使用极坐标系对点云进行编码,而不是在笛卡尔坐标系中对点进行编码,这可能会使前端视觉里程测量变得复杂。
对于现有的降维方法,激光雷达点云的球面投影和鸟瞰投影是将三维点云数据表示为二维图像数据的常用方法,并且通常用于深度学习任务[23]。 然而,这些方法都有一个严重的局限性:由于点云非常稀疏,大多数点云不能直接匹配到二维图像来提供深度信息,而且点云的低密度也导致融合数据中的几何结构缺失。 此外,这些方法使用极坐标系对点云进行编码,而不是在笛卡尔坐标系中对点进行编码,这可能会使前端视觉里程测量变得复杂。
由于每个设备采集的数据坐标系不同,我们利用标定数据将LIDAR扫描按时间戳T的顺序投影到RGB帧中,为ORB特征点提供深度值。 定义图像中的激光雷达点pi=(x,y,z,1)和投影点pi=(u,v,1)。 利用时间戳和校准文件,将PI对应并投影到二维图像中作为PI。 以KITTI视觉里程计数据集为例,用方程生成PI:
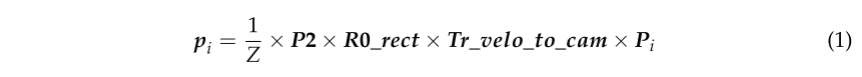
(这个公式就是把激光点云的投影到图像上)
根据标定文件,tr_velo_to_cam是激光雷达到灰度相机坐标系的投影矩阵,R0_rect是灰度相机的旋转校正矩阵,P2是彩色相机的内参数矩阵。 由于激光雷达采集的图像密度远低于像素密度,激光雷达与视觉融合生成的数据是稀疏的深度图。 稀疏的激光雷达点无法对应图像中的球体特征。 为此,我们对稀疏深度图进行上采样以提高激光雷达点的密度:

在密集深度图中,投影点具有语义信息通道,用于关联二维图像中对应像素的语义信息。 其中,是带有语义信息的密集深度图,
是pi邻居坐标。 Z是pi的深度,ω是计算权重,它是pi与
之间的空间距离的倒数。 Kd是归一化因子。 考虑到时间效率和精度,我们设置n=5,并对每个投影点周围的5^2-1像素进行深度插值。 ω和Kd定义如下:

在插值过程中,我们遍历稀疏融合图像,计算P与ζ之间的欧氏距离(欧氏距离的逆ω与投影点与像素之间的相似度成反比),并为投影点的邻域分配深度值。
(把稀疏的激光点插值到密集深度,采用的方法是每个真值附近的25个像素做,权重是距离的远近,不过疑问是假设两个有真值的像素间隔为10,假设为0和10,那012和8910都可以插值,但是34567都是0吗?)
3.2. Location and BA Optimization
视觉里程计(VO)是视觉SLAM算法的前端,主要通过图像计算机器人的位姿。 它根据连续图像的信息估计出摄像机的粗略运动,并为后端提供良好的初始值。 定义向量(x,y,z,q0,q1,q2,q3)T来描述刚体从初始框架i0到当前框架ik的运动,其中t0-k=(x,y,z)T描述平移,四元数(q0,q1,q2,q3)转换为旋转矩阵R0-k来表示旋转:
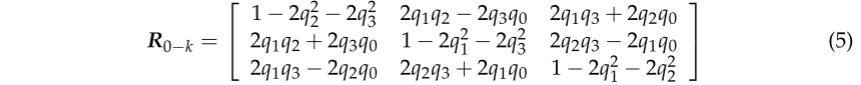
(这个是四元数转为旋转矩阵的公式)
然后将无人车在K时刻的位姿T定义为一个变换矩阵:

(位姿变化矩阵是4*4,由旋转矩阵和平移矩阵拼接)
由于VO只计算相邻帧的位姿,误差不断累积,最终导致无人车轨迹漂移。 此外,旋转矩阵本身是有约束的(正交且行列式为1),如果将其作为优化变量,则优化难度较大。 在后端,利用李代数的束调整和摄动模型,通过无约束最小二乘问题对无人车的姿态进行优化。
PNP(Perspective-N-Point)[26]是一种求解3D-2D点对运动的方法。 当我们知道三维点及其投影位置时,用PNP描述摄像机姿态。 受噪声影响,运动方程和观测方程不一定完全相等。 为了解决这个问题,我们构造了最小二乘问题,利用束调整[27]来优化摄像机姿态和地图点位置。 图2显示了重新投影误差的示意图。 将两帧中匹配的球体特征点分别定义为P1和P2,深度图为它们提供了真实的深度尺度,P为观测点。 在噪声的影响下,P被错误地重投影到P1*上,E是P1与P1*之间的重投影误差。
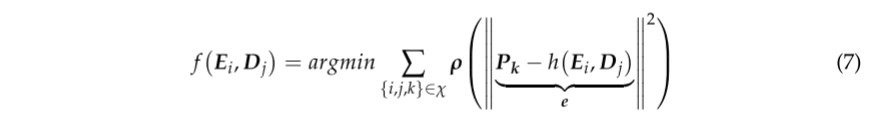
对于环境中的任意3D点P,每个视图对应的摄像机光学中心发出的光,经过图像中对应P的像素点后,就会在P处相交,在3D空间中形成一系列光束。 由于噪声和特征提取和匹配过程中的误差,光几乎不可能正确会聚。 因此,在求解过程中,要不断调整所要寻求的信息,使光线最终能在P[27]处相交。 将待优化的目标函数定义为最小二乘方程:

用Gauss-Newton方法[27]求解最小二乘问题,需要为E和D提供代价函数的偏导数。利用李代数摄动模型,计算出T和D的雅可比矩阵EJ和DJ如下:

其中[x,y,z]t是相机坐标系中的地图点坐标。 Cx和Cy是相机的内部参数。 优化问题变成一个梯度下降的过程,直到图点位置的自变量ΔE增量很小,目标函数收敛到最小。 因此,高斯-牛顿方程(11)[27]可以导出方程(12):

其中雅可比矩阵J是代价函数关于变量的一阶导数矩阵,Hessian矩阵H是代价函数关于变量的二阶矩阵矩阵。 在优化过程中,首先对帧进行匹配,得到初始摄像机位姿和地图点位置,然后计算导数和误差。 迭代求解高斯-牛顿方程,直至目标函数收敛。
(这里作者重写了pnp的公式,不是可以直接套用prbslam rgbd的模式吗)
3.3. 3D Semantic Reconstruction
经过VO和后端优化,我们利用带有语义信息的密集深度图来重建室外环境的大规模三维地图。 将摄像机坐标系中的点pi=(u,v,1)定义为:

其中d∈[0.01,30]为深度值,缩放因子S=1000。 摄像机内部参数Cx,Cy=707.09,焦距Fx=601.89mm,Fy=183.11mm。 则世界坐标系中的点位置,即三维重建地图中的坐标定义为:
![]()
(和上边公式1反着来,可以理解为已知二维图像坐标uv反投影到三维空间)
上采样的语义深度图存在深度值误差,导致重建的三维点出现离群点,破坏重建的几何形状。 我们使用统计滤波器遍历单个帧的重建来去除噪声。 统计过滤器定义为:
![]()
其中,μK是K个最近点之间的平均距离,dmax是阈值,σ=0.8代表平均距离的标准差,比例因子α=0.8。 如果μk>dmax,则该点被认为是离群点并被消除。
(这里感觉作者写错了,就是k最近邻,μ平局值,σ标准差,当 距离>dmax = μk+0.8σ认为是离群点。作者原来写的是σ=0.8是标准差,μk>dmax一定不成立吧)
在对单帧进行增量累加重建后,重叠区域中存在大量冗余点,占用内存过大。 为了减少冗馀,优化三维重建的几何结构,我们在重建中使用体素网格滤波构造多个体素网格,然后计算点云的重心,消除重心周围的点,定义如下:

其中v为体素网格的重心,n为体素网格中点云的总量,pi为体素网格中的点云。 我们将体素网格设置为边长为20厘米的立方体。
(这里没太看懂,如果是用体素网格优化的话,重心可以用一个点代替周围20cm的立方体的的点,但是语义标签是怎么代替的呢?按照最大的吗)
基于激光雷达和单目视觉融合的SLAM和三维语义重建方法如算法1所示,对应图1。
4、Experiment and Analysis
本文所使用的实验平台由Intel至强E3-1230处理器、NVIDIA GTX1080TI GPU处理器、16GB内存、Ubuntu 16.04处理器组成。 我们使用公共数据集Kitti Visual Odometry[9]和Cityscapes[29]进行实验。
4.1. Semantic Segmentation
Cityscapes数据集使用车载摄像头记录城市环境数据,并有详细的语义标注。 因此,我们使用Cityscapes数据集来训练MASK R-CNN。 注释文件以JSON格式保存。 Cityscapes数据集共有5000幅街景图像,其中2975幅图像用于训练,500幅图像用于验证,1525幅图像用于测试。 图像分辨率为1024×2048。
KITTI视觉里程计数据集采集于德国西南部的卡尔斯鲁厄市,包括11个00~10的真实轨迹序列[9],其中序列01为高速公路场景,其余序列为城市或乡村道路场景。 RGB序列以分辨率为1241×376的PNG格式存储,激光雷达扫描数据以大小为1900KB的BIN格式存储。
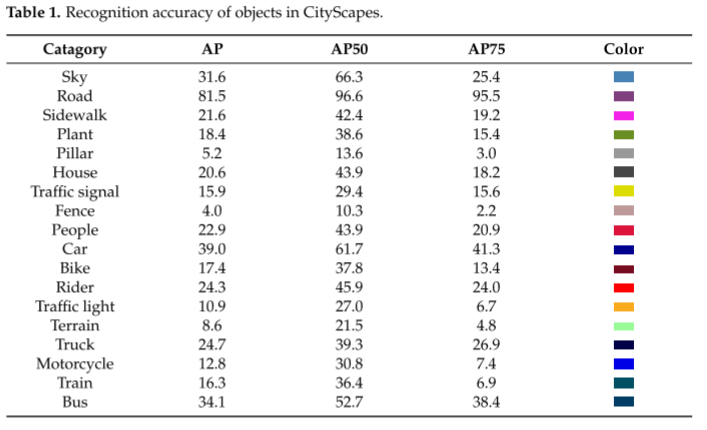
我们训练和分割了道路场景中常见的18类目标,使用目标检测评价标准为平均AP、AP50和AP75[30]。 将训练好的模型应用于KITTI视觉里程数据集,以不同颜色表示场景中的对象,分割结果如图3所示。 训练后AP50值达39.4,AP75达29.8,平均AP值为21.8。 Bisenetv2在Cityscape数据集上训练的18种对象的精确度如表1所示。 从表中可以看出,面积较大的物体识别效果更好。
4.2. Data Fusion and Depth Interpolation
图4显示了原始RGB图像和密集深度图的比较。 我们将稀疏的激光雷达扫描投影到语义图像上,然后对融合后的数据进行深度插值。 在深度图中,远处的黑洞是激光雷达扫描仪扫描范围之外的区域,距离车辆位置120米。 由于距离太远和天空的物体无法将发射的点云反射到激光雷达扫描仪,同时受到KITTI数据采集车上配备的Velodyne64垂直视场(26.8°)的限制[9],深度图1241×150顶部区域的信息丢失。 然而,由于我们的方法侧重于交通场景,因此不需要缺失区域的屋顶和天空。

我们提出的透视投影和上采样方法将点云坐标转换为直角坐标而不是极坐标,保留了二维图像的外观信息。 基于透视投影和深度插值,不仅实现了点云与语义图像的融合,而且提高了投影点的密度。 该融合方法使得视觉里程仪可以直接将单目图像与激光雷达点云进行匹配定位,具有较低的复杂度。
4.3. Positioning Accuracy Based on the Fusion of Lidar and Monocular Vision
本文提出的算法利用RGB序列和深度插值算法上采样的密度-深度图对无人驾驶车辆进行定位。 我们用ATE(绝对轨迹误差)[31]和平移误差[32]对KITTI视觉里程计数据集的定位精度进行了评估。
ATE是估计轨迹与地面真实值之间的直接差值,可以非常直观地反映算法的准确性和轨迹的全局一致性。 需要注意的是,估计的位姿和地面真值通常不在同一个坐标系中,因此我们使用公共评估工具包EVO对齐两个轨迹并计算误差。 对于从I=1到I=m的所有姿态,我们用李代数格式的地面真值轨迹GTI和估计轨迹TI来计算ATE的RMSE。李代数格式定义为:
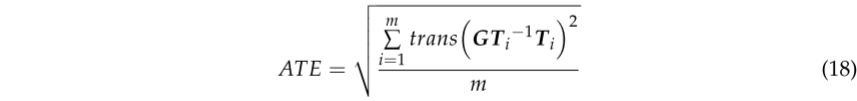
KITTI正式提出的平移误差标准是100米、200米、800米多类等长轨迹的平移误差的算术平均值,并以百分比计算。轨迹误差值越低,定位精度越高。平移误差的计算公式定义为:

式中,F为记录无人驾驶汽车运动的图像序列,GT、T为无人驾驶汽车姿态的真实值和估计值,{GT, T}∈SE(3)。TjTi是子段从第i帧到第j帧的位姿变换。
图5显示了在KITTI Visual Odometry数据集的00、01、05和07序列中估计的轨迹与地面真实度的对比。(a)、(b)中,虚线表示无人驾驶汽车的真实轨迹,实线表示估计轨迹,ATE值对应右侧的色谱。各序列的轨迹与地面真实情况基本一致,表明所提出的算法能够获得较好的定位结果。在(c)和(d)中,我们比较了我们的方法和ORB-SLAM2的估计轨迹;比较表明,我们的实验结果具有较小的漂移。

表2对比了本文方法与单目ORBSLAM2[6]和DynaSLAM[7]在KITTI Visual Odometry数据集中的轨迹误差。在00和02~10序列中,我们的方法平均ATE为1.39m。与ORB-SLAM2和DynaSLAM相比,误差分别提高了87.51%和87.21%。由于序列01记录的是空的高速公路场景,缺少可以提取的近距离特征点,难以满足本文[5]提出的特征选择准则,单眼ORB-SLAM2和DynaSLAM算法无法工作。本文提出的算法利用了精确的深度信息,不需要通过三角化获取深度值,可以有效定位。
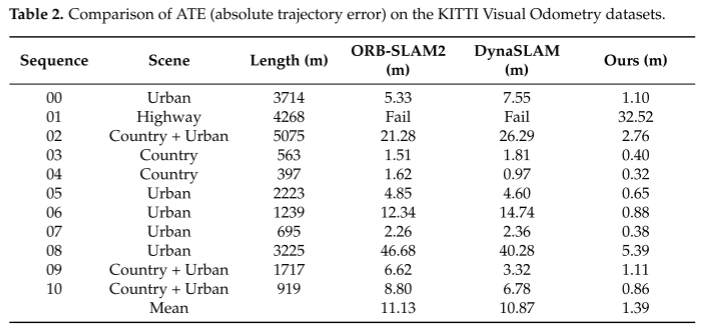
图6显示了KITTI Visual Odometry数据集中子序列的翻译错误。红色曲线为ground truth,蓝色曲线为估计结果,蓝色折线表示每个子序列的平移误差。可以看出,我们计算的轨迹与地面真实轨迹之间的误差保持在一个很小的变化范围内,并且估计的轨迹在三维空间中的变化与地面真实轨迹相似。

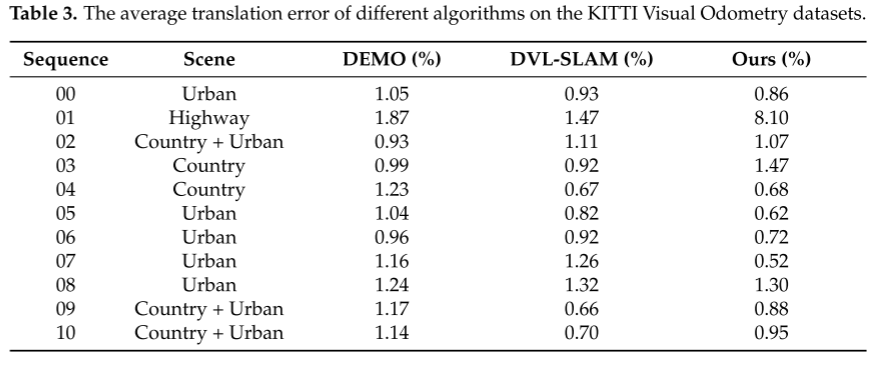
将该方法与其他多传感器融合SLAM方法进行了比较。在表3中,我们比较了我们的方法与DEMO[18]和DVL-SLAM[19]在KITTI Visual Odometry数据集中的平均翻译误差。在11个序列中,我们有7个序列优于DEMO, 6个序列优于DVL-SLAM。KITTI公司使用的Velodyne64激光雷达扫描仪的探测范围为120米,不能在01序列中进一步提供深度信息;部分特征点被丢弃,导致定位误差较大。在深度信息缺失的区域,DEMO通过三角剖分估计特征点的深度,比我们的方法保留了更多的特征点;DVL-SLAM基于直接方法,不受近距离特征点太少的影响。因此在序列01中定位精度较高。
4.4. 3D Reconstruction
由于KITTI Visual Odometry数据集没有提供三维场景中物体的ground truth,所以本节我们使用MeshLab[33]测量三维重建序列05中物体的长度,使用谷歌Earth[34]测量真实长度。利用两种测量值的相对误差进行定量评价。然后对序列06进行三维重建,对比DynSLAM[22]在同一序列下的重建质量进行定性评价。为了便于比较,我们在定量和定性评估中显示的3D重建保留了场景的原始颜色。在本节的最后,我们将展示序列00的3D语义重建,用不同的颜色表示点云中对象的类别。
4.4.1. Quantitative Evaluation of Reconstruction
01序列的经纬度大约是9◦0306.6N, 8◦2351.4E[9]。图7中(a)为利用Meshlab测量三维重建长度的示意图,房屋测量长度为27.74 m;(b)是用谷歌Earth测量房屋实际长度的示意图,长度为27.71 m。以MeshLab测量结果为观测值,以谷歌地球的测量结果为真值,重建误差约为0.09%。

图8显示了我们重建的道路宽度与谷歌Earth的对比。(a)为MeshLab测量的重建道路宽度,宽度为4.21 m;(b)为在谷歌Earth上人工测量的道路实际宽度,测量宽度为4.20 m。重建后道路宽度的相对误差约为0.24%。
 4.4.2. Qualitative Evaluation of Reconstruction
4.4.2. Qualitative Evaluation of Reconstruction
图9显示了我们的方法相对于DynSLAM对序列06中相同场景的重建质量。我们重建的点云总数为4.8 × 109, DynSLAM生成的点云总数为20 × 109。由于激光雷达的扫描角度较小,我们无法对全视图进行三维重建,并且对冗余和噪声进行了过滤,因此点云总量相对较小,所需存储容量比DynSLAM低约76%。
图10显示了我们的方法与DynSLAM算法对同一堵墙的重构质量的比较。(a)为序列06的第十幅图片。以(a)右侧的白墙为参考,将我们在(c)中的重建质量与(b)中的DynSLAM进行对比。从对比中可以看出,DynSLAM重建的墙体变形严重,但我们的方法恢复的墙体几何形状是正确的。

序列00记录城市场景的尺寸为564 m× 496 m。图11显示了序列00重建的结果,地图上的车辆、草坪、树木、道路等对象用不同的颜色表示。语义重建保持了场景的几何结构,无人驾驶汽车利用重构后的地图中的语义信息来帮助完成避障导航任务。Daniel等人的[35]融合了来自相机的语义图像和激光雷达点云,他们的重点是越野地形。相比之下,我们的方法可以应用于城市驾驶场景。与我们的方法类似,为了维护和自动标注大型三维点云地图,David等人[36]也将Lidar点云投影到语义分割的2D图像上,并将点云与语义标签关联起来。然而,为了推断出稀疏Lidar点的底层几何特征,需要在实验区域内进行一次驱动,对之前构建的密集地图提取小的密集区域,然后进行语义重构。我们的方法通过深度插值来解决稀疏性问题。当无人驾驶汽车首次行驶时,定位和语义重构可以同时进行,而不需要预先构建地图。通过融合激光雷达和单目摄像机,我们的方法能够在不需要人工标注的情况下,在单次场景中自动生成带有道路特征的世界表示。

5. Conclusions
本文提出了一种基于激光雷达和单目视觉融合的SLAM和三维语义重建方法。我们设计了一种深度插值算法,并利用语义分割网络BiSeNetV2实现语义图像与激光雷达扫描的融合。利用激光雷达点提供的精确深度信息,优化基于特征的V-SLAM定位精度。我们还添加了一个密集的映射线程,结合姿态和语义信息,在定位无人车的同时,同时重构室外场景的三维语义地图。通过在KITTI Visual Odometry数据集上的实验验证,我们可以得出以下结论:
(1)基于投影和插值方法,对稀疏激光雷达点云进行上采样,并与高分辨率二维图像进行融合。语义分割图像用于提供语义信息。实验结果表明,融合数据具有较高的分辨率和可见性,可以作为输入实现后续算法的操作和实验验证。
(2)将本方法与基于视觉的SLAM方法和激光雷达视觉融合SLAM方法进行比较,并在KITTI Visual Odometry数据集上进行实验。结果表明,与ORB-SLAM2和DynaSLAM相比,该方法在所有11个序列上的定位误差都大大降低。与DEMO和DVL-SLAM相比,基于Lidar-vision融合的定位精度也得到了提高。
(3)在三维重建方面,我们重建的物体的宽度与在谷歌地球上测量的数据相比相差不到0.5%。与室外环境三维重建的DynSLAM相比,我们的重建具有更高的质量,并减少了76%的存储空间。地图表示可以随时间不断更新。同时,生成的语义重建具有人类可以理解的标签。可以更好的支持未来自动驾驶技术的实际应用。
在未来,我们将考虑融合更多的传感器来提高定位精度和重建质量,例如通过结合摄像机和imu来构建VIO系统,使算法在缺乏可提取特征点的场景中更好地工作。
总结:
感觉思路简单但是工作量很多整体感觉很充实,尤其是最后的实验部分,感觉做我毕设都绰绰有余了,感觉真的是好几个作者一起完成的不太像一个人的工作量吧。和谷歌地图比较也是我没想到的。不过其实语义没有用到定位上、激光雷达也没有用作分割。其实简单来看主要工作为:
1、把二维图像语义信息给插值后的密集点云信息上色,完成语义分割任务
2、轨迹方面原来是通过orbslam2中的三角化出深度,这里用的插值后的深度(其实这里相当于用了密集深度,密集深度是激光雷达的插值)
3、增量式地图拼接
部分个人理解和疑问在文中()里标出,欢迎探讨~