深度学习推荐系统(四)Wide&Deep模型及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。

1 Wide&Deep模型原理
1.1 Wide&Deep模型提出的背景
-
简单的模型, 比如协同过滤, 逻辑回归等,能够从历史数据中学习到高频共现的特征组合能力, 但是泛化能力不足
-
而像矩阵分解, embedding再加上深度学习网络, 能够利用相关性的传递性去探索历史数据中未出现的特征组合, 挖掘数据潜在的关联模式, 但是对于某些特定的场景(数据分布长尾, 共现矩阵稀疏高秩)很难有效学习低纬度的表示, 造成推荐的过渡泛化。
因此,在2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式, 奠定了后面深度学习模型的基础,是一个里程碑式的改变。
1.2 模型的记忆能力和泛化能力
1.2.1 记忆能力的理解
记忆能力可以被理解为模型直接学习并利用历史数据中物品和特征的共现频率的能力。
一般来说, 协同过滤、逻辑回归这种都具有较强的“记忆能力”, 由于这类模型比较简单, 原始数据往往可以直接影响推荐结果, 产生类似于如果点击A, 就推荐B这类规则的推荐, 相当于模型直接记住了历史数据的分布特点, 并利用这些记忆进行推荐。
以谷歌APP推荐场景为例理解一下:
假设在Google Play推荐模型训练过程中,设置如下组合特征:AND(user_installed_app=netflix,
impression_app=pandora),它代表了用户安装了netflix这款应用,而且曾在应用商店中看到过pandora这款应用。
如果以“最终是否安装pandora”为标签,可以轻而易举的统计netfilx&pandora这个特征与安装pandora标签之间的共现频率。比如二者的共现频率高达10%,那么在设计模型的时候,就希望模型只要发现这一特征,就推荐pandora这款应用(像一个深刻记忆点一样印在脑海),这就是所谓的“记忆能力”。
像逻辑回归这样的模型,发现这样的强特,就会加大权重,对这种特征直接记忆。
但是对于神经网络这样的模型来说,特征会被多层处理,不断与其他特征进行交叉,因此模型这个强特记忆反而没有简单模型的深刻。
1.2.2 泛化能力的理解
泛化能力可以被理解为模型传递特征的相关性, 以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。
比如矩阵分解, embedding等, 使得数据稀少的用户或者物品也能生成隐向量, 从而获得由数据支撑的推荐得分, 将全局数据传递到了稀疏物品上, 提高泛化能力。
再比如神经网络, 通过特征自动组合, 可以深度发掘数据中的潜在模式,提高泛化等。
所以, Wide&Deep模型的直接动机就是将两者进行融合, 使得模型既有了简单模型的这种“记忆能力”, 也有了神经网络的这种“泛化能力”, 这也是记忆与泛化结合的伟大模式的初始尝试。
1.3 Wide&Deep的模型结构
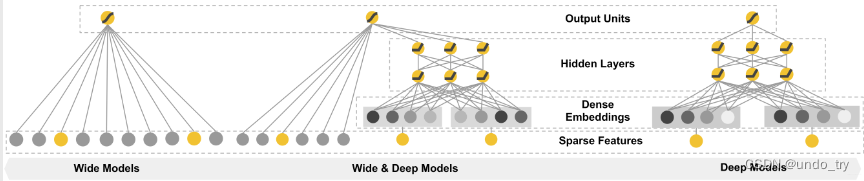
经典的W&D的模型如图所示:
-
左边的是wide部分, 也就是一个简单的线性模型, 右边是deep部分, 一个经典的DNN模型
-
W&D模型把单输入层的
Wide部分和Embedding+多层的全连接的部分(deep部分)连接起来, 一起输入最终的输出层得到预测结果 -
单层的wide层善于处理大量的稀疏的id类特征, Deep部分利用深层的特征交叉, 挖掘在特征背后的数据模式。 最终, 利用逻辑回归, 输出层部分和Deep组合起来, 形成统一的模型。
1.3.1 Wide部分

-
对于wide部分训练时候使用的优化器是
带正则的FTRL算法(Follow-the-regularized-leader),可以把FTRL当作一个稀疏性很好,精度又不错的随机梯度下降方法, 该算法是非常注重模型稀疏性质的。 -
也就是说W&D模型采用L1 FTRL是
想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。 -
Wide部分模型训练完之后留下来的特征都是非常重要的,
模型的“记忆能力”可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。
1.3.2 Deep部分
-
Deep部分主要是
一个Embedding+MLP的神经网络模型。 -
大规模稀疏特征通过embedding转化为低维密集型特征。然后特征进行拼接输入到MLP中,挖掘藏在特征背后的数据模式。
-
输入的特征有两类, 一类是数值型特征, 一类是类别型特征(经过embedding)。
-
DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。
-
对于Deep部分的DNN模型作者使用了深度学习常用的
优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
1.3.3 Wide&Deep的模型详细结构

从上图我们可以详细地了解Google Play推荐团队设计的 Wide&Deep 模型到底将哪些特征作为 Deep 部分的输入,将哪些特征作为 Wide 部分的输入。
-
Wide 部分的输入仅仅是
已安装应用和曝光应用两类特征,其中已安装应用代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥 Wide部分记忆能力强的优势。 -
Deep 部分的输入是全量的特征向量,包括用户年龄 (Age )、已安装应用数量(#App Installs )、设备类型(Device Class )、已安装应用(User Installed App)、曝光应用(Impression App)等特征。已安装应用、曝光应用等类别型特征,需要经过 Embedding 层输人连接层(Concatenated Embedding),拼接成1200维的再依次经过3层ReLU全连接层,最终输入 LogLoss 输出层Embedding向量。
1.4 Wide&Deep模型代码
import torch.nn as nn
import torch.nn.functional as F
import torch
class Linear(nn.Module):
"""
Linear part
"""
def __init__(self, input_dim):
super(Linear, self).__init__()
self.linear = nn.Linear(in_features=input_dim, out_features=1)
def forward(self, x):
return self.linear(x)
class Dnn(nn.Module):
"""
Dnn part
"""
def __init__(self, hidden_units, dropout=0.5):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout: 失活率
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList(
[nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
'''
WideDeep模型:
主要包括Wide部分和Deep部分
'''
class WideDeep(nn.Module):
def __init__(self, feature_info, hidden_units, embed_dim=8):
"""
DeepCrossing:
feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)
hidden_units: 列表, 隐藏单元
dropout: Dropout层的失活比例
embed_dim: embedding维度
"""
super(WideDeep, self).__init__()
self.dense_features, self.sparse_features, self.sparse_features_map = feature_info
# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding
self.embed_layers = nn.ModuleDict(
{
'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)
for key, val in self.sparse_features_map.items()
}
)
# 统计embedding_dim的总维度
# 一个离散型(类别型)变量 通过embedding层变为8纬
embed_dim_sum = sum([embed_dim] * len(self.sparse_features))
# 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度
dim_sum = len(self.dense_features) + embed_dim_sum
hidden_units.insert(0, dim_sum)
# dnn网络
self.dnn_network = Dnn(hidden_units)
# 线性层
self.linear = Linear(input_dim=len(self.dense_features))
# 最终的线性层
self.final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
# 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样
dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]
# 2、转换为long形
sparse_inputs = sparse_inputs.long()
# 2、不同的类别特征分别embedding
sparse_embeds = [
self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i in
zip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))
]
# 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
# 4、数值型和类别型特征进行拼接
dnn_input = torch.cat([sparse_embeds, dense_input], axis=-1)
# Wide部分,使用的特征为数值型类型
wide_out = self.linear(dense_input)
# Deep部分,使用全部特征
deep_out = self.dnn_network(dnn_input)
deep_out = self.final_linear(deep_out)
# out 将Wide部分的输出和Deep部分的输出进行合并
outputs = F.sigmoid(0.5 * (wide_out + deep_out))
return outputs
if __name__ == '__main__':
x = torch.rand(size=(1, 5), dtype=torch.float32)
feature_info = [
['I1', 'I2'], # 连续性特征
['C1', 'C2', 'C3'], # 离散型特征
{
'C1': 20,
'C2': 20,
'C3': 20
}
]
# 建立模型
hidden_units = [256, 128, 64]
net = WideDeep(feature_info, hidden_units)
print(net)
print(net(x))
WideDeep(
(embed_layers): ModuleDict(
(embed_C1): Embedding(20, 8)
(embed_C2): Embedding(20, 8)
(embed_C3): Embedding(20, 8)
)
(dnn_network): Dnn(
(dnn_network): ModuleList(
(0): Linear(in_features=26, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=128, bias=True)
(2): Linear(in_features=128, out_features=64, bias=True)
)
(dropout): Dropout(p=0.5, inplace=False)
)
(linear): Linear(
(linear): Linear(in_features=2, out_features=1, bias=True)
)
(final_linear): Linear(in_features=64, out_features=1, bias=True)
)
tensor([[0.6531]], grad_fn=<SigmoidBackward0>)
2 Wide&Deep模型在Criteo数据集的应用
数据的预处理及一些函数或类可以参考:
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
2.1 准备训练数据
import pandas as pd
import torch
from torch.utils.data import TensorDataset, Dataset, DataLoader
import torch.nn as nn
from sklearn.metrics import auc, roc_auc_score, roc_curve
import warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):
# 读入训练集,验证集和测试集
train_set = pd.read_csv(file_path + 'train_set.csv')
val_set = pd.read_csv(file_path + 'val_set.csv')
test_set = pd.read_csv(file_path + 'test.csv')
# 这里需要把特征分成数值型和离散型
# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样
data_df = pd.concat((train_set, val_set, test_set))
# 数值型特征直接放入stacking层
dense_features = ['I' + str(i) for i in range(1, 14)]
# 离散型特征需要需要进行embedding处理
sparse_features = ['C' + str(i) for i in range(1, 27)]
# 定义一个稀疏特征的embedding映射, 字典{key: value},
# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度
sparse_feas_map = {
}
for key in sparse_features:
sparse_feas_map[key] = data_df[key].nunique()
feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入
# 把数据构建成数据管道
dl_train_dataset = TensorDataset(
# 特征信息
torch.tensor(train_set.drop(columns='Label').values).float(),
# 标签信息
torch.tensor(train_set['Label'].values).float()
)
dl_val_dataset = TensorDataset(
# 特征信息
torch.tensor(val_set.drop(columns='Label').values).float(),
# 标签信息
torch.tensor(val_set['Label'].values).float()
)
dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)
dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)
return feature_info,dl_train,dl_vaild,test_set
file_path = './preprocessed_data/'
feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.2 建立Wide&Deep模型
from _01_wide_deep import WideDeep
hidden_units = [256, 128, 64]
net = WideDeep(feature_info, hidden_units)
2.3 模型的训练
from AnimatorClass import Animator
from TimerClass import Timer
# 模型的相关设置
def metric_func(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred)
def try_gpu(i=0):
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{
i}')
return torch.device('cpu')
def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):
"""⽤GPU训练模型"""
print('training on', device)
net.to(device)
# 二值交叉熵损失
loss_func = nn.BCELoss()
# 注意:这里没有使用原理提到的优化器
optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc']
,figsize=(8.0, 6.0))
timer, num_batches = Timer(), len(dl_train)
log_step_freq = 10
for epoch in range(1, num_epochs + 1):
# 训练阶段
net.train()
loss_sum = 0.0
metric_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
timer.start()
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels.unsqueeze(1) )
try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播求梯度
loss.backward()
optimizer.step()
timer.stop()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))
# 验证阶段
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
for val_step, (features, labels) in enumerate(dl_vaild, 1):
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions, labels.unsqueeze(1))
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
if val_step % log_step_freq == 0:
animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))
print(f'final: loss {
loss_sum/len(dl_train):.3f}, auc {
metric_sum/len(dl_train):.3f},'
f' val loss {
val_loss_sum/len(dl_vaild):.3f}, val auc {
val_metric_sum/len(dl_vaild):.3f}')
print(f'{
num_batches * num_epochs / timer.sum():.1f} examples/sec on {
str(device)}')
lr, num_epochs = 0.001, 10
# 其实发生了过拟合
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())

2.4 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float())
y_pred = torch.where(
y_pred_probs>0.5,
torch.ones_like(y_pred_probs),
torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]