wide&deep 模型
-
简介:
wide&deep模型是一种广泛应用与广告推荐系统的模型,具有很好的记忆能力和泛化能力。 -
图形结构:
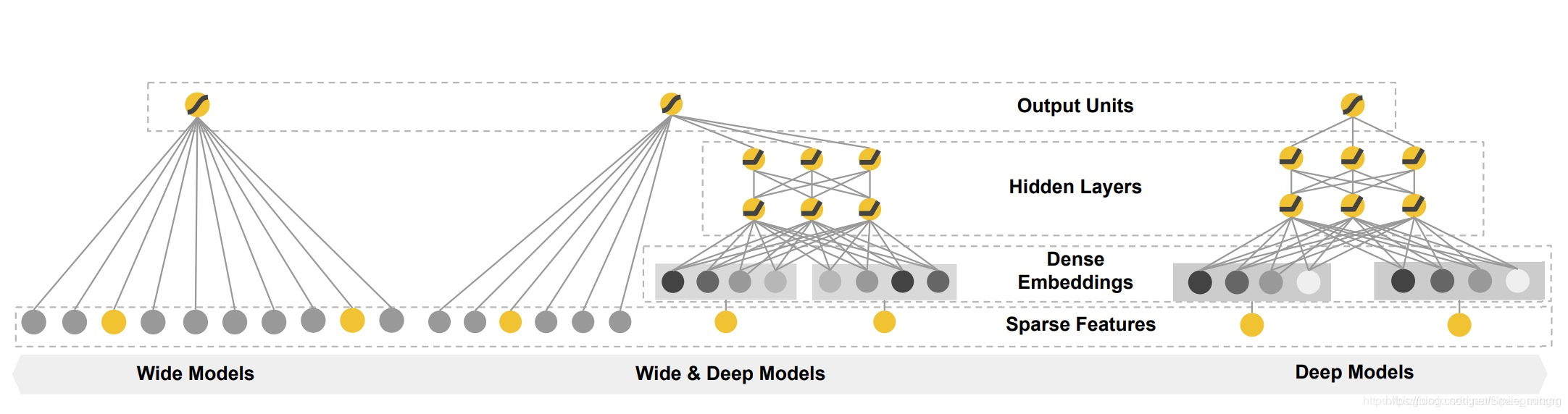
-
在Google Play中的应用
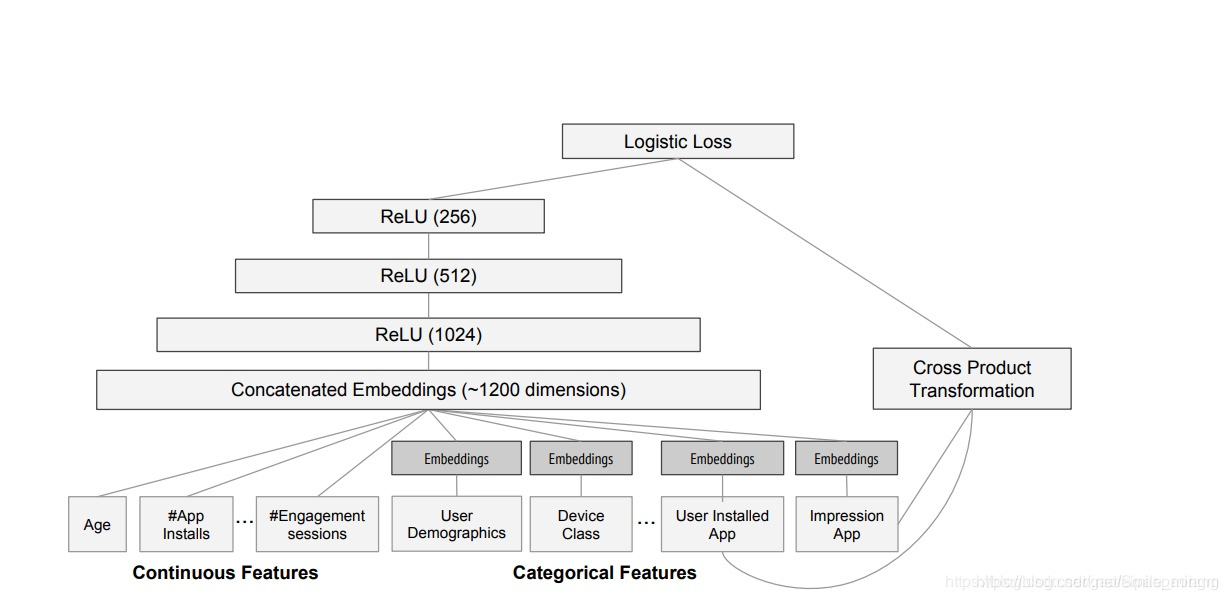
-
原理简介:
- wide端:
- 对于离散型特征,进行hash(哈希编码)
- 对于连续型特征,离散化,以及再作交叉的特征
- Wide模型如第一幅图中的左侧的图所示,实际上,Wide模型就是一个广义线性模型:
其中,特征 是一个d维的向量, 为模型的参数。最终在y的基础上增加Sigmoid函数作为最终的输出。
- deep端:
- 离散型特征:hash值的embedding
- 连续型特征:直接输入
- Deep模型如第一图中的右侧的图所示,实际上,Deep模型是一个前馈神经网络。深度神经网络模型通常需要的输入是连续的稠密特征,对于稀疏,高维的类别特征,通常首先将其转换为低维的向量,这个过程也称为embedding。
- wide端:
在上一篇回归模型基础上的修改
- 普通形式构建模型
# model不再是严格的层级结构,而是由两部分组成,每部分都是一个层级结构
# 故不可使用sequential的方式
# 使用函数是API 功能API
# wide层:输入后直接输出
# x_train.shape[1:]:表示x_train的第一行有多少列,也就是有每条数据有多少特征
input = keras.layers.Input(shape=x_train.shape[1:])
# deep层
hidden1 = keras.layers.Dense(30, activation='relu')(input)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
# 用concatenate实现wide层和deep层的拼接
concat = keras.layers.concatenate([input, hidden2])
# 输出
output = keras.layers.Dense(1)(concat)
# 将model固化下来
model = keras.models.Model(inputs = [input],
outputs = [output])
model.summary()
optimizer=tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mean_squared_error',optimizer=optimizer)
callbacks = [keras.callbacks.EarlyStopping(
patience=5,min_delta=1e-2)]
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 8)] 0
__________________________________________________________________________________________________
dense_3 (Dense) (None, 30) 270 input_2[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 30) 930 dense_3[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 38) 0 input_2[0][0]
dense_4[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 1) 39 concatenate_1[0][0]
==================================================================================================
Total params: 1,239
Trainable params: 1,239
Non-trainable params: 0
__________________________________________________________________________________________________
- 利用子类API构建模型
# 子类API
class WideDeepModel(keras.models.Model):
def __init__(self):
super(WideDeepModel, self).__init__()
"""定义模型的层次"""
self.hidden1_layer = keras.layers.Dense(30,activation='relu')
self.hidden2_layer = keras.layers.Dense(30,activation='relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
"""完成模型的正向计算"""
hidden1 = self.hidden1_layer(input)
hidden2 = self.hidden2_layer(hidden1)
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return output
model = WideDeepModel()
model.build(input_shape=(None, 8))
model.summary()
optimizer=tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mean_squared_error',optimizer=optimizer)
callbacks = [keras.callbacks.EarlyStopping(
patience=5,min_delta=1e-2)]
- 训练模型
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs =100,
callbacks = callbacks)
Train on 11610 samples, validate on 3870 samples
Epoch 1/100
11610/11610 [==============================] - 2s 190us/sample - loss: 1.1765 - val_loss: 0.5351
Epoch 2/100
11610/11610 [==============================] - 1s 81us/sample - loss: 0.6157 - val_loss: 0.4779
Epoch 3/100
11610/11610 [==============================] - 1s 79us/sample - loss: 0.5123 - val_loss: 0.4355
Epoch 4/100
11610/11610 [==============================] - 1s 72us/sample - loss: 0.4331 - val_loss: 0.3995
Epoch 5/100
11610/11610 [==============================] - 1s 71us/sample - loss: 0.3833 - val_loss: 0.3756
Epoch 6/100
11610/11610 [==============================] - 1s 72us/sample - loss: 0.3596 - val_loss: 0.3624
Epoch 7/100
11610/11610 [==============================] - 1s 84us/sample - loss: 0.3591 - val_loss: 0.3585
Epoch 8/100
11610/11610 [==============================] - 1s 72us/sample - loss: 0.3544 - val_loss: 0.3472
Epoch 9/100
11610/11610 [==============================] - 1s 73us/sample - loss: 0.3442 - val_loss: 0.3491
Epoch 10/100
11610/11610 [==============================] - 1s 80us/sample - loss: 0.3462 - val_loss: 0.3390
Epoch 11/100
11610/11610 [==============================] - 1s 86us/sample - loss: 0.3348 - val_loss: 0.3326
Epoch 12/100
11610/11610 [==============================] - 1s 80us/sample - loss: 0.3253 - val_loss: 0.3299
Epoch 13/100
11610/11610 [==============================] - 2s 130us/sample - loss: 0.3185 - val_loss: 0.3377
Epoch 14/100
11610/11610 [==============================] - 1s 108us/sample - loss: 0.3172 - val_loss: 0.3175
Epoch 15/100
11610/11610 [==============================] - 1s 91us/sample - loss: 0.3077 - val_loss: 0.3278
Epoch 16/100
11610/11610 [==============================] - 1s 95us/sample - loss: 0.3035 - val_loss: 0.3116
Epoch 17/100
11610/11610 [==============================] - 1s 100us/sample - loss: 0.3045 - val_loss: 0.3080
Epoch 18/100
11610/11610 [==============================] - 1s 80us/sample - loss: 0.3016 - val_loss: 0.3076
Epoch 19/100
11610/11610 [==============================] - 1s 83us/sample - loss: 0.2969 - val_loss: 0.3218
- 模型训练结果
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
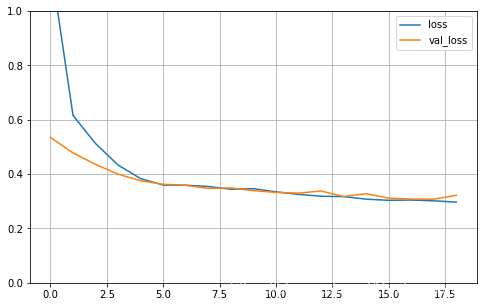
- 模型测试结果
model.evaluate(x_test_scaled, y_test, verbose=0)
0.33885509528855023
