摘要
广义线性模型和非线性特征变换的组合广泛用于输入稀疏的大规模回归和分类问题。特征的交叉非常有效并且可解释性也很好,但是为了提高模型泛化能力,需要大量的特征工程工作。深度神经网络可以更好的通过稀疏特征的低纬稠密向量泛化到非显性的特征组合。但是当用户物品的交互数据比较稀疏的时候,深度神经网络可能会过拟合。本文我们提出wide & deep 学习,同时训练线性模型和深度模型,结合了记忆与泛化的优点。我们在Google Play商店内的10亿用户和百万App上评测了我们的模型,结果显示相比纯wide和纯deep模型,wide & deep模型显著提升了app的下载数。我们也开源了模型的tensorflow实现。
1 简介
推荐系统可以看做一个搜索排序系统,搜索的输入是用户和上下文信息,输出是一个有序的物品列表。给定一个输入,推荐任务首先就是在数据库中找到相关的物品,然后基于特定的目标比如点击和购买,将相关物品进行排序。
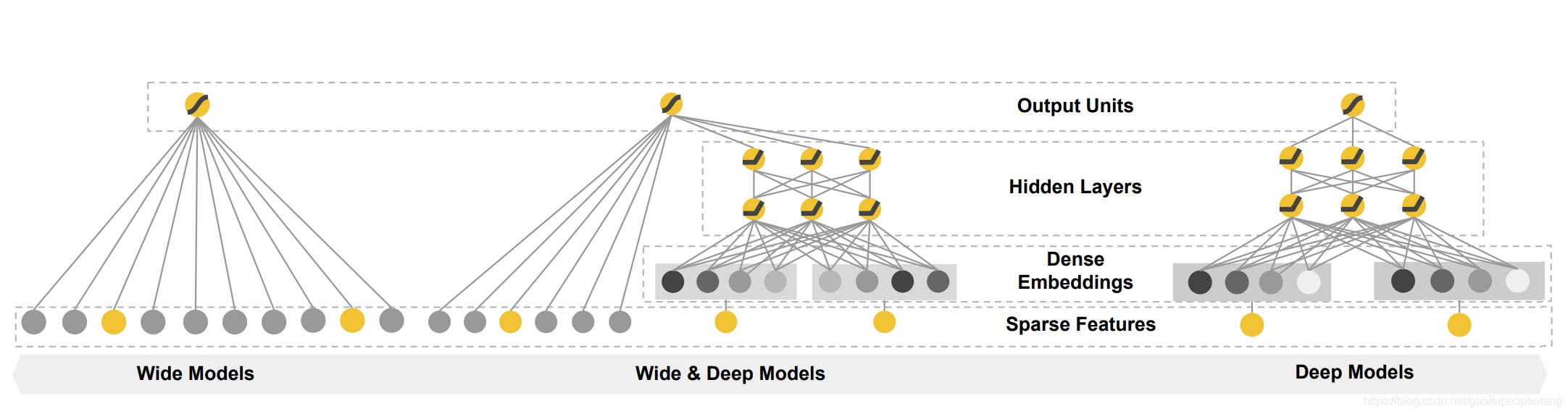
类似与通用的搜索排序问题,推荐系统的挑战之一是实现记忆与泛化。记忆可以简单定义为学习并利用物品或特征在历史数据中的的共现关系。泛化则是基于相关性的传递性,探索历史数据中未出现或很少出现的组合。基于记忆的推荐系统通常更加主题化,推荐的物品跟用户历史物品比较直接相关。而基于泛化的推荐,倾向于提升推荐物品的多样性。本文中我们主要关注Google Play的App推荐,但是方式同样适合与通用的推荐系统。
对于大规模的在线推荐和排序系统,广义的线性模型的使用非常广泛,因为它们简单、易扩展、解释性良好。模型的特征经常采用二值的稀疏特征,经过one-hot编码。二值特征例如"user_installed_app=netflix", 值为1表示用户安装了Netflix。 通过特征的交叉操作,比如特征AND(user_installed_category=netflix,impression_app=pandora),值为1表示用户安装了netflix,喜欢的app为Pandora. 此特征可以解释这一对原始特征与目标标签的相关性。如果需要加入泛化,则可以选择具有泛化性的特征,比如AND(user_installed_category=video,impression_category=music)。这样做的缺点是通常需要大量特征工程,来筛选出有用的特征组合。特征交叉的另一个局限是没法学习到历史数据中未曾出现的特征组合。
基于Embedding的模型,比如FM和深度神经网络,通过为每个特征学习一个低纬稠密的Embeddding向量,可以泛化到历史数据中未出现的特征组合。但是,如果历史数据稀疏并且高秩(high-rank),则很难学习到有效的embedding表示。
本文我们提出Wide&Deep学习框架,实现记忆与泛化的结合。本文的主要贡献有:
- Wide & Deep框架,同时训练前向反馈神经网络与线性模型
- 模型在Google Play商店的10亿用户和一百万的app上部署和评测
- 开源了模型的Tensorflow实现
推荐系统概要
系统的结构图如下所示。当用户访问商店的时候,包含用户和上下文信息的多种特征作为推荐系统的输入,推荐系统返回一个app列表。用户可能会点击或购买这些app。用户的这些行为会被记录,作为模型的训练数据。
由于物品数量达到百万量级,每次请求为每个物品打分不可行。因此推荐的第一步是召回,从数据库中获取最匹配的若干个候选物品。第二步是排序,对候选物品进行打分。得分通常是记为 ,表示给定特征 ,标签 出现的概率。本文中我们主要关注排序模型。
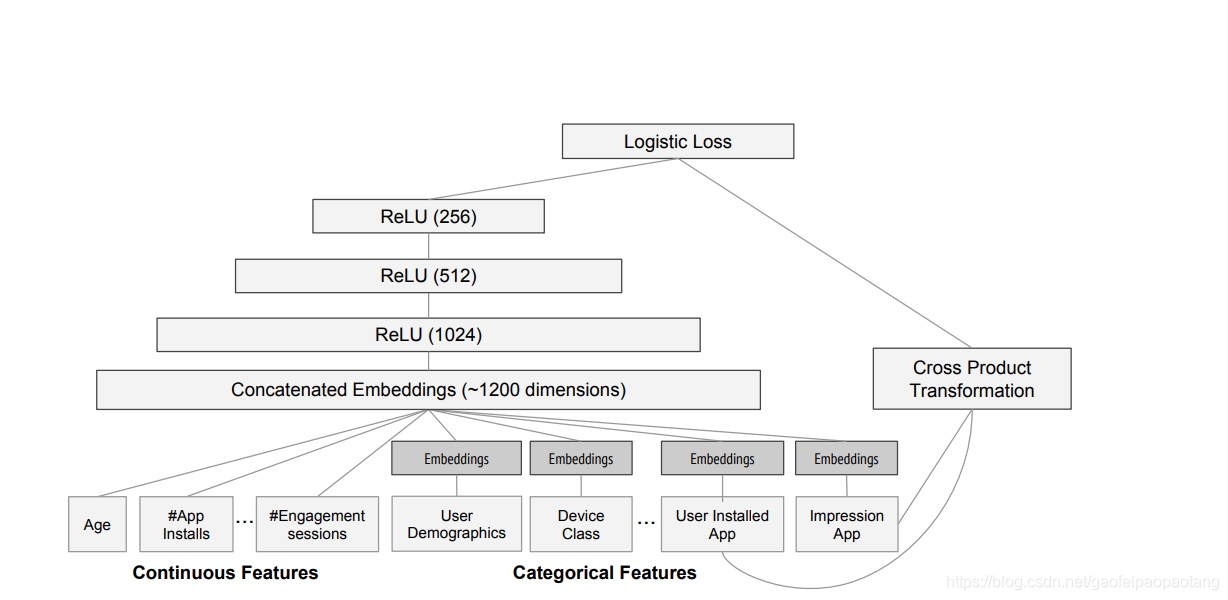
3. Wide & Deep learning
3.1 wide部分
wide部分是广义线性模型: ,其中 表示预测值, 表示 个特征, 表示模型参数, 表示偏移。特征包括原始特征和转换特征。其中一个重要的转换特征就是特征交叉变换,变换方式为:
其中 是一个布尔变量,为1表示第 个特征是第 个转换特征组成部分。例如转换特征AND(gender=femain,language=en)为1,当且仅当(gender=female)和(language=en)都为1.
3.2 深度部分
深度部分是神经网络。稀疏的离散特征首先经过embedding层,转化为低纬的稠密向量,向量的纬度从10到100不等。embedding向量连接之后,输入到隐藏网络层,每一层隐藏网络层的操作为:
其中 表示 层的输出, 为激活函数,一般为ReLU函数。 表示网络的参数。
3.3 联合训练
联合训练(joint training)有别于集成(ensemble),集成中训练阶段多个模型是独立分开训练的,并不知道彼此的存在,在预测阶段预测值综合了多个模型的预测值。相反,联合训练阶段则同时训练多个模型,共同优化参数。
在实验中,我们使用FTRL算法优化wide部分的参数,AdaGrad算法优化深度部分的参数。
在二分类任务中,模型的预测值为:
4. 系统实现
实验中采用的模型结果入下图所示: