修改前篇代码中的输入与输出
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]
x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]
x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]
input_wide = keras.layers.Input(shape=5)
input_deep = keras.layers.Input(shape=6)
hidden1= keras.layers.Dense(30, activation='relu')(input_deep)
hidden2= keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.concatenate([hidden2, input_wide])
output = keras.layers.Dense(1)(concat)
output2 = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs = [input_wide, input_deep],
outputs = [output, output2])
model.summary()
optimizer=tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mean_squared_error',optimizer=optimizer)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 6)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 30) 210 input_2[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 30) 930 dense[0][0]
__________________________________________________________________________________________________
input_1 (InputLayer) [(None, 5)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 35) 0 dense_1[0][0]
input_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 36 concatenate[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1) 31 dense_1[0][0]
==================================================================================================
Total params: 1,207
Trainable params: 1,207
Non-trainable params: 0
__________________________________________________________________________________________________
logdir = os.path.join("callbacks_wide_deep")
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(log_dir=logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only=True),
keras.callbacks.EarlyStopping(patience=5,min_delta=1e-2),
]
history = model.fit([x_train_scaled_wide, x_train_scaled_deep], [y_train, y_train],
validation_data = ([x_valid_scaled_wide, x_valid_scaled_deep], [y_valid, y_valid]),
epochs =100,
callbacks = callbacks)
Train on 11610 samples, validate on 3870 samples
Epoch 1/100
32/11610 [..............................] - ETA: 10:58 - loss: 13.1608 - dense_2_loss: 6.8929 - dense_3_loss: 6.2679WARNING:tensorflow:Method (on_train_batch_end) is slow compared to the batch update (0.131143). Check your callbacks.
11610/11610 [==============================] - 4s 311us/sample - loss: 3.5138 - dense_2_loss: 1.9399 - dense_3_loss: 1.5727 - val_loss: 1.5413 - val_dense_2_loss: 0.7600 - val_dense_3_loss: 0.7810
Epoch 2/100
11610/11610 [==============================] - 1s 101us/sample - loss: 1.5257 - dense_2_loss: 0.6649 - dense_3_loss: 0.8603 - val_loss: 1.1683 - val_dense_2_loss: 0.5100 - val_dense_3_loss: 0.6581
Epoch 3/100
11610/11610 [==============================] - 1s 98us/sample - loss: 1.1269 - dense_2_loss: 0.4609 - dense_3_loss: 0.6657 - val_loss: 1.0342 - val_dense_2_loss: 0.4463 - val_dense_3_loss: 0.5878
Epoch 4/100
11610/11610 [==============================] - 1s 93us/sample - loss: 0.9494 - dense_2_loss: 0.4014 - dense_3_loss: 0.5480 - val_loss: 0.9207 - val_dense_2_loss: 0.4070 - val_dense_3_loss: 0.5136
Epoch 5/100
11610/11610 [==============================] - 1s 103us/sample - loss: 0.8688 - dense_2_loss: 0.3890 - dense_3_loss: 0.4796 - val_loss: 0.9022 - val_dense_2_loss: 0.4148 - val_dense_3_loss: 0.4873
Epoch 6/100
11610/11610 [==============================] - 1s 108us/sample - loss: 0.8366 - dense_2_loss: 0.3822 - dense_3_loss: 0.4544 - val_loss: 0.8422 - val_dense_2_loss: 0.3897 - val_dense_3_loss: 0.4523
Epoch 7/100
11610/11610 [==============================] - 1s 106us/sample - loss: 0.8119 - dense_2_loss: 0.3725 - dense_3_loss: 0.4391 - val_loss: 0.8304 - val_dense_2_loss: 0.3797 - val_dense_3_loss: 0.4506
Epoch 8/100
11610/11610 [==============================] - 2s 131us/sample - loss: 0.7745 - dense_2_loss: 0.3520 - dense_3_loss: 0.4224 - val_loss: 0.8054 - val_dense_2_loss: 0.3803 - val_dense_3_loss: 0.4250
Epoch 9/100
11610/11610 [==============================] - 1s 123us/sample - loss: 0.7741 - dense_2_loss: 0.3536 - dense_3_loss: 0.4207 - val_loss: 0.7933 - val_dense_2_loss: 0.3613 - val_dense_3_loss: 0.4320
Epoch 10/100
11610/11610 [==============================] - 1s 101us/sample - loss: 0.7581 - dense_2_loss: 0.3483 - dense_3_loss: 0.4097 - val_loss: 0.7863 - val_dense_2_loss: 0.3569 - val_dense_3_loss: 0.4293
Epoch 11/100
11610/11610 [==============================] - 1s 98us/sample - loss: 0.7466 - dense_2_loss: 0.3430 - dense_3_loss: 0.4038 - val_loss: 0.7664 - val_dense_2_loss: 0.3618 - val_dense_3_loss: 0.4045
Epoch 12/100
11610/11610 [==============================] - 1s 91us/sample - loss: 0.7407 - dense_2_loss: 0.3419 - dense_3_loss: 0.3988 - val_loss: 0.7987 - val_dense_2_loss: 0.3779 - val_dense_3_loss: 0.4207
Epoch 13/100
11610/11610 [==============================] - 1s 95us/sample - loss: 0.7370 - dense_2_loss: 0.3402 - dense_3_loss: 0.3967 - val_loss: 0.7555 - val_dense_2_loss: 0.3541 - val_dense_3_loss: 0.4013
Epoch 14/100
11610/11610 [==============================] - 1s 101us/sample - loss: 0.7414 - dense_2_loss: 0.3456 - dense_3_loss: 0.3958 - val_loss: 0.7515 - val_dense_2_loss: 0.3492 - val_dense_3_loss: 0.4022
Epoch 15/100
11610/11610 [==============================] - 1s 91us/sample - loss: 0.7320 - dense_2_loss: 0.3406 - dense_3_loss: 0.3916 - val_loss: 0.7325 - val_dense_2_loss: 0.3358 - val_dense_3_loss: 0.3966
Epoch 16/100
11610/11610 [==============================] - 1s 91us/sample - loss: 0.7126 - dense_2_loss: 0.3280 - dense_3_loss: 0.3848 - val_loss: 0.7394 - val_dense_2_loss: 0.3398 - val_dense_3_loss: 0.3995
Epoch 17/100
11610/11610 [==============================] - 1s 92us/sample - loss: 0.7189 - dense_2_loss: 0.3318 - dense_3_loss: 0.3872 - val_loss: 0.7399 - val_dense_2_loss: 0.3412 - val_dense_3_loss: 0.3985
Epoch 18/100
11610/11610 [==============================] - 1s 88us/sample - loss: 0.7206 - dense_2_loss: 0.3333 - dense_3_loss: 0.3873 - val_loss: 0.7423 - val_dense_2_loss: 0.3475 - val_dense_3_loss: 0.3946
Epoch 19/100
11610/11610 [==============================] - 1s 97us/sample - loss: 0.7104 - dense_2_loss: 0.3269 - dense_3_loss: 0.3834 - val_loss: 0.7296 - val_dense_2_loss: 0.3399 - val_dense_3_loss: 0.3895
Epoch 20/100
11610/11610 [==============================] - 1s 91us/sample - loss: 0.7029 - dense_2_loss: 0.3240 - dense_3_loss: 0.3787 - val_loss: 0.7194 - val_dense_2_loss: 0.3355 - val_dense_3_loss: 0.3837
Epoch 21/100
11610/11610 [==============================] - 1s 92us/sample - loss: 0.7043 - dense_2_loss: 0.3263 - dense_3_loss: 0.3779 - val_loss: 0.7088 - val_dense_2_loss: 0.3271 - val_dense_3_loss: 0.3816
Epoch 22/100
11610/11610 [==============================] - 1s 92us/sample - loss: 0.7086 - dense_2_loss: 0.3318 - dense_3_loss: 0.3768 - val_loss: 0.7274 - val_dense_2_loss: 0.3401 - val_dense_3_loss: 0.3871
Epoch 23/100
11610/11610 [==============================] - 1s 97us/sample - loss: 0.6984 - dense_2_loss: 0.3234 - dense_3_loss: 0.3749 - val_loss: 0.7109 - val_dense_2_loss: 0.3256 - val_dense_3_loss: 0.3852
Epoch 24/100
11610/11610 [==============================] - 1s 97us/sample - loss: 0.6927 - dense_2_loss: 0.3206 - dense_3_loss: 0.3722 - val_loss: 0.7086 - val_dense_2_loss: 0.3275 - val_dense_3_loss: 0.3810
Epoch 25/100
11610/11610 [==============================] - 1s 96us/sample - loss: 0.6908 - dense_2_loss: 0.3181 - dense_3_loss: 0.3725 - val_loss: 0.7043 - val_dense_2_loss: 0.3254 - val_dense_3_loss: 0.3788
Epoch 26/100
11610/11610 [==============================] - 1s 86us/sample - loss: 0.6965 - dense_2_loss: 0.3218 - dense_3_loss: 0.3747 - val_loss: 0.7119 - val_dense_2_loss: 0.3325 - val_dense_3_loss: 0.3793
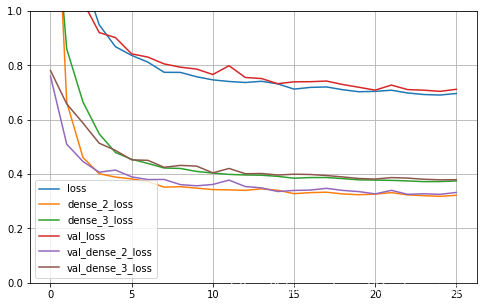
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
model.evaluate([x_test_scaled_wide, x_test_scaled_deep], [y_test, y_test], verbose=2)
5160/1 - 0s - loss: 0.9212 - dense_2_loss: 0.3289 - dense_3_loss: 0.3699
[0.6967352828314138, 0.328909, 0.36990497]
