文章目录
0. Introduction
Google 16年发布的Wide & Deep推荐框架,文章只有4页,思路页很简单。文中设计了一种融合浅层(wide)模型和深层(deep)模型进行联合训练的框架,综合利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对推荐系统准确性和扩展性的兼顾。对提出的W&D模型,文中从推荐效果和服务性能两方面进行评价:
效果上,在Google Play 进行线上A/B实验,W&D模型相比高度优化的Wide浅层模型,app下载率+3.9%。相比deep模型也有一定提升。
性能上,通过切分一次请求需要处理的app 的Batch size为更小的size,并利用多线程并行请求达到提高处理效率的目的。单次响应耗时从31ms下降到14ms。
本文方法的TenforFlow实现已开源, 传送门点这里。
与传统搜索类似,推荐系统的一个挑战是如何同时获得推荐结果准确性和扩展性。推荐的内容都是精准内容,用户兴趣收敛,无新鲜感,不利于长久的用户留存;推荐内容过于泛化,用户的精准兴趣无法得到满足,用户流失风险很大。相比较推荐的准确性,扩展性倾向与改善推荐系统的多样性。
精简概要
- 线性模型学习能力好,深度学习模型泛化能力好。
- google应用在手机app商店,结果提高了应用商店使用率。
- TensorFlow源码公开。
- 召回: 简单的match算法+人工规则。
- 减少候选集后,利用wide&Deep算法进行rerank. 包括特征:用户特征, 文本特征, 偏好特征。
wide模型介绍
在目前大规模线上推荐排序系统中,通用的线性模型如LR被广泛应用。线性模型通常输入二进制的one-hot稀疏表示特征进行训练。比如特征“user_installed_app=netflix”为1,表示用户已安装netflix。交叉特征AND(user_installed_app=netflix,impresion_app=Pandora)表示既安装了netflix app同时又浏览过Pandora的用户特征为1,否则为0。wide模型可以通过利用交叉特征高效的实现记忆能力,达到准确推荐的目的。wide模型通过加入一些宽泛类特征实现一定的泛化能力。但是受限与训练数据,wide模型无法实现训练数据中未曾出现过的泛化。
deep 模型介绍
像FM和DNN这种Embedding类的模型,可以通过学习到的低纬度稠密向量实现模型的泛化能力,包括可以实现对未见过的内容进行泛化推荐。当模型query-item矩阵比较稀疏时,模型的会过分泛化,推荐出很多无相关性的内容,准确性不能得到保证。
W&D模型
文中提出W&D模型,平衡Wide模型和Deep模型的记忆能力和泛化能力。
1. Motivation
在CTR预估任务中利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:
- 特征工程需要耗费太多精力。
- 模型是强行记住这些组合特征的,对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
Wide&Deep模型就是围绕记忆性和泛化性进行讨论的,模型能够从历史数据中学习到高频共现的特征组合的能力,称为是模型的Memorization。能够利用特征之间的传递性去探索历史数据中从未出现过的特征组合,称为是模型的Generalization。Wide&Deep兼顾Memorization与Generalization并在Google Play store的场景中成功落地。

2. Architecture
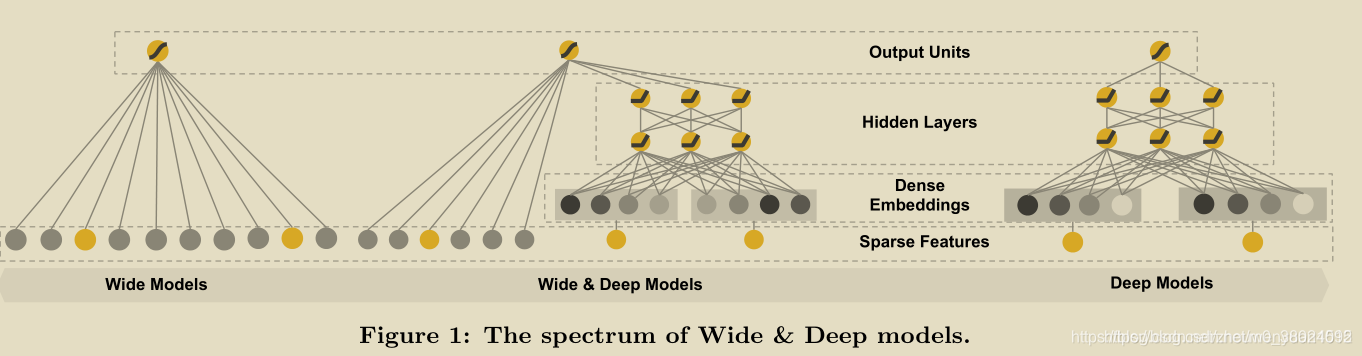
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
如何理解Wide部分有利于增强模型的“记忆能力”,Deep部分有利于增强模型的“泛化能力”?
-
wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation),对于交互特征可以定义为:
ϕ k ( x ) = ∏ i = 1 d x i c k i , c k i ∈ { 0 , 1 } \phi_{k}(x)=\prod_{i=1}^d x_i^{c_{ki}}, c_{ki}\in \{0,1\} ϕk(x)=i=1∏dxicki,cki∈{ 0,1}
c k i c_{ki} cki是一个布尔变量,当第i个特征属于第k个特征组合时, c k i c_{ki} cki的值为1,否则为0, x i x_i xi是第i个特征的值,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。用原论文的例子举例:AND(user_installed_app=QQ, impression_app=WeChat),当特征user_installed_app=QQ,和特征impression_app=WeChat取值都为1的时候,组合特征AND(user_installed_app=QQ, impression_app=WeChat)的取值才为1,否则为0。
对于wide部分训练时候使用的优化器是带 L 1 L_1 L1正则的FTRL算法(Follow-the-regularized-leader),而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。**Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。**例如Google W&D期望wide部分发现这样的规则:用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。
-
Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
a ( l + 1 ) = f ( W l a ( l ) + b l ) a^{(l+1)} = f(W^{l}a^{(l)} + b^{l}) a(l+1)=f(Wla(l)+bl)
**我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。**对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
Wide部分与Deep部分的结合
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是 Adagrad。
P ( Y = 1 ∣ x ) = δ ( w w i d e T [ x , ϕ ( x ) ] + w d e e p T a ( l f ) + b ) P(Y=1|x)=\delta(w_{wide}^T[x,\phi(x)] + w_{deep}^T a^{(lf)} + b) P(Y=1∣x)=δ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)
3. Code
Wide侧记住的是历史数据中那些常见、高频的模式,是推荐系统中的“红海”。实际上,Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧
Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的深层交叉,以增强扩展能力。
模型的实现与模型结构类似由deep和wide两部分组成,这两部分结构所需要的特征在上面已经说过了,针对当前数据集实现,我们在wide部分加入了所有可能的一阶特征,包括数值特征和类别特征的onehot都加进去了,其实也可以加入一些与wide&deep原论文中类似交叉特征。只要能够发现高频、常见模式的特征都可以放在wide侧,对于Deep部分,在本数据中放入了数值特征和类别特征的embedding特征,实际应用也需要根据需求进行选择。
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
def WideNDeep(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layer = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layer)
return model
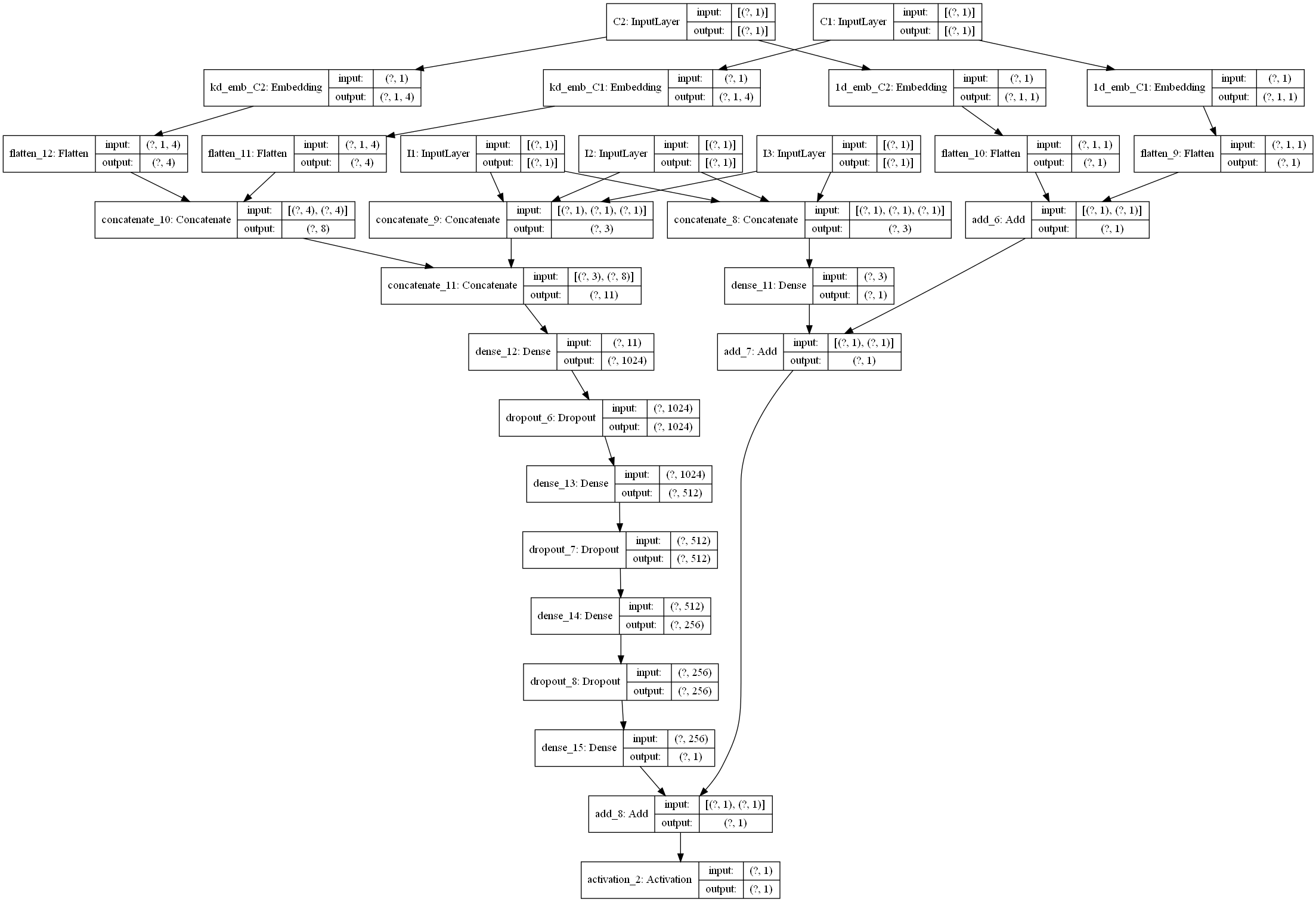
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
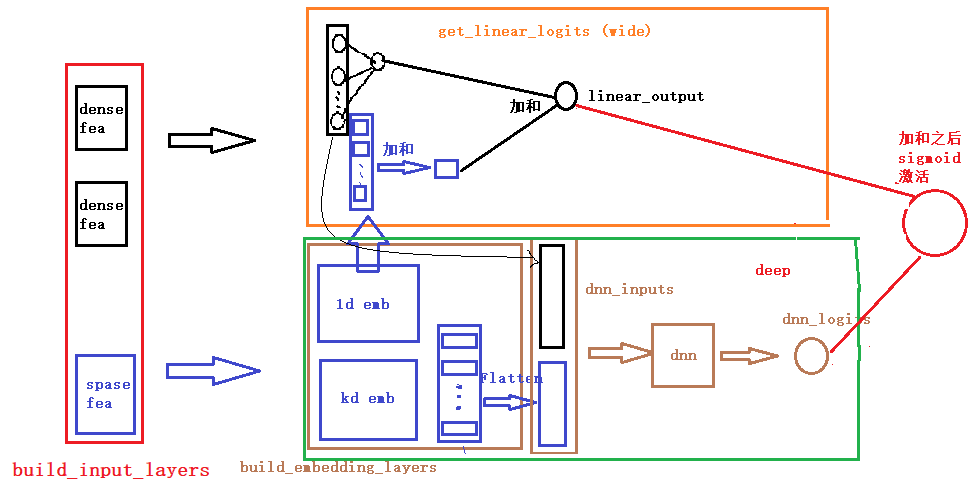
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。