wide & deep
相信这是个对有关推荐系统工作者非常眼熟的一个模型,是16年谷歌应用于google play中的模型,在推荐系统中工业界的应用也非常广泛,是一个比较成熟的模型,近日实习所在组上线这个模型,点击率相比于LR得到了极大的提高,借此机会学习总结一下这个模型。
个人觉得推荐非常重要的就是构建用户画像,还原用户行为,基于此分析用户兴趣爱好,然后对其推荐,用户行为特征显得尤为重要,然而如何去搭建用户画像的这个模型是我们面临的难题,相比于图像数据的不同,广告数据具有极大的稀疏性,因此对于CNN中比较有用的dropout拿到广告推荐中来可能就直接gg了。对于用户的一些数据,例如用户所在城市,性别,或者是否点击这些信息我们经常都是通过one-hot进行处理,最后得到大量稀疏特征丢入LR模型中,LR模型虽然快,但学习粒度非常粗糙,无法学习到扩展性特征,考虑到embedding做法时下如此流行,便衍生出了许多的方法。
Wide&Deep全文围绕着“记忆”(Memorization)与“扩展(Generalization)”两个词展开。实际上,它们在推荐系统中有两个更响亮的名字,Exploitation & Exploration,即著名的EE问题。分为wide和deep两个部分,其实就是LR和DNN的组合
- wide侧就是普通的LR模型,需要根据人工经验构建常用特征喂入模型中,让wide侧记住这些信息
- deep侧就是DNN,主要用来对category特征进行embedding处理,将稀疏矩阵映射为稠密矩阵,让DNN学习特征的深度交叉,易于扩展

1. Wide模型
wide模型就是一个广义线性模型,其形式为
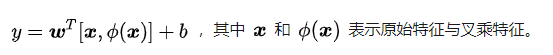
特征包括了原始特征和转换特征,其中最重要的转换方式之一是特征交叉积转换,他被定义为
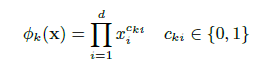
比如说性别和语言的交叉乘积特征AND为1,只有当性别为female和语言为'en'时,其余情况都为0,这种做法捕获了交互特征,在模型中添加了非线性特征
2. Deep模型
该部分是前馈神经网络,网络会对于一些稀疏的类别特征通过最小化损失函数映射为O(10)-O(100)维度的dense layer
![]()
其中L是layer层数,f为激活函数,
3. 联合训练(Joint Trainning)
论文中刻意提醒了ensemble和 joint trainning的区别,ensemble是模型单独训练,在训练过程中二者彼此独立,仅在预测阶段对于每个模型预测的数据进行融合。而joint trainning是同事考虑wide和deep两个模型的权重,一起优化,平时在参加一些数据挖掘类的比赛是,我们可能常用ensemble,这样的方式对资源要求比较高,因为要考虑到单个模型的效果具佳,必然涉及到更加庞大的特征,但在工业界上来说,考虑到训练时间以及训练资源等因素,joint trainning这样的方式将更加高效。
最终模型的预测公式如下
![]()
google play的流程图如下

