论文地址:https://arxiv.org/pdf/1606.07792.pdf
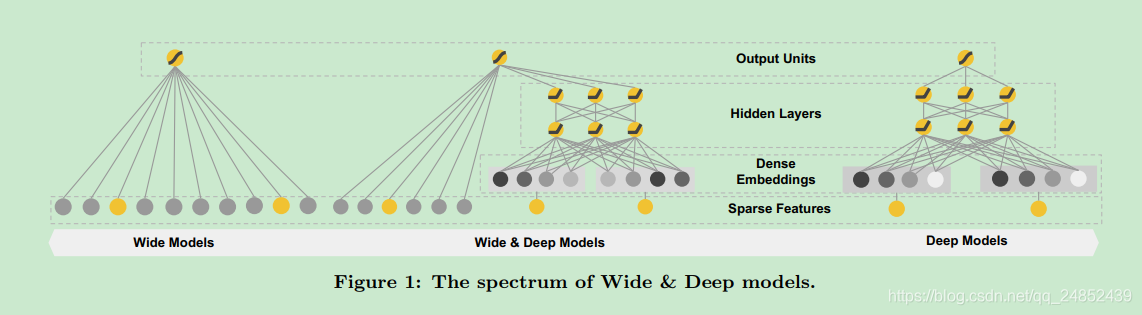
Wide Component
wide部分是一个广义线性模型,如图一左边所示,形如
其中y是预测值,x是d维的特征向量,w是模型参数。而特征又包括了输入特征和变换特征,最重要的转换特征之一是叉积变换,其定义如下:
其中
取值为0或1,为0表示第i个特征属于第k个变换
Deep Component
Deep部分是一个前馈神经网络,如图一右边所示。对应类别特征,原始的输入是特征字符,这些稀疏的高维类别特征首先被转化为低维真值向量,通常被称为嵌入向量,维度通常为O(10)到O(100),嵌入向量随机初始化。这些低维嵌入向量然后被喂入神经网络的隐层,隐层如下:
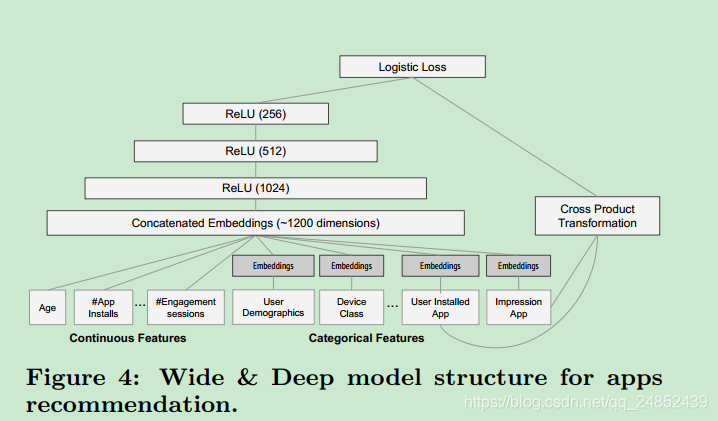
Deep&Wide模型
使用输出日志加权和作为预测,然后喂入logistic损失函数做联合训练。
注意本模型用的是联合训练而不是集成,两者区别如下:
在集成中,单个模型分开训练互不干扰,只有在最后将结果结合,而不是在训练中。同时,每个独立模型的size较大,从而能得到合适的精度。
相反,联合训练同时优化所有的参数,在训练过程中考虑wide和deep网络的权重优化。在联合训练中wide值需要少量的叉积特征转换来弥补deep的不足。
模型目标函数为:
其中Y是二分类label,
是sigmoid函数,
是wide模型的权重,
应用在激活函数
上的权重。
实现代码
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Example code for TensorFlow Wide & Deep Tutorial using TF.Learn API."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
import tempfile
from six.moves import urllib
import pandas as pd
import tensorflow as tf
COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"]
LABEL_COLUMN = "label"
CATEGORICAL_COLUMNS = ["workclass", "education", "marital_status", "occupation",
"relationship", "race", "gender", "native_country"]
CONTINUOUS_COLUMNS = ["age", "education_num", "capital_gain", "capital_loss",
"hours_per_week"]
def maybe_download(train_data, test_data):
"""Maybe downloads training data and returns train and test file names."""
if train_data:
train_file_name = train_data
else:
train_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.data", train_file.name) # pylint: disable=line-too-long
train_file_name = train_file.name
train_file.close()
print("Training data is downloaded to %s" % train_file_name)
if test_data:
test_file_name = test_data
else:
test_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.test", test_file.name) # pylint: disable=line-too-long
test_file_name = test_file.name
test_file.close()
print("Test data is downloaded to %s" % test_file_name)
return train_file_name, test_file_name
def build_estimator(model_dir, model_type):
"""Build an estimator."""
# Sparse base columns.
gender = tf.contrib.layers.sparse_column_with_keys(column_name="gender",
keys=["female", "male"])
education = tf.contrib.layers.sparse_column_with_hash_bucket(
"education", hash_bucket_size=1000)
relationship = tf.contrib.layers.sparse_column_with_hash_bucket(
"relationship", hash_bucket_size=100)
workclass = tf.contrib.layers.sparse_column_with_hash_bucket(
"workclass", hash_bucket_size=100)
occupation = tf.contrib.layers.sparse_column_with_hash_bucket(
"occupation", hash_bucket_size=1000)
native_country = tf.contrib.layers.sparse_column_with_hash_bucket(
"native_country", hash_bucket_size=1000)
# Continuous base columns.
age = tf.contrib.layers.real_valued_column("age")
education_num = tf.contrib.layers.real_valued_column("education_num")
capital_gain = tf.contrib.layers.real_valued_column("capital_gain")
capital_loss = tf.contrib.layers.real_valued_column("capital_loss")
hours_per_week = tf.contrib.layers.real_valued_column("hours_per_week")
# Transformations.
age_buckets = tf.contrib.layers.bucketized_column(age,
boundaries=[
18, 25, 30, 35, 40, 45,
50, 55, 60, 65
])
# Wide columns and deep columns.
wide_columns = [gender, native_country, education, occupation, workclass,
relationship, age_buckets,
tf.contrib.layers.crossed_column([education, occupation],
hash_bucket_size=int(1e4)),
tf.contrib.layers.crossed_column(
[age_buckets, education, occupation],
hash_bucket_size=int(1e6)),
tf.contrib.layers.crossed_column([native_country, occupation],
hash_bucket_size=int(1e4))]
deep_columns = [
tf.contrib.layers.embedding_column(workclass, dimension=8),
tf.contrib.layers.embedding_column(education, dimension=8),
tf.contrib.layers.embedding_column(gender, dimension=8),
tf.contrib.layers.embedding_column(relationship, dimension=8),
tf.contrib.layers.embedding_column(native_country,
dimension=8),
tf.contrib.layers.embedding_column(occupation, dimension=8),
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
]
# 模型定义
if model_type == "wide":
m = tf.contrib.learn.LinearClassifier(model_dir=model_dir,
feature_columns=wide_columns)
elif model_type == "deep":
m = tf.contrib.learn.DNNClassifier(model_dir=model_dir,
feature_columns=deep_columns,
hidden_units=[100, 50])
else:
m = tf.contrib.learn.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
return m
def input_fn(df):
"""Input builder function."""
# Creates a dictionary mapping from each continuous feature column name (k) to
# the values of that column stored in a constant Tensor.
continuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}
# Creates a dictionary mapping from each categorical feature column name (k)
# to the values of that column stored in a tf.SparseTensor.
categorical_cols = {
k: tf.SparseTensor(
indices=[[i, 0] for i in range(df[k].size)],
values=df[k].values,
dense_shape=[df[k].size, 1])
for k in CATEGORICAL_COLUMNS}
'''
categorical_cols = {
k: tf.SparseTensor(
indices=[[i, 0] for i in range(df[k].size)],
values=df[k].values,
shape=[df[k].size, 1])
for k in CATEGORICAL_COLUMNS}
'''
# Merges the two dictionaries into one.
feature_cols = dict(continuous_cols)
feature_cols.update(categorical_cols)
# Converts the label column into a constant Tensor.
label = tf.constant(df[LABEL_COLUMN].values)
# Returns the feature columns and the label.
return feature_cols, label
def train_and_eval(model_dir, model_type, train_steps, train_data, test_data):
"""Train and evaluate the model."""
train_file_name, test_file_name = maybe_download(train_data, test_data)
df_train = pd.read_csv(
tf.gfile.Open(train_file_name),
names=COLUMNS,
skipinitialspace=True,
engine="python")
df_test = pd.read_csv(
tf.gfile.Open(test_file_name),
names=COLUMNS,
skipinitialspace=True,
skiprows=1,
engine="python")
# remove NaN elements
df_train = df_train.dropna(how='any', axis=0)
df_test = df_test.dropna(how='any', axis=0)
df_train[LABEL_COLUMN] = (
df_train["income_bracket"].apply(lambda x: ">50K" in x)).astype(int)
df_test[LABEL_COLUMN] = (
df_test["income_bracket"].apply(lambda x: ">50K" in x)).astype(int)
model_dir = tempfile.mkdtemp() if not model_dir else model_dir
print("model directory = %s" % model_dir)
m = build_estimator(model_dir, model_type)
m.fit(input_fn=lambda: input_fn(df_train), steps=train_steps)
results = m.evaluate(input_fn=lambda: input_fn(df_test), steps=1)
for key in sorted(results):
print("%s: %s" % (key, results[key]))
print("Train WDL End")
FLAGS = None
def main(_):
print(FLAGS)
train_and_eval(FLAGS.model_dir, FLAGS.model_type, FLAGS.train_steps,
FLAGS.train_data, FLAGS.test_data)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
parser.add_argument(
"--model_dir",
type=str,
default="./wdl_data/model_save",
help="Base directory for output models."
)
parser.add_argument(
"--model_type",
type=str,
default="wide_n_deep",
help="Valid model types: {'wide', 'deep', 'wide_n_deep'}."
)
parser.add_argument(
"--train_steps",
type=int,
default=2000,
help="Number of training steps."
)
parser.add_argument(
"--train_data",
type=str,
default="./wdl_data/adult.data",
help="Path to the training data."
)
parser.add_argument(
"--test_data",
type=str,
default="./wdl_data/adult.test",
help="Path to the test data."
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
