网上有不少介绍这个的,我再自己整理一遍以加强理解,便于以后查阅。
Pytorch已经成为超越Tensorflow,成为当前最流行的深度学习框架。我觉得作为一个深度学习框架,最重要的就是两大块,一个是对GPU的便捷操作,第二个是对反向传播的自动实现,pytorch都做的非常不错。pytorch的autograd模块实现反向传播式的自动求导
1,链式求导法则和反向传播
深度神经网络可以看成一个多层嵌套的复合函数,例如卷积层、ReLU层等每层都是一个函数,复合函数求导使用经典的链式求导法则,就是
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du}\cdot \frac{du}{dx} dxdy=dudy⋅dxdu
其中 d u du du是中间层,可以有多个。对于多元函数,例如深度学习中每层,这时把求导变成求偏导即可,此时的导数也改名叫做梯度。
这个公式其实也很好理解,因为导数的含义就是输出随输入的变化率,多个串联的输入输出的变化率乘起来就等于最后输出关于最初输入的变化率。当然复合函数也不仅是只有一个输入一个输出的这种串联结构,还可以有多个输入一个输出的形式(不能一个输入多个输出,那就不叫函数了)。如果把复合函数理解为数据经过各个节点进行不断加工处理的一个网络的话,就会好理解的多,引用知乎上的一张图片:箭头是反向传播的过程,正向过程沿箭头反方向。
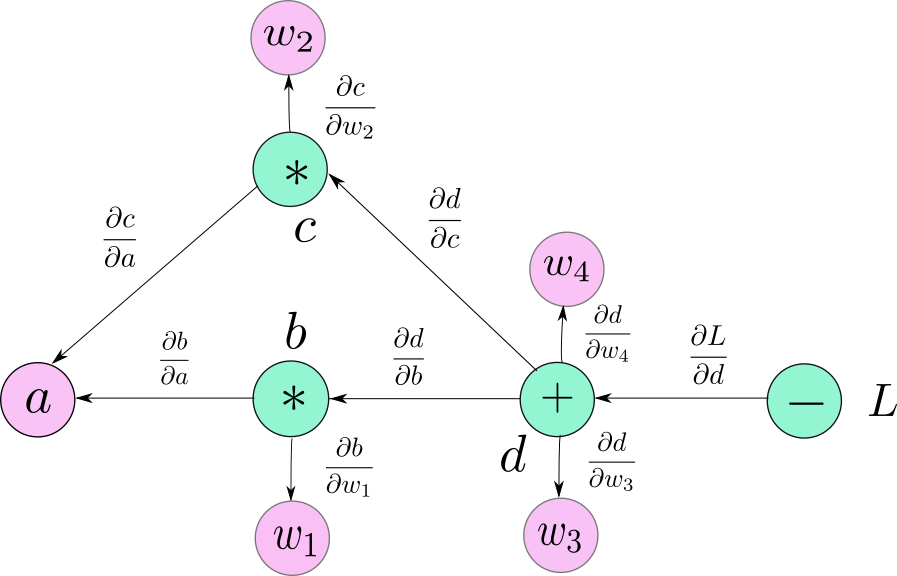
反向传播的目的是为了求得最终输出关于输入的梯度,我们把它化解为各层函数的梯度的组合形式,每层函数的梯度的方程式都是固定和事先知道的,但是每层函数的输入输出值仍需要正向传播计算一遍才能都知道,而导数的计算时又是相反的过程,每层的梯度求解依赖于后层的梯度数值和本层的求导公式。
注意,深度神经网络中,输入和各层的参数都是叶子节点。叶子节点的梯度不参与反向传播主过程,所以叶子节点可以不求导,不影响其他节点的求导。当然,叶子节点的梯度反而正是我们需要的,所以我们需要从反向传播的主节点中再导出各叶子节点的梯度。
2,requires_grad
经过上面的梳理,我们再结合pytorch具体代码来理解。由于叶子节点的梯度并不是反向传播过程必须的,所以就可以根据使用者的需求来设置是否求它们的梯度。对于非叶子节点,因为它们的梯度是必须的,所以不能设置为requires_grad=False
3,retain_grad
对于非叶子节点,虽然它们的梯度必须求,但通常它们只是中间过程,Pytorch为了节省内存(显存)占用,默认为用完即删,不做保存。如果我们需要它,可以给需要的非叶子节点的变量设置为retain_grad=True,这样它的梯度就会保存下来。
4, retain_graph
pytorch使用动态图机制,也就是说每次正向传播到输出节点的时候(输出节点通常就是loss值),在loss处保存了产生它的所有前序节点的关系(用一个有向无环图表示),这个关系用来指导反向传播时的路径,但是这个关系只用一次就删除了,这样就允许下一次正向传播时使用不一样的路径,这种方式就是动态图机制,它更加的灵活。但是有时候也许我们一次反向传播之后还不想正向传播,还需要再加入一些新的计算后再反向传播一次,(比如我们使用多个损失函数相加,可以每个损失函数反向传播一次后再计算下一个损失函数再反向传播,这样节省显存),这个时候必须保留前面反向传播的计算图,就需要设置loss.backward(retain_graph=True)。注意最后一次没必要再保留,这样可以降低一些显存。
5,inplace操作
注意某个张量在被其他函数使用之后就不能再使用inplace操作来修改值了,因为这样反向传播计算梯度的时候需要用到的原来那个数值就找不到了。如果需要修改,可以使用非inplace操作。inplace操作有: +=1,切片赋值[0]=1等。
6, 不能微分的函数
如果计算过程中有不能微分的函数,反向传播就会出问题。
常见的有argmax(),sign()等,会报错。
对于round(),ceil(),floor(),这几个虽然不会报错,但会导致梯度变成0,失去意义,也不要使用。
对于abs(), relu等似乎数学上不严格可微,存在个别不可微点的,pytorch进行了特殊处理,反而是可以使用的。
7, detach()
x1 = x.detach()用来在当前计算图中分离x,新的x1和x共享相同的存储空间,但新的x1不需要梯度。
最后放一段简单的代码,可以用来试验刚才提到的各种功能。还可以试验optimizer,它的用法下次再总结。
import torch
x1 = torch.tensor([[1.,2.],[2.,3.],[1.,1.]],requires_grad=True)
w1 = torch.tensor([[1.,2.,3.],[3.,2.,1.]],requires_grad=True)
for epoch in range(1):
y1 = torch.mm(w1,x1)
y1.retain_grad()
w2 = torch.tensor([[1.,3.],[2.,1.]])
y2 = torch.mm(w2,y1)
#w1 += 1
y = y2.view(-1).max()
optimizer = torch.optim.SGD([x1,w1],lr=0.001 )
optimizer.zero_grad()
y.backward(retain_graph=True)
y3 = y**2
y3.backward()
optimizer.step()
print(epoch,y)
print('w1:',w1,'\n','w1.grad:',w1.grad)
print('w2:',w2,'\n','w2.grad:',w2.grad)
print('x1:',x1,'\n','x1.grad:',x1.grad)