从接口的角度来讲,对tensor的操作可分为两类:
torch.function,如torch.save等。- 另一类是
tensor.function,如tensor.view等。
为方便使用,对tensor的大部分操作同时支持这两类接口,在此不做具体区分,如torch.sum (torch.sum(a, b))与tensor.sum (a.sum(b))功能等价。
而从存储的角度来讲,对tensor的操作又可分为两类:
- 不会修改自身的数据,如
a.add(b), 加法的结果会返回一个新的tensor。 - 会修改自身的数据,如
a.add_(b), 加法的结果仍存储在a中,a被修改了。
函数名以_结尾的都是inplace方式, 即会修改调用者自己的数据,在实际应用中需加以区分。
tensor.numel() # tensor中元素总个数和, 等价于tensor.nelement() tesor.size() == tensor.shape # 需要注意的是,t.Tensor(*sizes)创建tensor时,系统不会马上分配空间,只是会计算剩余的内存是否足够使用,使用到tensor时才会分配,而其它操作都是在创建完tensor之后马上进行空间分配。其它常用的创建tensor的方法举例如下。
常用Tensor操作
通过tensor.view方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,返回的新tensor与源tensor共享内存,也即更改其中的一个,另外一个也会跟着改变。在实际应用中可能经常需要添加或减少某一维度,这时候squeeze和unsqueeze两个函数就派上用场了。
resize是另一种可用来调整size的方法,但与view不同,它可以修改tensor的大小。如果新大小超过了原大小,会自动分配新的内存空间,而如果新大小小于原大小,则之前的数据依旧会被保存,看一个例子。
Tensor支持与numpy.ndarray类似的索引操作,语法上也类似,下面通过一些例子,讲解常用的索引操作。如无特殊说明,索引出来的结果与原tensor共享内存,也即修改一个,另一个会跟着修改。
PyTorch在0.2版本中完善了索引操作,目前已经支持绝大多数numpy的高级索引1。高级索引可以看成是普通索引操作的扩展,但是高级索引操作的结果一般不和原始的Tensor共享内存。
Tensor有不同的数据类型,如表3-3所示,每种类型分别对应有CPU和GPU版本(HalfTensor除外)。默认的tensor是FloatTensor,可通过t.set_default_tensor_type 来修改默认tensor类型(如果默认类型为GPU tensor,则所有操作都将在GPU上进行)。Tensor的类型对分析内存占用很有帮助。例如对于一个size为(1000, 1000, 1000)的FloatTensor,它有1000*1000*1000=10^9个元素,每个元素占32bit/8 = 4Byte内存,所以共占大约4GB内存/显存。HalfTensor是专门为GPU版本设计的,同样的元素个数,显存占用只有FloatTensor的一半,所以可以极大缓解GPU显存不足的问题,但由于HalfTensor所能表示的数值大小和精度有限1,所以可能出现溢出等问题。
逐元素操作
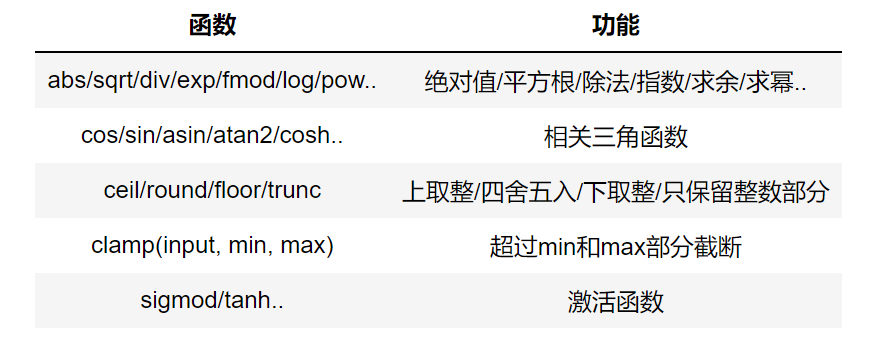
这部分操作会对tensor的每一个元素(point-wise,又名element-wise)进行操作,此类操作的输入与输出形状一致。常用的操作如表3-4所示
归并操作
此类操作会使输出形状小于输入形状,并可以沿着某一维度进行指定操作。如加法sum,既可以计算整个tensor的和,也可以计算tensor中每一行或每一列的和。常用的归并操作如表3-5所示。

以上大多数函数都有一个参数dim,用来指定这些操作是在哪个维度上执行的。关于dim(对应于Numpy中的axis)的解释众说纷纭,这里提供一个简单的记忆方式:
假设输入的形状是(m, n, k)
- 如果指定dim=0,输出的形状就是(1, n, k)或者(n, k)
- 如果指定dim=1,输出的形状就是(m, 1, k)或者(m, k)
- 如果指定dim=2,输出的形状就是(m, n, 1)或者(m, n)
size中是否有"1",取决于参数keepdim,keepdim=True会保留维度1。注意,以上只是经验总结,并非所有函数都符合这种形状变化方式,如cumsum。
比较
比较函数中有一些是逐元素比较,操作类似于逐元素操作,还有一些则类似于归并操作。常用比较函数如表3-6所示。

表中第一行的比较操作已经实现了运算符重载,因此可以使用a>=b、a>b、a!=b、a==b,其返回结果是一个ByteTensor,可用来选取元素。max/min这两个操作比较特殊,以max来说,它有以下三种使用情况:
- t.max(tensor):返回tensor中最大的一个数
- t.max(tensor,dim):指定维上最大的数,返回tensor和下标
- t.max(tensor1, tensor2): 比较两个tensor相比较大的元素
至于比较一个tensor和一个数,可以使用clamp函数。
线性代数
PyTorch的线性函数主要封装了Blas和Lapack,其用法和接口都与之类似。常用的线性代数函数如表3-7所示。

具体使用说明请参见官方文档1,需要注意的是,矩阵的转置会导致存储空间不连续,需调用它的.contiguous方法将其转为连续。
注意: 不论输入的类型是什么,t.tensor都会进行数据拷贝,不会共享内存
tensor内部结构
tensor分为头信息区(Tensor)和存储区(Storage),信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存成连续数组。由于数据动辄成千上万,因此信息区元素占用内存较少,主要内存占用则取决于tensor中元素的数目,也即存储区的大小。一般来说一个tensor有着与之相对应的storage, storage是在data之上封装的接口,便于使用,而不同tensor的头信息一般不同,但却可能使用相同的数据。下面看两个例子。
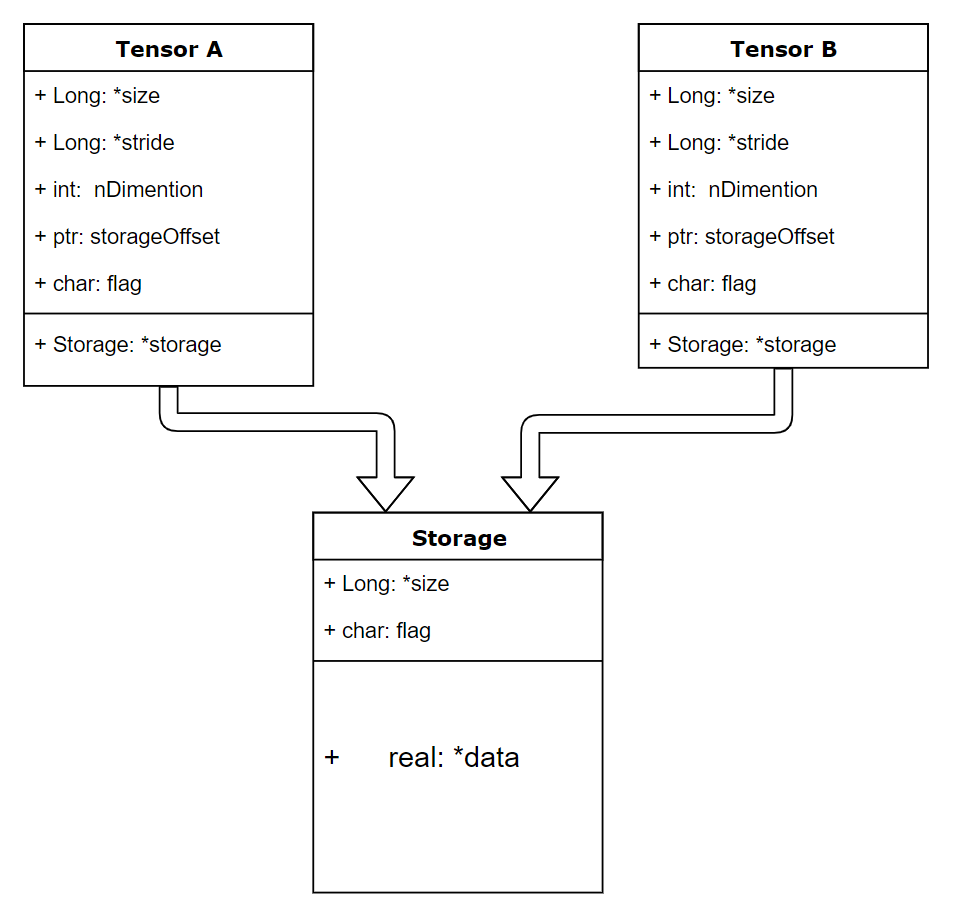
可见绝大多数操作并不修改tensor的数据,而只是修改了tensor的头信息。这种做法更节省内存,同时提升了处理速度。在使用中需要注意。 此外有些操作会导致tensor不连续,这时需调用tensor.contiguous方法将它们变成连续的数据,该方法会使数据复制一份,不再与原来的数据共享storage。 另外读者可以思考一下,之前说过的高级索引一般不共享stroage,而普通索引共享storage,这是为什么?(提示:普通索引可以通过只修改tensor的offset,stride和size,而不修改storage来实现)。
- 尽量使用
tensor.to(device), 将device设为一个可配置的参数,这样可以很轻松的使程序同时兼容GPU和CPU - 数据在GPU之中传输的速度要远快于内存(CPU)到显存(GPU), 所以尽量避免频繁的在内存和显存中传输数据。
在平时写代码时,就应养成向量化的思维习惯,千万避免对较大的tensor进行逐元素遍历。
此外还有以下几点需要注意:
- 大多数
t.function都有一个参数out,这时候产生的结果将保存在out指定tensor之中。 t.set_num_threads可以设置PyTorch进行CPU多线程并行计算时候所占用的线程数,这个可以用来限制PyTorch所占用的CPU数目。t.set_printoptions可以用来设置打印tensor时的数值精度和格式。 下面举例说明。