autograd包中是PyTorch中所有神经网络的核心,为Tensors上所有操作自动求导,由框架定义运行,意味着backprop由代码运行的方式定义,并且每个迭代都可以不同。
Tensor
torch.Tensor是所有package的核心类,当设置.requires_grad为True时,会追踪所有操作。完成计算后,可以调用.backward()并自动计算梯度。该张量的梯度会累积到.grad属性中。
要阻止张量跟踪历史记录,可以调用.detach()将其从计算历史记录中分离出来,并防止将来的计算被跟踪。
要防止跟踪历史记录(和使用内存),您还可以使用torch.no_grad()包装代码块: 在评估模型时这可能特别有用,因为模型可能具有requires_grad = True的可训练参数,但不需要梯度。
Function类对autograd的实现非常重要
Tensor和Function相互连接构成一个非循环图,编码完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用一个创建张量的函数(除了用户创建的张量——它们的grad_fn=None)。
如果想计算导数(derivatives),可以在Tensor上调用.backward()。如果该Tensor是一个标量,不需要为.backward()指定任何参数;如果Tensor有多个元素,需要指定一个梯度参数,是一个形状匹配的张量。
创建一个张量并且设置requires_grad=True追踪计算
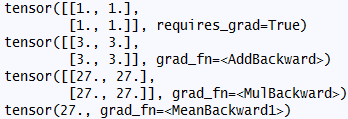
x = torch.ones(2, 2, requires_grad=True)
print(x)
y = x + 2
print(y)
z = y * y * 3
out = z.mean()
print(z)
print(out)
输出为
.requires_grad_(...)改变已有张量的requires_grad的标签。默认的标签为False。
a = torch.randn(2, 2)
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
输出为

Gradients
当out为一个标量时,out.backward()等价于out.backward(torch.tensor(1.))
求梯度d(out)/dx
print(x.grad)
输出为
