
PyTorch | 自动求导 Autograd
\qquad 在神经网络中,一个重要的内容就是进行参数学习,而参数学习离不开求导,那么 P y T o r c h PyTorch PyTorch 是如何进行求导的呢?
\qquad 现在大部分深度学习架构都有自动求导的功能, P y T o r c h PyTorch PyTorch 也不例外, P y T o r c h PyTorch PyTorch 中所有神经网络的核心是
autograd包,它就是用来自动求导的。
autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(
define-by-run)的框架,这意味着反向传播(
神经网络前向传播 & 反向传播)是根据你的代码来确定如何运行,并且每次迭代可以是不同的。
\qquad
torch.Tensor是
autograd包的核心类,在自动梯度计算中还有另外一个重要的类
torch.Function,这两个类相互连接并生成一个
有向非循环图,它表示和存储了完整的计算历史。接下来我们先简单介绍
t e n s o r tensor tensor 如何实现自动求导,然后介绍计算图,最后用代码来实现这些功能。
一、自动求导要点
\qquad 无论如何定义计算过程、如何定义计算图,要谨记我们的核心目的是为了计算某些 t e n s o r tensor tensor 的梯度。在 p y t o r c h pytorch pytorch 的计算图中,其实只有两种元素:数据( t e n s o r tensor tensor)和运算,运算就是加减乘除、开方、幂指对、三角函数等可求导运算,而 t e n s o r tensor tensor 可细分为两类:叶子节点(Leaf Node)和非叶子节点。使用 backward() 函数反向传播计算 t e n s o r tensor tensor 的梯度时,并不计算所有 t e n s o r tensor tensor 的梯度,而是只计算满足这几个条件的 t e n s o r tensor tensor 的梯度:
\qquad\qquad (1)类型为叶子节点
\qquad\qquad (2)requires_grad=True
\qquad\qquad (3)依赖该 t e n s o r tensor tensor 的所有 t e n s o r tensor tensor 的 r e q u i r e s _ g r a d = T r u e requires\_grad=True requires_grad=True
为 实 现 对 T e n s o r 自 动 求 导 , 需 要 考 虑 以 下 事 项 : 为实现对Tensor自动求导,需要考虑以下事项: 为实现对Tensor自动求导,需要考虑以下事项:
-
创建叶子节点(
Leaf Node)的 t e n s o r tensor tensor,使用requires_grad参数指定是否记录对其的操作,requires_grad参数的缺省值为 F a l s e False False。如果设置requires_grad参数为 T r u e True True,那么将会追踪所有对于该张量的操作。 当完成计算后通过调用backward()方法自动计算所有的梯度, 这个张量的所有梯度将会自动积累到grad属性。 -
可以使用
tensor.requires_grad_()方法修改 t e n s o r tensor tensor 的requires_grad属性。要阻止张量跟踪历史记录,可以调用tensor.detach()方法将其与计算历史记录分离,并禁止跟踪它将来的计算记录。为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型、测试模型阶段中特别有用,因为模型中可能具有requires_grad = True的可训练参数,但是我们不需要梯度计算。 -
通过运算创建的 t e n s o r tensor tensor(即非叶子节点)会自动被赋予
grad_fn属性,该属性引用了创建 t e n s o r tensor tensor 自身的 F u n c t i o n Function Function(用户手动创建的 t e n s o r tensor tensor 的grad_fn是 N o n e None None,即叶子节点的grad_fn为 N o n e None None) -
最后得到的 t e n s o r tensor tensor 执行
backward()函数,此时自动计算各变量的梯度,并将累加结果保存到grad属性中。计算完成后,非叶子节点的梯度自动释放。 -
backward()函数:torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
\qquad 参数 t e n s o r s tensors tensors 如果是标量,函数 b a c k w a r d backward backward 计算参数 t e n s o r s tensors tensors 对于给定计算图叶子节点的梯度。
\qquad 参数 t e n s o r s tensors tensors 如果不是标量,需要另外指定参数 g r a d _ t e n s o r s grad\_tensors grad_tensors,参数 g r a d _ t e n s o r s grad\_tensors grad_tensors 必须和参数 t e n s o r s tensors tensors 的长度相同,或者满足 广播机制 。在这一种情况下, b a c k w a r d backward backward 实际上实现的是代价函数关于计算图叶子节点的梯度计算,而不是参数 t e n s o r s tensors tensors 对于给定计算图叶子节点的梯度。 -
反向传播的中间缓存会被清空,如果需要进行多次反向传播,需要指定
backward()函数中的参数retain_graph=True。多次反向传播时,梯度是累加的。 -
非叶子节点的梯度
backward调用后即被清空。 -
可以通过用
torch.no_grad()包裹代码块的形式来阻止autograd去跟踪那些标记为.requesgrad=True的张量的历史记录。这一步在测试阶段经常使用。
\qquad 在整个过程中, P y T o r c h PyTorch PyTorch 采用计算图的形式进行组织,该计算图为动态图,且在每次前向传播时,将重新构建。
二、计算图
\qquad 计算图是一种有向无环图像(Directed Acyclic Graph,DAG),用图形方式来表示算子与变量之间的关系,直观高效。如下图所示,圆形表示变量,矩阵表示算子。如表达式: z = w x + b z=wx+b z=wx+b,可以写成两个表达式: y = w x y=wx y=wx,则 z = y + b z=y+b z=y+b,其中 w 、 x 、 b w、x、b w、x、b 是变量,是用户创建的变量,不依赖于其他变量,故又称为叶子节点。为计算各叶子节点的梯度,需要把对应的张量参数requires_grad设置为 T r u e True True,这样就可以自动跟踪其历史记录。 y 、 z y、z y、z 是计算得到的变量,非叶子节点,z为根节点。 m u l mul mul 和 a d d add add 是算子(或操作或函数)。由这些变量及算子,就构成一个完整的计算过程(或前向传播过程)。
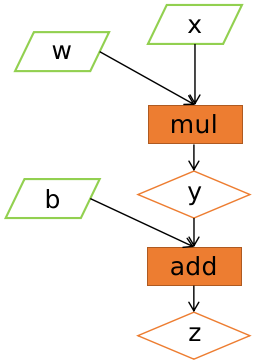
前 向 传 播 计 算 图 前向传播计算图 前向传播计算图
\qquad 我们的目标是更新各叶子节点的梯度,根据复合函数倒数的链式法则,不难算出各叶子节点的梯度:
∂ z ∂ x = ∂ z ∂ y ∂ y ∂ x = w ∂ z ∂ w = ∂ z ∂ y ∂ y ∂ w = x ∂ z ∂ b = 1 \displaystyle \frac{\partial z}{\partial x}=\frac{\partial z}{\partial y}\frac{\partial y}{\partial x}=w\\\displaystyle \frac{\partial z}{\partial w}=\frac{\partial z}{\partial y}\frac{\partial y}{\partial w}=x\\\displaystyle \frac{\partial z}{\partial b}=1 ∂x∂z=∂y∂z∂x∂y=w∂w∂z=∂y∂z∂w∂y=x∂b∂z=1
P y T o r c h \qquad PyTorch PyTorch 调用 backward() 方法,将自动计算各节点的梯度,这是一个反向传播过程,这个过程可用下图表示。且在反向传播过程中,autograd沿着下图,从当前根节点 z z z 反向溯源,利用导数链式法则,计算所有叶子节点的梯度,其梯度值将累加到grad属性中。对非叶子节点的计算操作(或Function)记录在grad_fn属性中,叶子节点的grad_fn值为None。

反 向 传 播 计 算 图 反向传播计算图 反向传播计算图
三、标量反向传播
\qquad 假设 x 、 w 、 b x、w、b x、w、b 都是标量, z = w x + b z=wx+b z=wx+b,对标量 z z z 调用 backward() 方法,我们无须对 backward() 传入参数。
注 : 只 有 浮 点 型 数 据 才 能 计 算 梯 度 , 其 他 类 型 数 据 是 不 能 计 算 张 量 梯 度 的 。 \qquad 注:只有浮点型数据才能计算梯度,其他类型数据是不能计算张量梯度的。 注:只有浮点型数据才能计算梯度,其他类型数据是不能计算张量梯度的。
\qquad 以下是实现自动求导的代码:
import torch
# 1. 定义叶子节点及算子节点
# 定义输入张量x
x = torch.Tensor([2])
# 初始化权重参数w,偏移量b,并设置requires_grad属性为True,为自动求导
w = torch.randn(1,requires_grad=True)
b = torch.randn(1,requires_grad=True)
# 实现前向传播
y = torch.mul(w,x) # 等价于w*x
# retain_grad()显式地保存非叶节点的梯度
y.retain_grad()
z = torch.add(y,b) # 等价于y+b
# retain_grad()显式地保存非叶节点的梯度
z.retain_grad()
# 查看x,w,b叶子节点的requires_grad属性
print("x,w,b 的 requires_grad 属性分别为:{},{},{}".format(x.requires_grad,w.requires_grad,b.requires_grad))
# 2. 查看叶子节点、非叶子节点的属性
# 查看非叶子节点的requires_grad属性
# 因与w,b有依赖关系,故y,z的requires_grad属性也是:True,True
print("y,z 的 requires_grad 属性分别为:{},{}".format(y.requires_grad,z.requires_grad))
# 查看各节点是否为叶子节点
# x,w,b,y,z 是否为叶子节点:True,True,True,False,False
print("x,w,b,y,z 是否为叶子节点:{},{},{},{},{}".format(x.is_leaf,w.is_leaf,b.is_leaf,y.is_leaf,z.is_leaf))
# 查看叶子节点的grad_fn属性
# 因为x,w,b都为用户所创建,故x,w,b的grad_fn属性:None,None,None
print("x,w,b 的 grad_fn 属性:{},{},{}".format(x.grad_fn,w.grad_fn,b.grad_fn))
# 查看非叶子节点的grad_fn属性
print("y,z 的 grad_fn 属性:{},{}".format(y.grad_fn,z.grad_fn))
# 3. 自动求导,实现梯度方向传播,即梯度的反向传播
# 基于z张量进行梯度反向传播,执行backward之后计算图会自动清空
# 如果需要多次使用backward,需要修改参数retain_graph为True,此时梯度是累加的
# z.backward(retain_graph=True)
z.backward()
# 查看叶子节点的梯度,x是叶子节点但它无须求导,故其梯度为None
print("叶子节点x,w,b的梯度分别为:{},{},{}".format(x.grad,w.grad,b.grad))
# 非叶子节点的梯度,执行backward之后,会自动清空
print("非叶子节点y,z的梯度分别为:{},{}".format(y.grad,z.grad))
四、非标量反向传播
P y T o r c h \qquad PyTorch PyTorch 有个简单的规定,不让张量(Tensor)对张量求导,只允许标量对张量求导,因此,如果目标张量对一个非标量调用backward(),则需要传入一个gradient参数,该参数也是张量,而且需要与调用backward()的张量形状相同。
\qquad 传入gradient参数是为了把张量对张量的求导转换为标量对张量的求导。举例来说,假设目标值为 l o s s ⃗ = ( y 1 , y 2 , ⋯ , y m ) \pmb{\vec{loss}}=(y_1,y_2,\ \cdots,y_m) losslossloss=(y1,y2, ⋯,ym),输入值为 x ⃗ = ( x 1 , x 2 , ⋯ , x n ) \pmb{\vec{x}}=(x_1,x_2,\ \cdots,x_n) xxx=(x1,x2, ⋯,xn),传入的gradient参数为 v ⃗ = ( v 1 , v 2 , ⋯ , v m ) \pmb{\vec{v}}=(v_1,v_2,\ \cdots,v_m) vvv=(v1,v2, ⋯,vm),那么就可以把张量 l o s s ⃗ T \pmb{\vec{loss}}^T losslosslossT 对张量 x ⃗ \pmb{\vec{x}} xxx 的求导,转换为标量 v ⃗ ⋅ l o s s ⃗ T \pmb{\vec{v}}\cdot\pmb{\vec{loss}}^T vvv⋅losslosslossT 对张量 x ⃗ \pmb{\vec{x}} xxx 的求导。即把张量 v ⃗ \pmb{\vec{v}} vvv(维度为 1 × m 1\times m 1×m)乘以原来 ∂ l o s s ⃗ T ∂ x ⃗ \displaystyle\frac{\partial\pmb{\vec{loss}^T}}{\partial\pmb{\vec{x}}} ∂xxx∂lossTlossTlossT 得到的雅可比(Jacobian)矩阵(维度为 m × n m\times n m×n),便可以得到一个梯度矩阵(维度为 1 × n 1\times n 1×n)。
\qquad 下面通过一个实例进行说明。
1. 定义叶子节点及算子节点
import torch
# 定义叶子节点张量x,形状为1x2
x = torch.tensor([[2,3]],dtype=torch.float,requires_grad=True)
# 初始化 Jacobian 矩阵
J = torch.zeros(2, 2)
# 初始化目标张量,形状为1x2
y = torch.zeros(1, 2)
# 定义y与x之间的映射关系,y1=x1**2+3*x2,y2=x2**2+2*x1
y[0,0] = x[0,0] ** 2 + 3 * x[0,1]
y[0,1] = x[0,1] ** 2 + 3 * x[0,0]
2. 手工计算 y 对 x 的梯度
\qquad 我们先手工计算一下 y y y 对 x x x 的梯度,验证 P y T o r c h PyTorch PyTorch 的 b a c k w a r d backward backward 的结果是否正确。
y \qquad y y 对 x x x 的梯度是一个雅可比矩阵,我们可以通过以下方法进行计算各项的值。
\qquad 假设 x = ( x 1 = 2 , x 2 = 3 ) x=(x_1=2,x_2=3) x=(x1=2,x2=3), y = ( y 1 = x 1 2 + 3 x 2 , y 2 = x 2 2 + 2 x 1 ) y=(y_1=x_1^2+3x_2,y_2=x_2^2+2x_1) y=(y1=x12+3x2,y2=x22+2x1),不难得到:
J = [ ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 ∂ y 2 ∂ x 1 ∂ y 2 ∂ x 2 ] = [ 2 x 1 3 2 2 x 2 ] = [ 4 3 2 6 ] J=\left[\begin{matrix} \displaystyle\frac{\partial y_1}{\partial x_1} & \displaystyle\frac{\partial y_1}{\partial x_2}\\ \quad \\ \displaystyle\frac{\partial y_2}{\partial x_1} & \displaystyle\frac{\partial y_2}{\partial x_2}\end{matrix}\right]=\left[\begin{matrix} 2x_1 & 3\\ 2 & 2x_2\end{matrix}\right]=\left[\begin{matrix} 4 & 3\\ 2 & 6\end{matrix}\right] J=⎣⎢⎢⎢⎡∂x1∂y1∂x1∂y2∂x2∂y1∂x2∂y2⎦⎥⎥⎥⎤=[2x1232x2]=[4236]
3. 调用 backward 来获取 y 对 x 的梯度
y.backward(torch.Tensor([[1,1]]))
print(x.grad) # 结果为 tensor([[6., 9.]])
\qquad 这个结果与我们手工运算的不符,虽然这个结果是错误的,那错在哪里呢?这个结果的计算过程是:
v T ⃗ ⋅ J = [ 1 1 ] [ 4 3 2 6 ] = [ 6 9 ] \pmb{\vec{v^T}}\cdot J=\left[\begin{matrix} 1 & 1\end{matrix}\right]\left[\begin{matrix} 4 & 3\\ 2 & 6\end{matrix}\right]=\left[\begin{matrix} 6 & 9\end{matrix}\right] vTvTvT⋅J=[11][4236]=[69]
\qquad 由此可见,错在 v ⃗ \pmb{\vec{v}} vvv 的取值,通过这种方式得到的并不是 y y y 对 x x x 的梯度。这里我们可以分成两步计算。首先,让 v ⃗ = ( 1 , 0 ) \pmb{\vec{v}}=(1,0) vvv=(1,0) 得到 y 1 y_1 y1 对 x ⃗ \pmb{\vec{x}} xxx 的梯度;然后,使 v ⃗ = ( 0 , 1 ) \pmb{\vec{v}}=(0,1) vvv=(0,1) 得到 y 2 y_2 y2 对 x ⃗ \pmb{\vec{x}} xxx 的梯度。这里因需要重复使用backward(),需要使参数retain_graph=True,具体代码如下:
# 生成y1对x的梯度
y.backward(torch.Tensor([[1,0]]),retain_graph=True)
J[0]=x.grad
# 梯度是累加的,故需要对x的梯度清零
x.grad=torch.zeros_like(x.grad)
# 生成y2对x的梯度
y.backward(torch.Tensor([[0,1]]))
J[1]=x.grad
# 显示Jacobian矩阵的值
# tensor([[4., 3.],
# [2., 6.]])
print(J)