autograd是Pytorch的重要部分,vector-Jacobian product更是其中重点
以三维向量值函数为例:
按Tensor, Element-Wise机制运算,但实际上表示的是:
Y 对 X 的导数不是 2X 而是一个 Jacobian 矩阵(因为 X,Y 是向量,不是一维实数):
其中,它是关于
的函数,而不仅仅只是关于 x1 ,这儿的特殊性是由Element-Wise运算机制引起的, 同理y2,y3
而d(Y)对每一个分量 ![]() 的导数(变化率)是, 各个分量函数
的导数(变化率)是, 各个分量函数![]() ,y=1,2,3对
,y=1,2,3对![]() 的偏导数
的偏导数
沿某一方向 v 的累积, 一般的, v 的默认方向是 ![]() 。
。
也可以传入不同的方向进去,就是官方文档声称的可easy feed external gradient。
这儿,可以将其理解为:关于 ![]() 的偏导数向量在 v 方向上的投影;
的偏导数向量在 v 方向上的投影;
也可以将其理解为:各个分量函数关于 ![]() 偏导的权重。
偏导的权重。
v 一旦确定,关于每个 ![]() 的权重就都确定了,而且是一样的。
的权重就都确定了,而且是一样的。
实验一下:
一 ---简单的隐式Jacobian
>>> x = torch.randn(3, requires_grad = True)
>>> x
tensor([-0.9238, 0.4353, -1.3626], requires_grad=True)
>>> y = x**2
>>> y.backward(torch.ones(3))
>>> x.grad
tensor([-1.8476, 0.8706, -2.7252])
>>> x
tensor([-0.9238, 0.4353, -1.3626], requires_grad=True)
>>>二 ---简单的显示Jacobian验证
>>> x1=torch.tensor(1, requires_grad=True, dtype = torch.float)
>>> x2=torch.tensor(2, requires_grad=True, dtype = torch.float)
>>> x3=torch.tensor(3, requires_grad=True, dtype = torch.float)
>>> y=torch.randn(3) # produce a random vector for vector function define
>>> y[0]=x1**2+2*x2+x3 # define each vector function
>>> y[1]=x1+x2**3+x3**2
>>> y[2]=2*x1+x2**2+x3**3
>>> y.backward(torch.ones(3))
>>> x1.grad
tensor(5.)
>>> x2.grad
tensor(18.)
>>> x3.grad
tensor(34.)上面代码中Jacobian 矩阵为:
各分量函数为分别为:
投影方向:
代码结果与分析相互印证
三---投影到不同的方向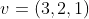
先分析:
再代码验证:
>>> x1=torch.tensor(1, requires_grad=True, dtype = torch.float)
>>> x2=torch.tensor(2, requires_grad=True, dtype = torch.float)
>>> x3=torch.tensor(3, requires_grad=True, dtype = torch.float)
>>> y=torch.randn(3)
>>> y[0]=x1**2+2*x2+x3
>>> y[1]=x1+x2**3+x3**2
>>> y[2]=2*x1+x2**2+x3**3
>>> v=torch.tensor([3,2,1],dtype=torch.float)
>>> y.backward(v)
>>> x1.grad
tensor(10.)
>>> x2.grad
tensor(34.)
>>> x3.grad
tensor(42.)完全符合
