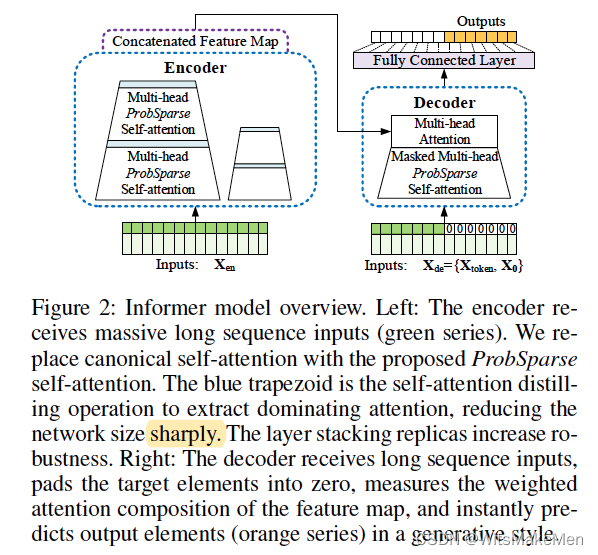
背景
Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(Llog L) in time complexity and memory usage, and has comparable performance on sequences’ dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.
self-attention对长序列进行编码存在三个主要的问题:
- 时间复杂度高,为O(n2)
- 空间复杂度高,计算占用内存大,为O(n2)
- 序列动态串行预测效率慢,step-by-step的方式,计算效率非常慢。
主要工作
Efficient Self-attention Mechanism
主要工作框架基于transformer self-attention框架,对于每个q来说,计算的是q对每个k的一个概率分布,然后用这个概率分布去乘以v,算出对v的概率期望。
前人的一些研究成果表明,self-attention的期望分布存在固有的稀疏性,也就是大部分的query计算出来的概率p(k/q)都是没有用的。
所以前人通过一些启发式的做法,来进行self-attention的加速,但是存在一些固有问题。


怎么评估一个q相对来说是稀疏的呢?这就要用的KL散度了,用KL散度计算P(k|q)和uniform distribution是否相同,如果算出来的KL值非常小,说明q的概率和uniform distribution概率分布差不多,说明q没有什么区分度,这个q就没有什么意义,采样的时候需要去掉。


基于上面提出的计算q重要度的方法,继续稀疏性评估矩阵M,我们只需要采样TOP-u的query就可以。


Encoder: Allowing for Processing Longer Sequential Inputs under the Memory Usage Limitation
编码器采用了self-attention蒸馏的方式,使用了卷积和池化的思想。

Decoder: Generating Long Sequential Outputs Through One Forward Procedure
传统的序列生成的问题是动态生成的,按照step-by-step的方式一个个下一个字符,但是新的方法采用占位符一次性生成的方式,避免了串行执行,生成速度会快很多。
