
本期将继续介绍一篇利用大语言模型进行时间序列预测任务的工作。文章下载地址为https://arxiv.org/pdf/2308.08469.pdf 。
1. 前期提要
大家都知道预训练大型语言模型(LLMs)具有强大的表示学习能力和少样本学习,但要利用LLM处理时间序列,需要解决两个关键问题:
1) 如何将时间序列数据输入LLMs: 为了将时间序列输入到LLM,需要对齐进行tokenize,近期的研究工作(Zhang等人,2023年)强调通过‘’patching‘’的方式对时间序列、图像、音频等各类数据进行torkenize都是非常有效的。PatchTST方法(这个后期博文会进行介绍)基于通道独立性的思想将多变量时间序列数据视为多个单变量时间序列,将单个序列划分成不同的patch。而一些基于transformer的时间序列预测相关的工作强调了整合时间信息可以增强模型的预测性能,因此本篇文章一种新方法,使用patch和通道独立思想的同时对时序信息进行整合。
2) 如何在不破坏LLM固有特性的情况下对其进行微调使其能够适配时间序列任务: 构建像InstructGPT和ChatGPT这些对话系统时,通常利用有监督微调将模型与基于指令的数据进行对其,使得大模型熟悉数据的格式和特性。基于此,本篇文章提出了一种两阶段微调方法,首先通过监督微调将模型与时间序列的特性进行对其,引导LLM适应时间序列,接下来以下游预测任务为导向进一步对模型进行微调,从而保障不破坏语言模型固有特性的基础上使得模型能够更好地适配配各类不同域的数据( Cross-Modality Knowledge Transfer)及不同的下游任务(In-Modality Knowledge Transfer)。
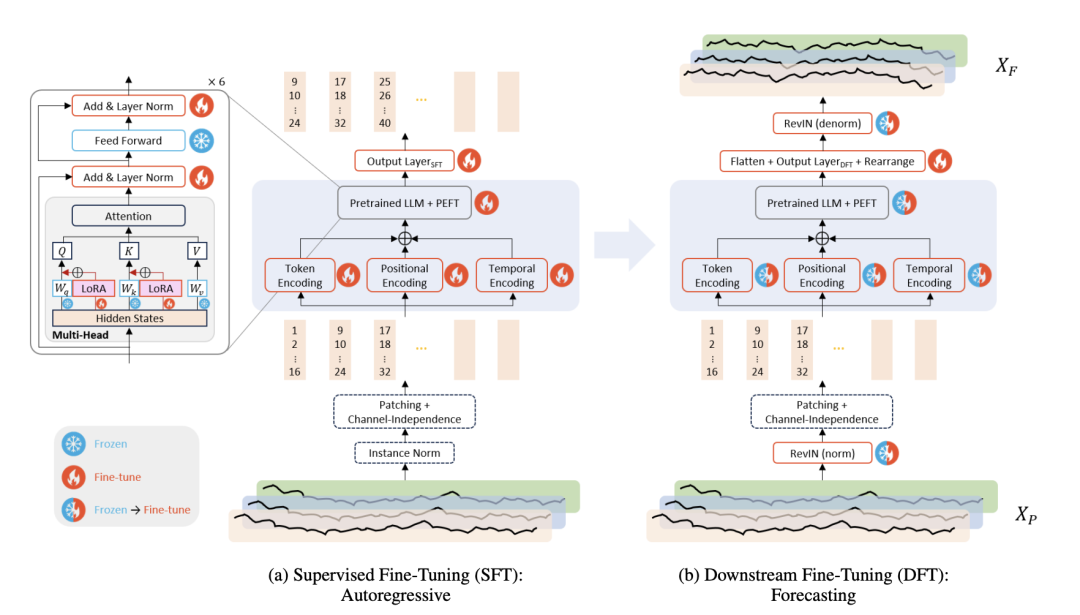
2. 方法介绍
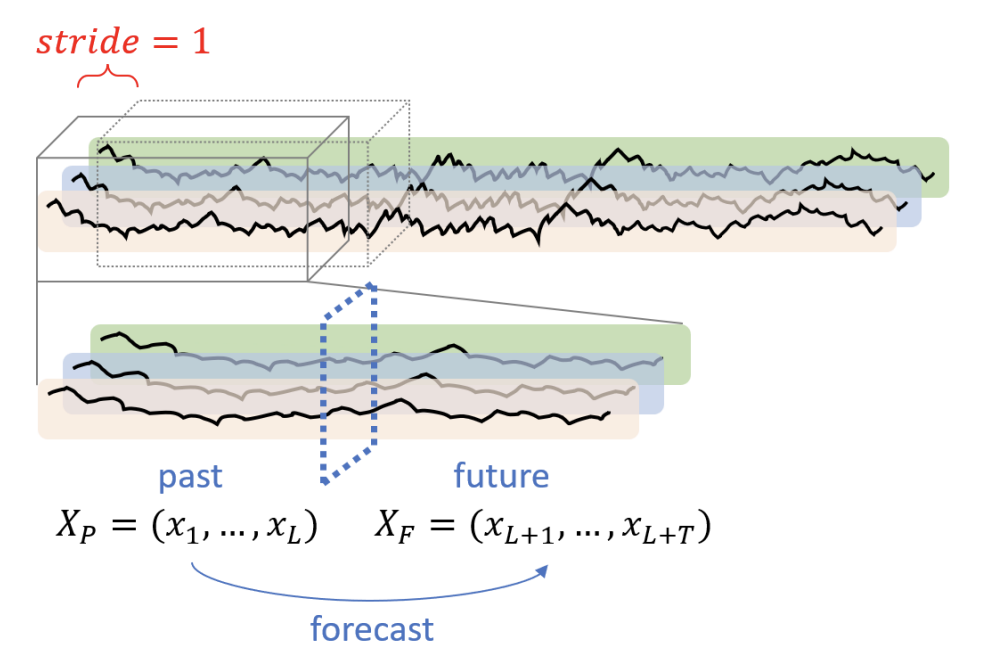
给定完整且均匀采样的多变量时间序列,利用长度为的窗口以步长1进行移动,将数据分成不同的窗口数据,其中每个窗口中数据可进一步分为历史数据窗口和未来数据窗口。对于每个时间步t, 代表一个M维向量。此方法的目标是利用过去数据来预测未来数据,以GPT-2为backbone,下面具体此方法的训练和微调步骤
Instance Normalization: 这里作者采用了标准的instance noramlization,即在对于每个窗口内序列的各个序列,根据其均值和标准差进行z-score标准化。
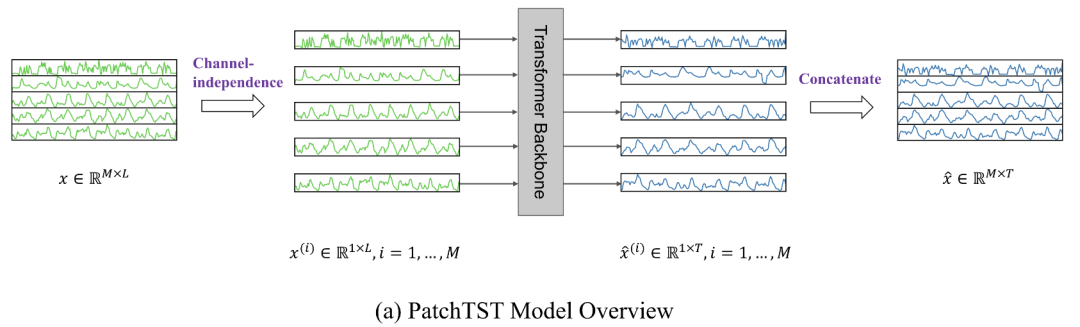
Patching and Channel-Independence: 接下来,采用patchTST相同的思想,首先将多变量序列视作多个单个变量序列(即认为通道间相互独立)由单个模型进行处理。相比于通道混合的方式来提取通道间的相关性,patchTST通过不同序列共享模型参数的方式来捕捉通道间的关联,能够避免过拟合。然后,将每个序列分成指定长度的多个patch作为llm的基础分析单元token,这些patch可以是相互重叠的,也可以为不重叠的,具体可根据数据输入长度调整。patching的操作,在增大输入数据历史时间跨度的同时并不会增加输入token的长度,能够有效提升效率。
Three Encodings: 获得上述的基础token后,有必要进一步对其进行编码,使其变成LLM能够兼容的形式,文中采用的是一维卷积层,位置编码采用的是与NLP模型中的标准形式(关于时间序列位置编码下次会专门出一篇博文来进行介绍)。相比于NLP模型,获取时间序列数据token时通常面临两个挑战:1)每个分段涵盖多个时间戳,2)每个时间戳都带有各种时间属性,如分钟、小时、星期几、日期和月份。对于第一个问题,文章将时间戳引入token中,针对于第二个问题,借鉴NLP中构建token方式,论文为分钟/小时/日期/月份等时间相关属性构建了可训练和查找的embedding,并将各个属性的embedding相加作为最终的temporal embedding,保存patch内的时间相关信息。最终,每个patch对应的最终token由三部分组成:经过一位卷积层的token+position embedding+temporal embedding。
Pre-Trained LLM and PEFT: 论文使用了GPT-2作为backbone。为了保留模型的基本知识,论文冻结了大部分参数,特别是Transformer模块内的多头注意力和前馈层所涉及的参数。论文融合了两种参数高效微调技术(PEFT),层归一化调整( Layer Normalization Tuning )和 LoRA(LowRank Adaptation)来提高模型面对未知数据的泛化性能和灵活性。对于可训练的部分参数,论文采用了两阶段微调的方式。1)Supervised Fine-tuning: Autoregressive 首先第一阶段以自回归形式进行有监督微调,来使得模型适配时序数据,这是因为GPT-2是一个因果语言模型(这里的因果是指以自回归的形式,仅利用历史数据进行预测,并不会采用未来的数据)。这样既保留了语言模型本身的知识,又使模型能够适应时间序列数据。在这个阶段模型输出为patch形式,这里可以利用一个线性层来改变输出的维度。2)Downstream Fine-tuning: Forecasting 接下来,针对下游预测任务进行微调,文章在前部分迭代中采用线性微调策略(仅调整最后的线性输出层),而在后一阶段的迭代中采用完全微调的策略(调整所有可训练参数)。这个阶段的模型输出也位patch形式,可以将其展平后再输入线性层获取指定维度。
3. 实验效果
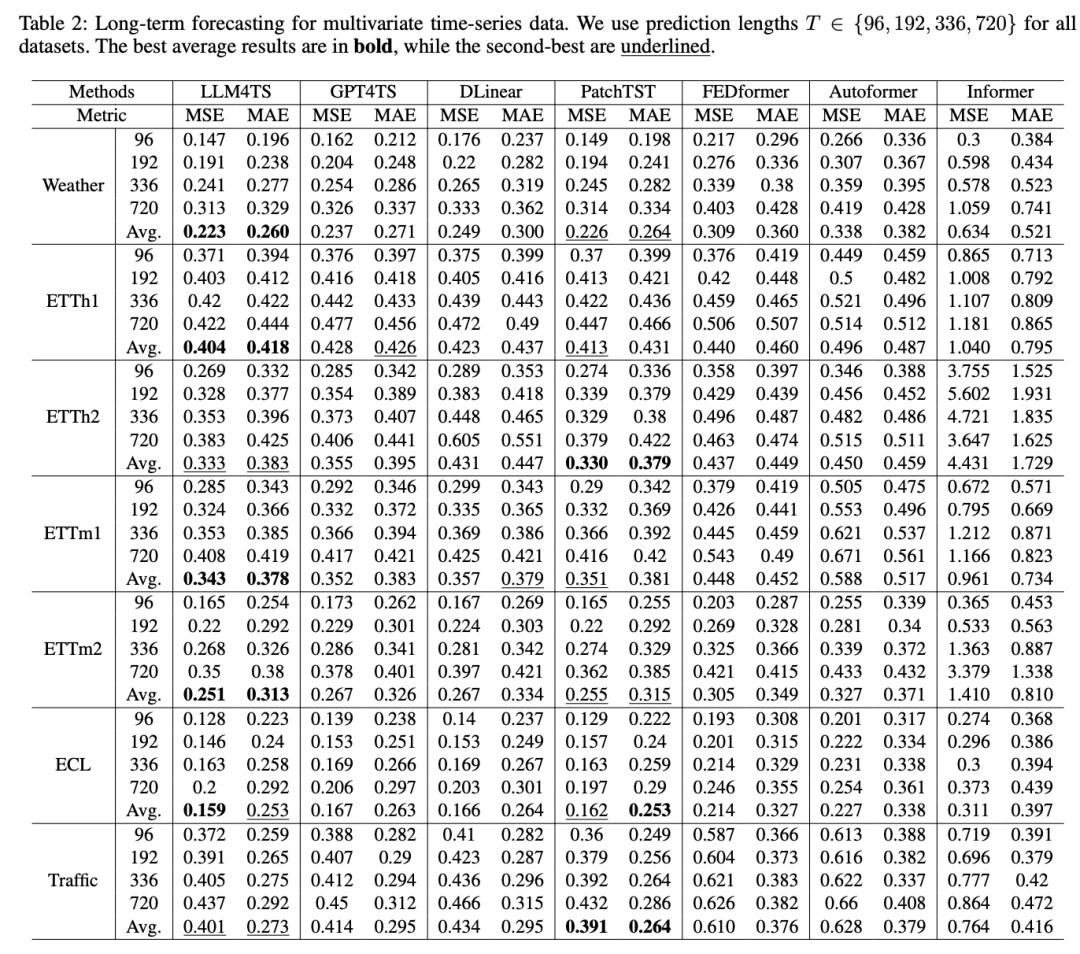
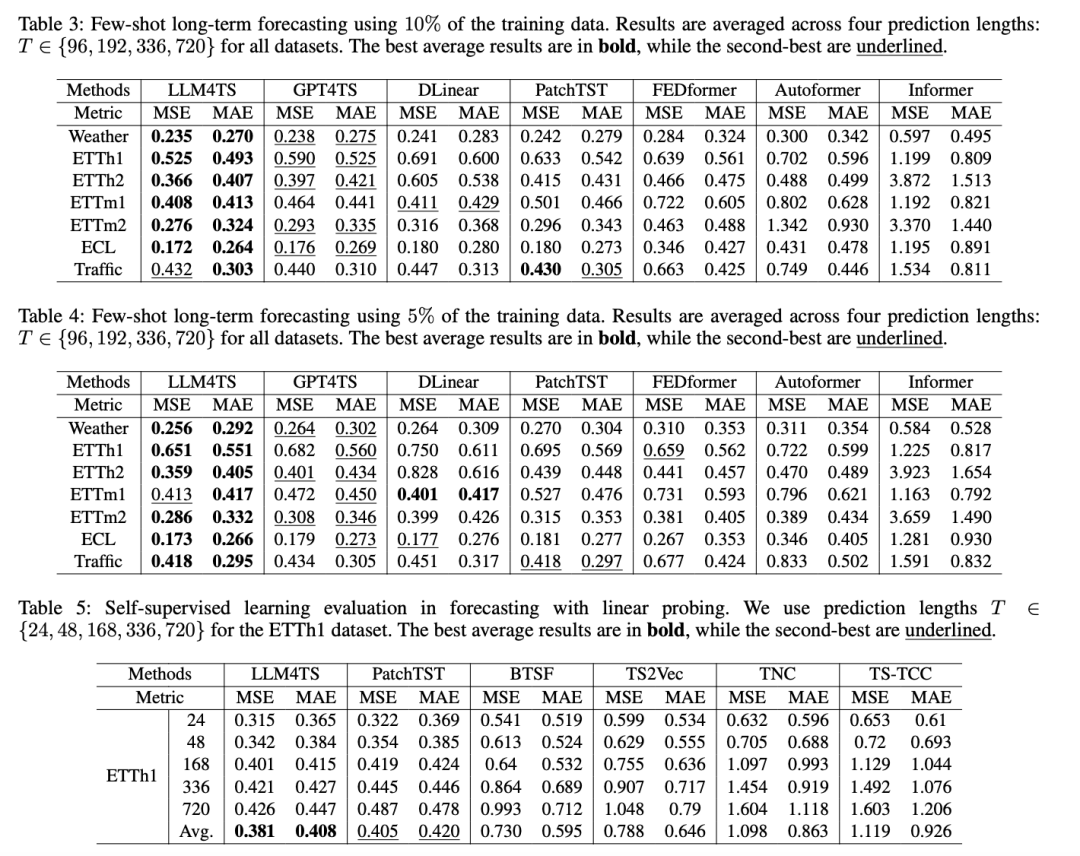
论文主要利用了如下五个数据集来比较所提方法与现有sota算法在长序列预测和少样本预测任务上的性能,具体参数设置细节大家可以去看论文,目前好像并未找到论文代码。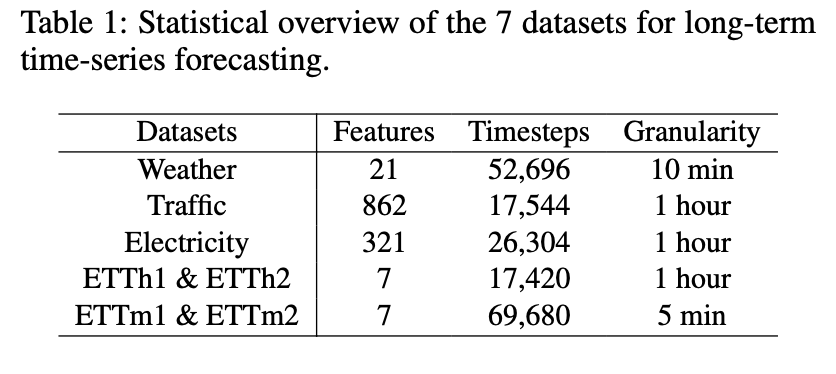
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书