摘要
许多实际应用需要对长时间序列进行预测,例如耗电量计划。长时间序列预测(LSTF)需要模型的高预测能力,这要求具有能有效捕获输出和输入之间精确的长期依赖关系的能力。最近的研究表明,Transformer具有提高预测能力的潜力。但是,Transformer存在一些严重问题,导致其无法直接应用于LSTF,例如二次时间复杂度,高内存使用率以及编码器-解码器体系结构的固有局限性。为了解决这些问题,我们为LSTF设计了一个有效的基于Transformer的模型,称为Informer,它具有三个独有的特征:(i)ProbSparse自注意力机制,该机制在时间复杂度和内存使用上达到 O ( L l o g L ) O(L~log~L) O(L log L),并且具有在序列依赖性方面具有可比的性能。(ii)自注意力蒸馏通过将级联层输入减半而突出了注意力,并有效地处理了极长的输入序列。(iii)生成样式解码器虽然在概念上很简单,但它会以一种前向操作而不是循序渐进的方式预测较长的时间序列,从而大大提高了较长序列预测的推理速度。在四个大型数据集上进行的大量实验表明,Informer的性能明显优于现有方法,并为LSTF问题提供了新的解决方案。
1.介绍
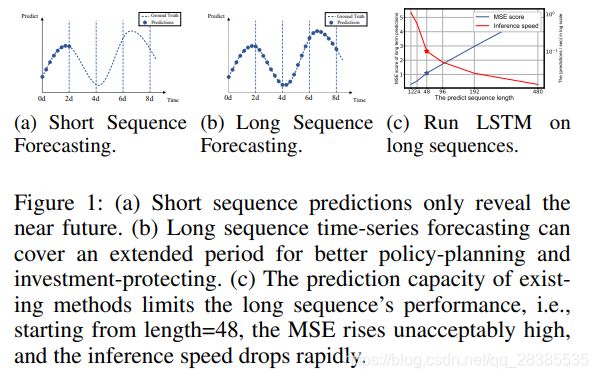
时间序列预测在许多领域中扮演者重要角色,例如传感器网络监控,能源和智能电网管理,经济和金融以及疾病传播分析。在这些情况下,我们可以利用大量有关过去行为的时间序列数据来进行长期预测,即长时间序列预测(LSTF)。但是,现有方法是在一个有约束的设置下设计的,例如预测未来48个或更少的点。越来越长的序列使模型的预测能力受到挑战,有人认为这种趋势限制了LSTF研究的程度。作为一个经验示例,图(1)显示了在真实数据集上的预测结果,其中LSTM网络预测了从短期(12点,0.5天)到长期(480点,20天)的变电站的每小时温度。当预测长度大于48个点时,总体性能差距很大(图1(c)中的星号),MSE得分上升到不令人满意的性能,推理速度急剧下降,这表明LSTM模型时很糟糕的。
LSTF的主要挑战是增强预测能力以满足日益增长的长序列需求,这要求(a)很强的远距离对齐能力和(b)对长序列输入和输出的高效操作。最近,与RNN模型相比,Transformer模型在捕获远程依赖方面显示出优异的性能。自注意力机制可以将网络输入信号传播路径的最大长度减少到理论上最短的 O ( 1 ) O(1) O(1),并避免重复结构,从而使Transformer表现出解决LSTF问题的巨大潜力。但是另一方面,由于自注意力机制的 L L L二次计算和 L L L长度输入/输出的内存消耗,因此违反了(b)的要求。一些大型的Transformer模型会在NLP任务上投入大量资源并产生非常好的结果,但是对数十个GPU的训练和昂贵的部署成本使这些模型在现实世界中的LSTF问题上难以承受。自注意力机制和Transformer框架的效率成为将它们应用于LSTF问题的瓶颈。因此,在本文中,我们试图回答以下问题:可以将Transformer模型提高到计算,内存和体系结构高效,且保持较高的预测能力吗?
Vanilla Transformer在解决LSTF时有三个明显的局限性:
- 自注意力的二次计算。自注意力机制的原子操作,即规范的点积,导致每层时间复杂度和内存使用量为 O ( L 2 ) \mathcal O(L^2) O(L2)。
- 长输入堆叠层中的内存瓶颈。编码器/解码器 J J J层的堆叠使总内存使用量为 O ( J ⋅ L 2 ) \mathcal O(J·L^2) O(J⋅L2),这限制了在接收长序列输入时的模型可伸缩性。
- 预测长输出的速度瓶颈。Vanilla Transformer的动态解码使逐步推理的速度与基于RNN的模型一样慢,如图(1c)所示。
有一些先前的工作可以提高自注意力的效率。Sparse Transformer,LogSparse Transformer和Longformer均使用启发式方法来解决局限1并将自注意力机制的复杂性降低为 O ( L l o g L ) \mathcal O(L~log~L) O(L log L),其效率增益有限。Reformer也通过局部敏感的哈希自注意力来实现 O ( L l o g L ) \mathcal O(L~log~L) O(L log L),但它仅适用于极长的序列。最近,Linformer声称可达到线性复杂度为 O ( L ) \mathcal O(L) O(L),但无法为实际应用中的长序列输入固定项目矩阵,这可能会造成将复杂度降低为 O ( L 2 ) \mathcal O(L^2) O(L2)的风险。Transformer-XL和Compressive Transformer使用辅助隐藏状态来捕获远程依赖关系,这可能会放大限制1并不利于打破效率瓶颈。所有工作主要集中在限制1上,而限制2&3仍然存在于LSTF问题中。为了提高预测能力,我们将解决所有这些问题,并在提出的Informer中实现超出效率的改进。
为此,我们的工作明确地深入研究了上述三个问题。我们研究了自注意力机制中的稀疏性,改进了网络组件,并进行了广泛的实验。本文的贡献总结如下:
- 我们提出Informer成功地增强LSTF问题中的预测能力,从而验证类Transformer的模型的潜在价值,以捕获长时间序列输出和输入之间的各个远程依赖性。
- 我们提出了ProbSparse自注意力机制来有效地替换常规的自注意力,并实现 O ( L l o g L ) \mathcal O(L~log~L) O(L log L)时间复杂度和 O ( L l o g L ) \mathcal O(L~log~L) O(L log L)内存使用。
- 我们提出了自注意力蒸馏操作来控制 J J J个堆叠层中的注意分数,并将总空间复杂度急剧降低为 O ( ( 2 − ϵ ) L l o g L ) \mathcal O((2-\epsilon)L~log~L) O((2−ϵ)L log L)。
- 我们提出使用“生成样式解码器”来获取长序列输出,而只需要一个向前的步骤,同时避免在推理阶段累积误差的扩散。
2.预备知识
我们首先提供问题的定义。在具有固定大小窗口的滑动预测设置下,我们在时刻 t t t的输入是 X t = { x 1 t , . . . , x L x t ∣ x i t ∈ R d x } \mathcal X_t=\{x^t_1,...,x^t_{L_x} | x^t_i∈\mathbb R^{d_x}\} Xt={
x1t,...,xLxt∣xit∈Rdx},输出是预测相应的序列 Y t = { y 1 t , . . . , y L y t ∣ y i t ∈ R d y } \mathcal Y^t=\{y^t_1,...,y^t_{L_y} | y^t_i∈\mathbb R^{d_y}\} Yt={
y1t,...,yLyt∣yit∈Rdy}。LSTF问题鼓励输出的长度 L y L_y Ly比以前的工作更长,并且特征维度不限于单变量情况( d y ≥ 1 d_y≥1 dy≥1)。
(1)编解码器结构
最近设计了许多流行的模型以将输入表示 X t \mathcal X^t Xt编码为隐藏状态表示 H t \mathcal H^t Ht,并根据 H t = { h 1 t , . . . , h L h t } \mathcal H^t=\{h^t_1,...,h^t_{L_h}\} Ht={
h1t,...,hLht}将输出解码为 Y t \mathcal Y^t Yt。推理过程涉及名为“动态解码”的分步过程,其中解码器根据先前状态 h k t h^t_k hkt计算新的隐藏状态 h k + 1 t h^t_{k+1} hk+1t,然后根据第 k k k步的其他必要输出预测出第 ( k + 1 ) (k+1) (k+1)个序列 y k + 1 t y^t_{k+1} yk+1t。
(2)输入表示
给出了统一的输入表示形式,以增强时间序列输入的全局位置上下文和局部时间上下文。为避免繁琐的描述,我们将详细信息放在附录B中。
3.方法
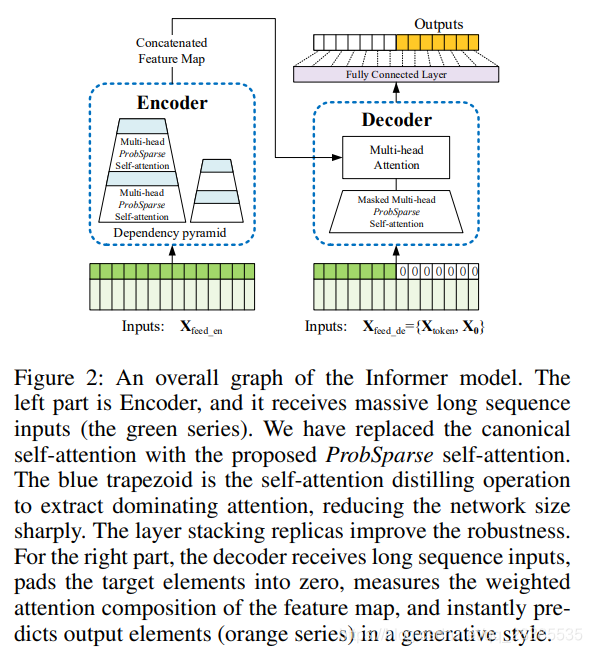
现有的时间序列预测方法可以大致分为两类(详见附录A)。传统时间序列模型是时间序列预测的可靠工具,深度学习技术主要通过使用RNN及其变体来开发编码器-解码器预测框架。我们提出的Informer拥有针对LSTF问题的编码器-解码器体系结构。有关概述,请参见图(2)。有关详细信息,请参见以下各节。
3.1 高效self-attention机制
(Vaswani et al. 2017) 中提出的常规自注意力是在接收元组输入 (query, key, value) 时定义的,并按 A ( Q , K , V ) = S o f t m a x ( Q K T d ) V \mathcal A(\textbf Q,\textbf K,\textbf V)=Softmax(\frac{\textbf Q\textbf K^T}{\sqrt d})\textbf V A(Q,K,V)=Softmax(dQKT)V执行缩放点积,其中 Q ∈ R L Q × d , K ∈ R L K × d , V ∈ R L V × d \textbf Q∈\mathbb R^{L_Q×d},\textbf K∈\mathbb R^{L_K×d},\textbf V∈\mathbb R^{L_V×d} Q∈RLQ×d,K∈RLK×d,V∈RLV×d, d d d为输入维度。为了进一步讨论自注意力机制,令 q i , k i , v i \textbf q_i,\textbf k_i,\textbf v_i qi,ki,vi分别代表 Q , K , V \textbf Q,\textbf K,\textbf V Q,K,V中的第 i i i行。 按照 (Tsai et al. 2019) 中的表述,第 i i i个query的注意力定义为概率形式的核平滑器:
A ( q i , K , V ) = ∑ j k ( q i , k j ) ∑ l k ( q i , k l ) v j = E p ( k j ∣ q i ) [ v j ] , (1) \mathcal A(\textbf q_i,\textbf K,\textbf V)=\sum_j\frac{k(\textbf q_i,\textbf k_j)}{\sum_lk(\textbf q_i,\textbf k_l)}\textbf v_j=\mathbb E_{p(\textbf k_j|\textbf q_i)}[\textbf v_j],\tag{1} A(qi,K,V)=j∑∑lk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj],(1)
其中 p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) p(\textbf k_j |\textbf q_i)=\frac{k(\textbf q_i,\textbf k_j)}{\sum_lk(\textbf q_i,\textbf k_l)} p(kj∣qi)=∑lk(qi,kl)k(qi,kj)和 k ( q i , k j ) k(\textbf q_i,\textbf k_j) k(qi,kj)选择非对称指数核 e x p ( q i k j T d ) exp(\frac{\textbf q_i\textbf k_j^T}{\sqrt d}) exp(dqikjT)。自注意力组合这些值并基于计算概率 p ( k j ∣ q i ) p(\textbf k_j|\textbf q_i) p(kj∣qi)获取输出。它需要二次乘积运算和 O ( L Q L K ) \mathcal O(L_QL_K) O(LQLK)内存使用,这是增强预测能力的主要缺点。
先前的一些尝试表明,自注意力的概率分布具有潜在的稀疏性,并且他们在所有 p ( k j ∣ q i ) p(\textbf k_j|\textbf q_i) p(kj∣qi)上设计了一些“选择性”计数策略,而不会显着影响性能。Sparse Transformer结合了行输出和列输入,其中稀疏来自于分离的空间相关性。LogSparse Transformer注意到自注意力的周期性模式,并以指数步长迫使每个单元格参与到其前一个单元格。Longformer将前两个工作扩展为更复杂的稀疏配置。但是,他们仅限于采用启发式方法进行理论分析,并使用相同的策略来解决每个多头自我注意的问题,从而缩小了其进一步的改进范围。
为了激发我们的方法,我们首先对典型的自注意力的学习注意模式进行定性评估。“稀疏”的自注意力得分形成了长尾分布(有关详细信息,请参见附录C),即,一些点积对引起了极大的注意力分数,而其他对则可以忽略。然后,下一个问题是如何区分它们?
(1)Query Sparsity Measurement
根据等式(1),第 i i i个query对所有keys的注意力定义为概率 p ( k j ∣ q i ) p(\textbf k_j|\textbf q_i) p(kj∣qi),输出是values v \textbf v v的组合。主导点积对鼓励了相应query的注意力分布远离均匀分布。如果 p ( k j ∣ q i ) p(\textbf k_j|\textbf q_i) p(kj∣qi)接近均匀分布 q ( k j ∣ q i ) = 1 L K q(\textbf k_j|\textbf q_i)=\frac{1}{L_K} q(kj∣qi)=LK1,则自注意力变为values V \textbf V V的离散总和,并且对于残差输入是多余的。自然地,分布p和q之间的“相似性”可用于区分“重要的”queries。我们通过Kullback-Leibler散度 K L ( q ∣ ∣ p ) = l n ∑ l = 1 L K e q i k l T / d − 1 L K ∑ j = 1 L K q i k j T / d − l n L K KL(q||p)=ln\sum^{L_K}_{l=1}e^{\textbf q_i\textbf k^T_l/\sqrt d}-\frac{1}{L_K}\sum^{L_K}_{j=1}\textbf q_i\textbf k^T_j/\sqrt d-lnL_K KL(q∣∣p)=ln∑l=1LKeqiklT/d−LK1∑j=1LKqikjT/d−lnLK来测量“相似度”。删除常数后,我们将第i个query的稀疏度定义为:
M ( q i , K ) = l n ∑ l = 1 L K e q i k l T d − 1 L K ∑ j = 1 L K q i k j T d , (2) M(\textbf q_i,\textbf K)=ln\sum^{L_K}_{l=1}e^{\frac{\textbf q_i\textbf k^T_l}{\sqrt d}}-\frac{1}{L_K}\sum^{L_K}_{j=1}\frac{\textbf q_i\textbf k^T_j}{\sqrt d},\tag{2} M(qi,K)=lnl=1∑LKedqiklT−LK1j=1∑LKdqikjT,(2)
其中,第一项是 q i q_i qi在所有keys上的Log-Sum-Exp (LSE) ,第二项是它们上的算术平均值。如果第 i i i个query获得较大的 M ( q i , K ) M(\textbf q_i,\textbf K) M(qi,K),则其注意力概率 p p p更加“多样化”,并且有很大的机会将主导点积对包含在长尾自注意力分布的头字段中 。
(2)ProbSparse Self-attention
根据所提出的度量,通过允许每个key仅参与到前 u u u个主导queries,我们具有了ProbSparse Self-attention:
A ( Q , K , V ) = S o f t m a x ( Q ‾ K T d ) V , (3) \mathcal A(\textbf Q,\textbf K,\textbf V)=Softmax(\frac{\overline{\textbf Q}\textbf K^T}{\sqrt d})\textbf V,\tag{3} A(Q,K,V)=Softmax(dQKT)V,(3)
其中 Q ‾ \overline{\textbf Q} Q是与 q \textbf q q大小相同的稀疏矩阵,并且仅包含稀疏度 M ( q , K ) M(\textbf q,\textbf K) M(q,K)下的Top- u u u queries。在常数采样因子 c c c的控制下,我们设置 u = c ⋅ l n L Q u=c·ln~L_Q u=c⋅ln LQ,这使得ProbSparse自注意力仅需要为每个query-key查找计算 O ( l n L Q ) \mathcal O(ln~L_Q) O(ln LQ)点积,并且每层的内存使用量保持 O ( L K l n L Q ) \mathcal O(L_K~ln~L_Q) O(LK ln LQ)。
但是,遍历所有queries的度量 M ( q i , K ) M(\textbf q_i,\textbf K) M(qi,K)都需要计算每个点乘积对,即平方 O ( L Q L K ) \mathcal O(L_QL_K) O(LQLK),并且LSE操作存在潜在的数值稳定性问题。因此,我们提出了一种对queries稀疏性度量的近似方法。
(3)引理1
对于每个query q i ∈ R d \textbf q_i∈\mathbb R^d qi∈Rd和keys集和 K \textbf K K中的 k j ∈ R d \textbf k_j∈\mathbb R^d kj∈Rd,我们的边界为 l n L K ≤ M ( q i , K ) ≤ m a x j { q i k j T d } − 1 L K ∑ j = 1 L K { q i k j T d } + l n L K ln~L_K≤M(\textbf q_i,\textbf K)≤max_j\{\frac{\textbf q_i\textbf k^T_j}{\sqrt d}\}−\frac{1}{L_K}\sum^{L_K}_{j=1}\{\frac{\textbf q_i\textbf k^T_j}{\sqrt d}\}+ln~L_K ln LK≤M(qi,K)≤maxj{
dqikjT}−LK1∑j=1LK{
dqikjT}+ln LK。当 q i ∈ K \textbf q_i∈\textbf K qi∈K时,它也成立。
根据引理1(证明在附录D.1中给出),我们提出最大均值测量为:
M ‾ ( q i , K ) = m a x j { q i k j T d } − 1 L K ∑ j = 1 L K { q i k j T d } . (4) \overline{M}(\textbf q_i,\textbf K)=max_j\{\frac{\textbf q_i\textbf k^T_j}{\sqrt d}\}−\frac{1}{L_K}\sum^{L_K}_{j=1}\{\frac{\textbf q_i\textbf k^T_j}{\sqrt d}\}.\tag{4} M(qi,K)=maxj{
dqikjT}−LK1j=1∑LK{
dqikjT}.(4)
Top-u的顺序在命题1的边界松弛中成立(请参阅附录D.2中的证明)。在长尾分布下,我们只需要随机采样 U = L Q l n L K U=L_Q~ln~L_K U=LQ ln LK个点积对来计算 M ‾ ( q i , K ) \overline M(\textbf q_i,\textbf K) M(qi,K),即用零填充其他对。 我们从它们中选择稀疏 T o p − u Top-u Top−u作为 Q ‾ \overline \textbf Q Q。 M ‾ ( q i , K ) \overline M(\textbf q_i,\textbf K) M(qi,K)中的max运算符对零值不敏感,并且数值稳定。在实践中,queries和keys的输入长度通常是相等的,即 L Q = L K = L L_Q=L_K=L LQ=LK=L,这样总的ProbSparse自注意力时间复杂度和空间复杂度为 O ( L l n L ) \mathcal O(L~ln~L) O(L ln L)。
(4)命题1
假设 k j ∼ N ( µ , Σ ) \textbf k_j\sim \mathcal N(µ,Σ) kj∼N(µ,Σ),令 q k i \textbf q\textbf k_i qki表示集合 { ( q i k j T ) / d ∣ j = 1 , . . . , L K } \{(\textbf q_i\textbf k^T_j)/\sqrt d|j=1,...,L_K\} {
(qikjT)/d∣j=1,...,LK},那么 ∀ M m = m a x i M ( q i , K ) ∀Mm=max_i~M(\textbf q_i,\textbf K) ∀Mm=maxi M(qi,K),存在 κ > 0 κ> 0 κ>0,使得:在区间 ∀ q 1 , q 2 ∈ { q ∣ M ( q , K ) ∈ [ M m , M m − κ ) } ∀\textbf q_1,\textbf q_2∈\{\textbf q | M(\textbf q,\textbf K)∈[M_m,M_{m}-κ)\} ∀q1,q2∈{
q∣M(q,K)∈[Mm,Mm−κ)}中, 如果 M ‾ ( q 1 , K ) > M ‾ ( q 2 , K ) \overline M(\textbf q_1,\textbf K)>\overline M(\textbf q_2,\textbf K) M(q1,K)>M(q2,K)且 V a r ( q k 1 ) > V a r ( q k 2 ) Var(\textbf q\textbf k_1)>Var(\textbf q\textbf k_2) Var(qk1)>Var(qk2),则很有可能 M ( q 1 , K ) > M ( q 2 , K ) M(\textbf q_1,\textbf K)>M(\textbf q_2,\textbf K) M(q1,K)>M(q2,K)。为简化起见,在证明中给出了概率的估计。
3.2 编码器:允许在内存使用限制下处理更长的输入序列
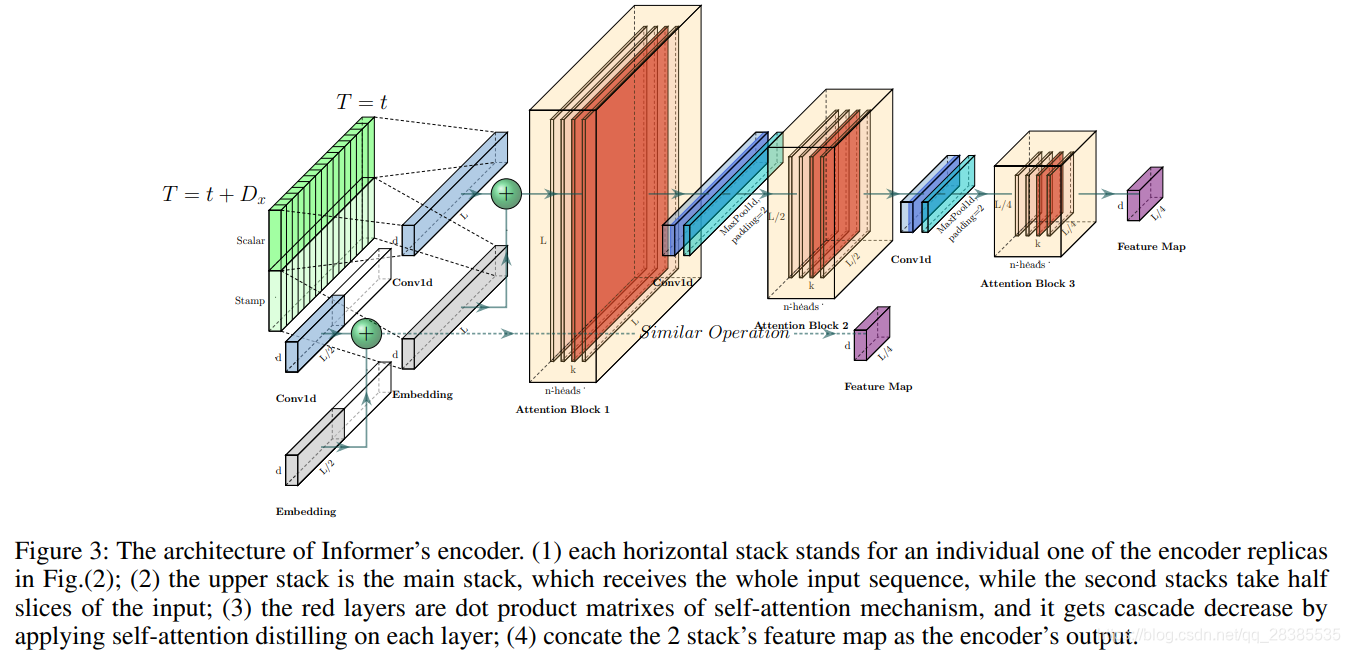
编码器被设计用于提取长序列输入的长期相关性。在输入表示之后,第 t t t时刻序列输入 X t \mathcal X^t Xt已变换为矩阵 X f e e d _ e n t ∈ R L x × d m o d e l \textbf X^t_{feed\_en}∈\mathbb R^{L_x×d_{model}} Xfeed_ent∈RLx×dmodel。为了清楚起见,我们在图(3)中给出了编码器的草图。
(1)Self-attention Distilling
作为ProbSparse自注意力机制的自然结果,编码器的特征图具有值 V \textbf V V的冗余组合。我们使用蒸馏操为主要特征赋予特权,并在下一层制作聚焦的自注意力特征图。看到图(3)中Attention块的n头权重矩阵(重叠的红色正方形),它会急剧地修剪输入在时间上的维度。受空洞卷积的启发,我们从第 j j j层到第 ( j + 1 ) (j+1) (j+1)层的“蒸馏”过程如下,
X j + 1 t = M a x P o o l ( E L U ( C o n v 1 d ( [ X j t ] A B ) ) ) , (5) \textbf X^t_{j+1}=MaxPool(ELU(Conv1d([\textbf X^t_j]_{AB}))),\tag{5} Xj+1t=MaxPool(ELU(Conv1d([Xjt]AB))),(5)
其中 [ ⋅ ] A B [·]_{AB} [⋅]AB包含多头ProbSparse自注意力和注意力块中的基本操作,具有 E L U ( ⋅ ) ELU(·) ELU(⋅)激活函数的 C o n v 1 d ( ⋅ ) Conv1d(·) Conv1d(⋅)在时间维度上执行一维卷积滤波器(核宽度=3)。我们添加了一个最大步长为2的最大池化层,并在堆叠一层后将 X t \textbf X^t Xt下采样到其长度的一半,这将整个内存使用量减少为 O ( ( 2 − ϵ ) L l o g L ) \mathcal O((2-\epsilon)L~log~L) O((2−ϵ)L log L),其中\epsilon为一个小数。为了增强蒸馏操作的鲁棒性,我们将主栈的副本复制了一半,并通过一次丢弃一层来逐渐减少自注意力蒸馏层的数量,如图(3)中的金字塔所示,以使它们的输出尺寸对齐。因此,我们将所有堆栈的输出连接起来,从而得到最终编码器的隐藏表示。
3.3 解码器:通过一个正向过程生成长序列输出
我们使用如图(2)所示的标准的解码器结构,它由2个相同的多头注意力层的堆栈组成。但是,在长时间预测中,采用了生成推理来缓解速度瓶颈。我们向解码器提供以下向量:
X f e e d _ d e t = C o n c a t ( X t o k e n t , X 0 t ) ∈ R ( L t o k e n + L y ) × d m o d e l , (6) \textbf X^t_{feed\_de}=Concat(\textbf X^t_{token},\textbf X^t_0)\in \mathbb R^{(L_{token}+L_y)\times d_{model}},\tag{6} Xfeed_det=Concat(Xtokent,X0t)∈R(Ltoken+Ly)×dmodel,(6)
其中 X t o k e n t ∈ R L t o k e n × d m o d e l \textbf X^t_{token}∈\mathbb R^{L_{token}×d_{model}} Xtokent∈RLtoken×dmodel是起始字符, X 0 t ∈ R L y × d m o d e l \textbf X^t_0∈\mathbb R^{L_y×d_{model}} X0t∈RLy×dmodel是目标序列的占位符(将标量设置为0)。通过将被屏蔽的点积设置为 − ∞ -∞ −∞,从而在ProbSparse自注意力计算中应用了屏蔽的多头注意力。它可以防止每个位置都参与到下一位置,从而避免了自回归。一个完全连接的层将获取最终输出,其输出维度 d y d_y dy取决于我们执行的是单变量预测还是多变量预测。
(1)Generative Inference
在NLP的“动态解码”中,开始字符是一种有效的技术,我们将其扩展为一种生成方式。我们没有选择特定的字符作为开始,而是在输入序列中采样了 L t o k e n L_{token} Ltoken长序列,该序列是输出序列之前的较早切片。以图2(b)中预测168个点为例(7天温度预测),我们将目标序列之前的已知5天作为“ start-token”,并将 X f e e d _ d e = { X 5 d , X 0 } \textbf X_{feed\_de}=\{\textbf X_{5d},\textbf X_0\} Xfeed_de={
X5d,X0}馈入生成式推理解码器。 X 0 \textbf X_0 X0包含目标序列的时间戳,即目标周的上下文。请注意,我们提出的解码器通过一种前向过程预测所有输出,并且摆脱了琐碎的编码器-解码器体系结构中耗时的“动态解码”方法。计算效率部分提供了详细的性能比较。
(2)Loss function
我们选择用于目标序列预测的MSE损失函数,并且损失会在整个模型中从解码器的输出传播回去。