文献阅读(48)—— 长序列time-series预测【Informer】
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting

AAAI(被评为AAAI2021最佳!足见其内容和实力!)
先验知识/知识拓展
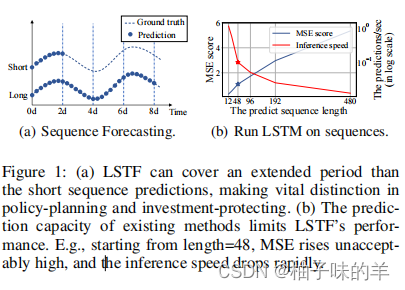
- 现在很多模型对于短时间序列(未来几天,几个时间点)的预测性能还不错,但是当遇到长时间序列(未来一年甚至未来几年)模型的预测性能下降
- 长序列长时间预测依赖于模型有较高的预测能力,这要求精确有效的捕获输入和输出之间长期的依赖关系
- LSTM模型的性能与输入序列的长度呈负相关。随着输入序列长度的增加,模型的性能下降
文章结构
- 摘要
- introduction
- preliminary
- methodology★
- experiment★
- results and analysis★
- conclusions
文章方法
1. 文章核心网络结构
作者提出了以encoder-decoder为主要架构的Informer(看名字大家应该可以想到transformer了,是的,它的思想就是借鉴了transformer,很多地方的设计思想都源于transformer!)用于解决长序列时间序列预测(Long Sequence Time-series Forecasting) [LSTF]
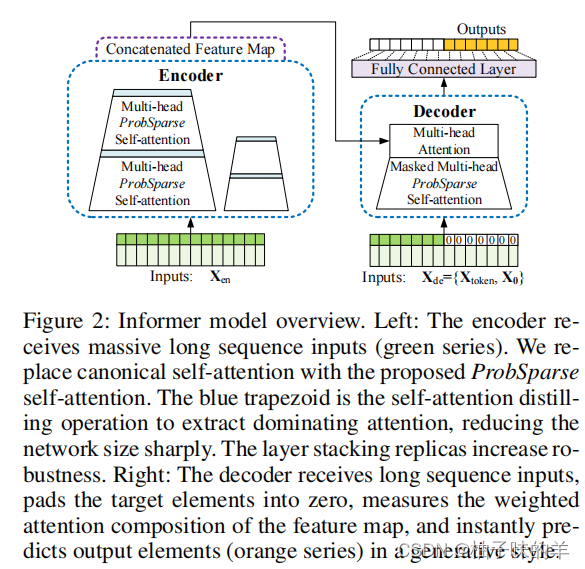
(1) 传统意义上的transformer应用在LSTF上的局限
- 自注意力机制导致时间复杂度达到L²
- 当遇到长序列时,内存的利用率达到JL²,和序列长度的平常成正比——瓶颈!
- 长期输出的速度慢!!效率低,传统的模型得到的输出类似于RNN是step-by-step 的(根据当下预测的结果去预测下一个结果,步步紧密依赖)

(2)informer的contributions
- ★ 提高了LSTF的预测性能,可以有效的捕捉到长期的输入和输出之间的依赖关系
- 提出probsparse自注意力机制,时间复杂度和空间复杂度都为O(L log(L))
- 提出了自注意力蒸馏,序列从(96——>48)逐渐缩小,使长序列也不受影响
- 生成式的decoder,可以一次性输出未来的预测结果,代替了之前step-by-step的想法


2. 自注意力机制
- 传统意义上的自注意力机制:

每个qkv都是一个矩阵,那么第i行的q的注意力可以写为:

- 作者发现在矩阵中很多位置之间是没有必然联系的,就出现了长尾现象。(只有少数点之间有相关性,绝大部分点都没有很大的关联性的。)因此作者提出了一个概念就是针对这种现象,主需要找到那些具有强相关性的q,对其进行自注意力机制,对于那些没有必然联系的q,直接赋值为平均值。
- 因为是分布,所以这个地方引入KL散度来衡量两个分布的相似性,对于和平均有很大差异的q进行自注意力机制的计算,和平均没有明显差异的直接赋平均值
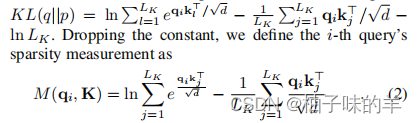
- 根据上述提到的这种方法,精简后的自注意力机制为:

3. Encoder:支持在有限的内存空间处理输入长序列
- encoder用于提取长序列输入的依赖性
- 自注意力蒸馏:encoder特征作为ProbSparse 自注意力机制的输出,encoder生成的特征是和value值做相关后的结果
- 使用蒸馏的方式减少了输入序列的长度(96变48)(使用maxpooling)
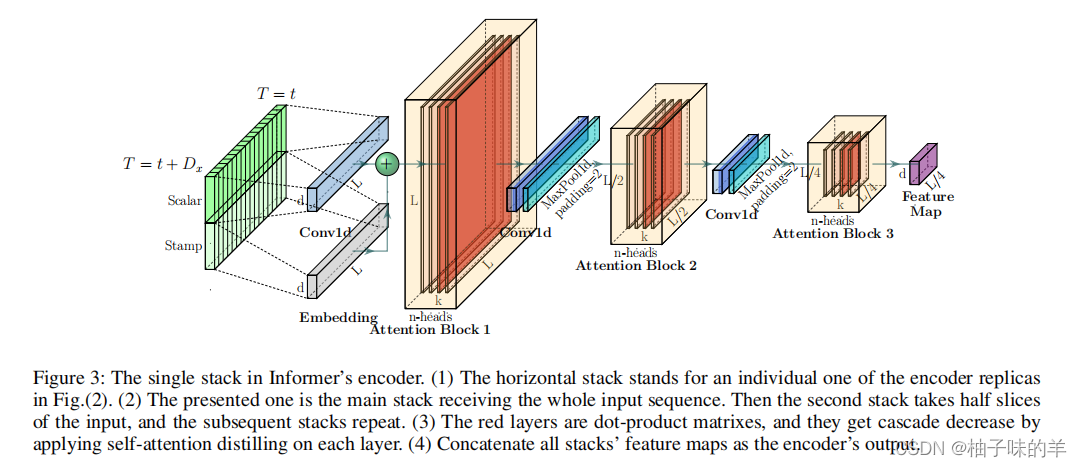
就很奇妙!
4. Decoder:一次性生成长序列预测输出值
- 使用generative inference缓解长序列预测速度下降的问题
(1)generative inference
- decoder部分由两部分组成:start-token 和 target-token

可以理解为先教他学一会儿,剩下的自己生成。其中target-token是有时间戳的。
5. loss function
- MSE
- MAE
不做详细介绍,关于loss可见之前的blog[几种常见的loss函数]
文章结果
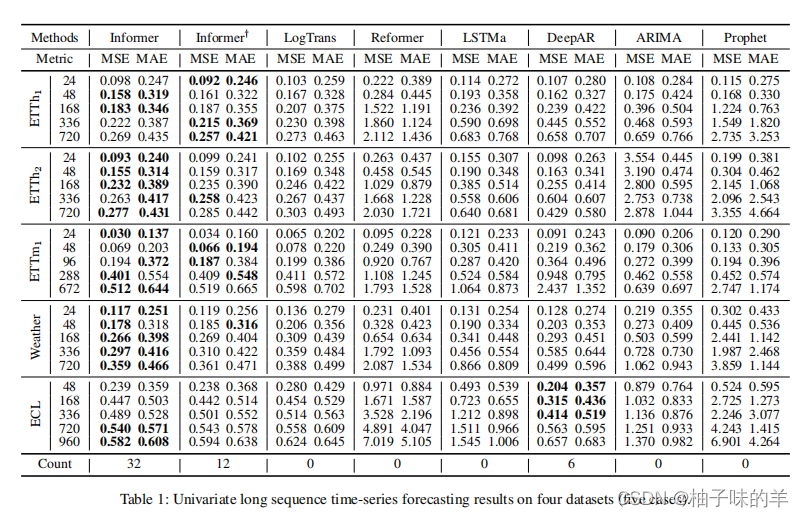
1. 单变量长序列time-series预测
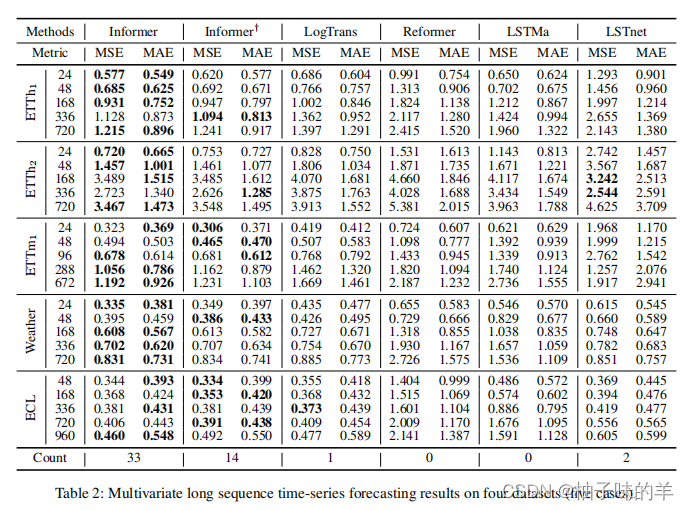
2. 多变量长序列time-series预测
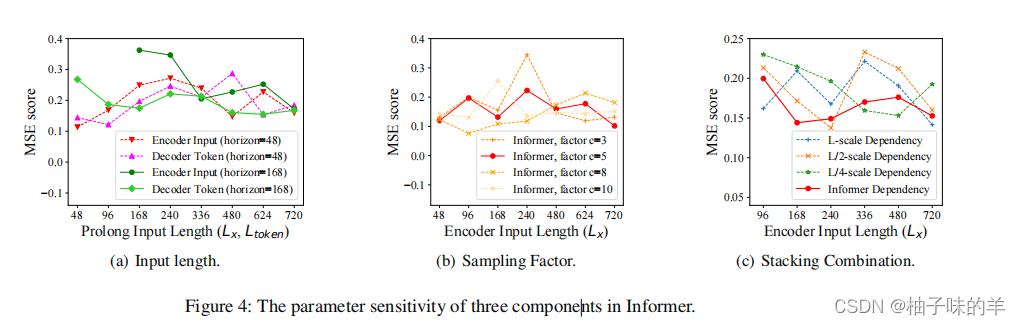
3.模型参数的敏感性分析
从左到右依次是:
- 输入长度(48和168)对预测长度的影响
- ProbSparse 自注意力机制中控制信息的带宽
- The Combination of Layer Stacking(这个我看文献没懂,我准备去源码中理解,看起老像是将两者拼接的程度系数)
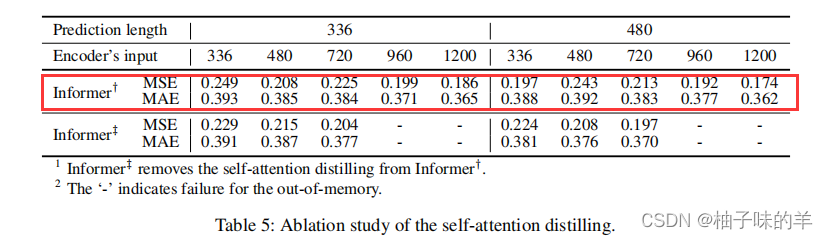
4. ProbSparse 自注意力机制
5. 生成式的decoder设计
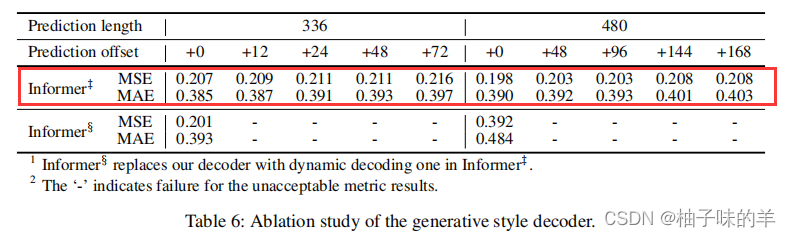
6.整体计算性能
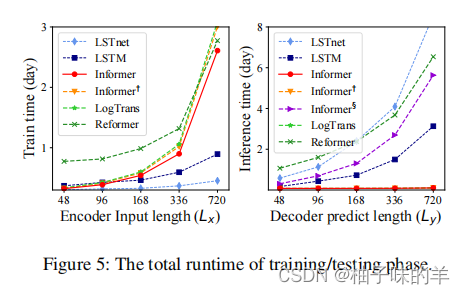
总结
1. 文章优点
- 能发在AAAI上已经是最大最亮的优点了吧!!够亮了!!
- encoder部分分析了长尾问题,提出了一个稀疏性的自注意力机制。找到相关性大的重点关注,其他部分赋予平均值
- decoder部分使用部分已知值作为结果的一部分
- 文章写的真的很好,大家都去给我读!!
2. 文章不足
- 小趴菜不配评论
可借鉴点/学习点?
- 全篇都值得我学!