一、论文简述
1. 第一作者:Shiyu Zhao
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:光流、深度学习、自注意力、匹配优化
5. 探索动机:先前基于能量的优化方法由于无法获得远距离运动对应,通常无法处理大位移。为了解决这个问题,匹配优化方法在优化之前引入了一个匹配步骤,其目的是找到像素或块之间的对应关系。然而,它们的匹配过程依赖于复杂的手工特征,耗时且不准确。基于神经网络直接回归的光流估计方法不能明确地捕获长距离运动的相关性,不能有效处理大的运动。
6. 工作目标:本文受基于能量的优化方法带来匹配优化方法的改进的启,发引入了一个匹配步骤,以明确处理直接回归方法中的大位移处理。
7. 核心思想:基于这一思想,提出了一种新的光流估计框架,即全局匹配光流网络GMFlowNet,它在直接回归之前引入了全局匹配。
- We introduce a global matching step to explicitly handle large displacement optical flow estimations for direct-regression methods. With typical 4D cost volumes, our global matching is effective and efficient.
- We propose a well designed Patch-based OverLapping Attention (POLA) to address local ambiguities in matching and demonstrate its effectiveness via extensive experiments.
- Following traditional matching-optimization frameworks, we propose a learning-based matching-optimization framework named GMFlowNet that achieves state of the art performance on standard benchmarks.
8. 实验结果:
- Extensive experiments demonstrate that GMFlowNet significantly outperforms the most popular optimization-only model RAFT and achieves stateof-the-art performance.
- GMFlowNet provides better flow estimations especially for large motion areas and textureless regions.
- We thoroughly investigate our global matching and POLA, showing that they are both effective and efficient.
9.论文下载:
https://github.com/xiaofeng94/GMFlowNet
二、实现过程
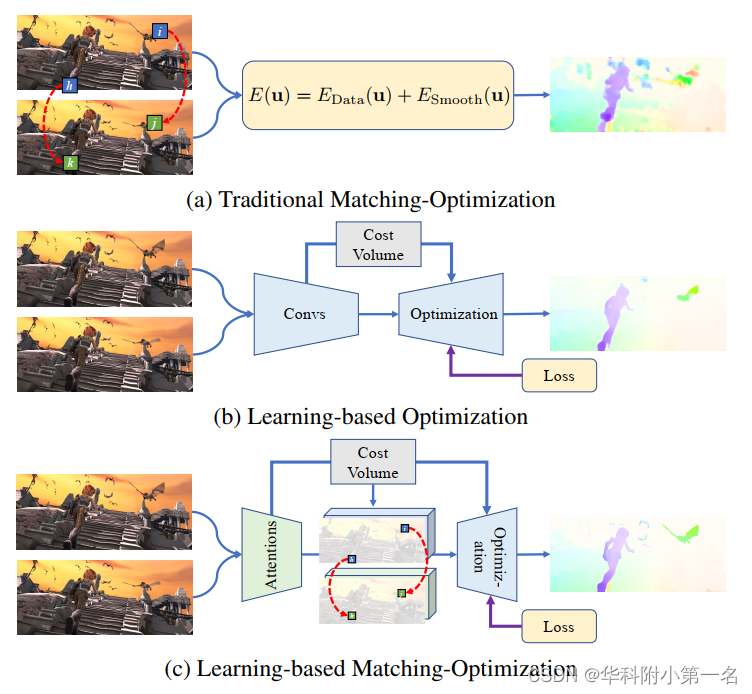
1. 框架对比
光流估计的主要框架。(a)传统的匹配优化方法首先建立稀疏匹配得到粗光流,然后利用基于能量的优化来改进光流。(b)直接回归方法用学习参数模拟基于能量的优化。它们可以被视为没有匹配的基于学习的优化。(c)我们的框架在基于学习的优化之前引入匹配,进一步提高了性能。
2. GMFlowNet概述
新的框架GMFlowNet在基于学习的优化之前引入了一个简单有效的全局匹配,由三个模块组成,即大上下文特征提取、全局匹配和基于学习的优化。
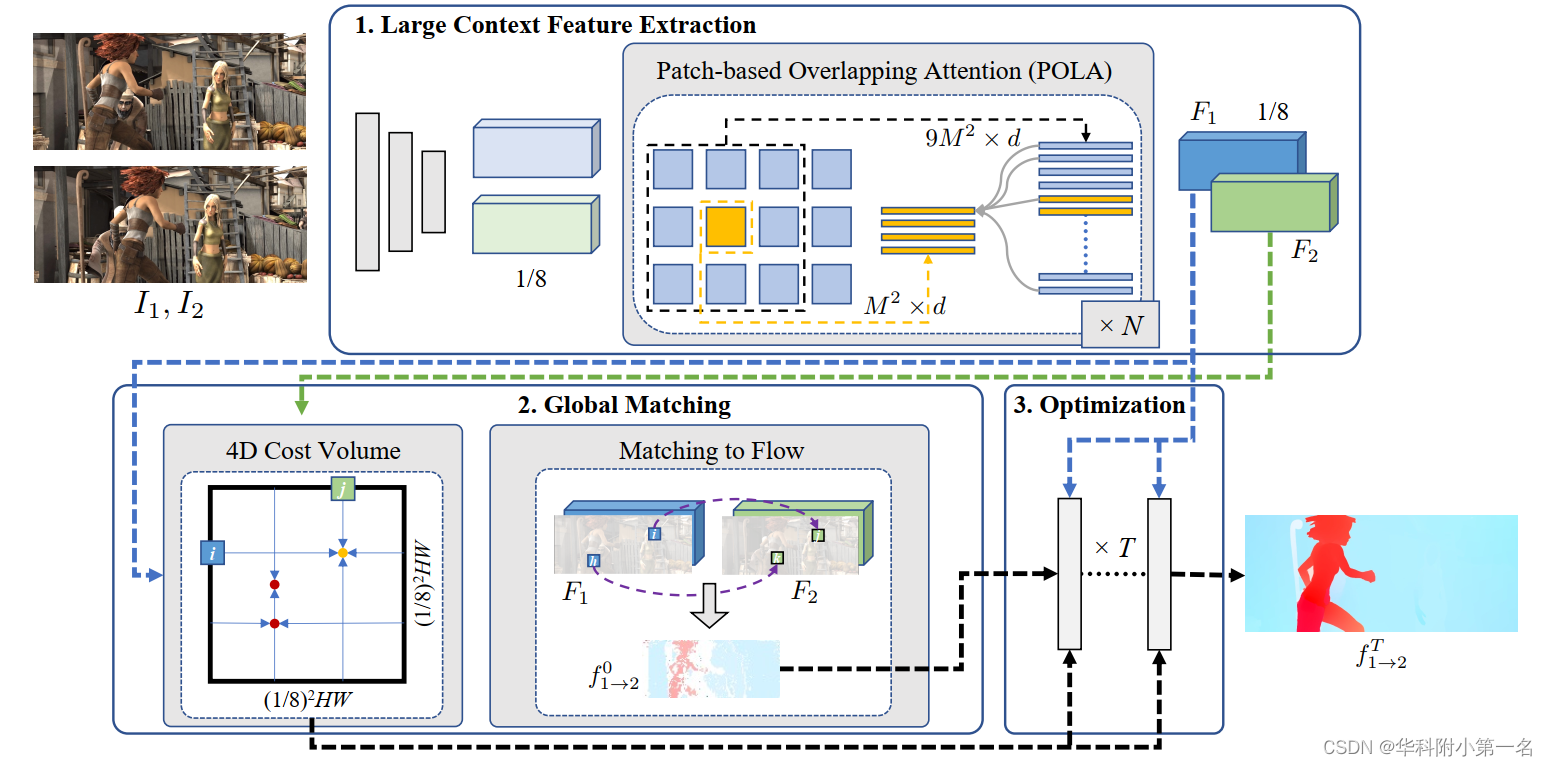
3. 大上下文特征提取
大的上下文信息是处理局部模糊位置匹配的关键,例如重复模式和无纹理区域。 GMFlowNet首先采用3个连续层(3-Convs)来提取初始特征,然后采用Transformer块来包含长距离特征信息。 由于图像特征的维数很大,考虑到计算量没有在整个特征图上使用普通的自注意力,为此设计了一个用于光流估计的局部定位模块POLA。
基于块的重叠注意力。POLA将特征划分为M×M非重叠的patch,处理每个及其相邻8个的patch,采用多头注意力。给定一个向量化的patch为P,其周围的3×3paches为S。在注意力中的第i个头,首先用线性投影将P和S投影到dk维数,投影后为Pi和Si;再用Pi和Si算注意力,得到输出Hi; 最后,将所有头的Hi连接为H,并将H投影到D维,作为最终结果O∈M×d。可以表述为:
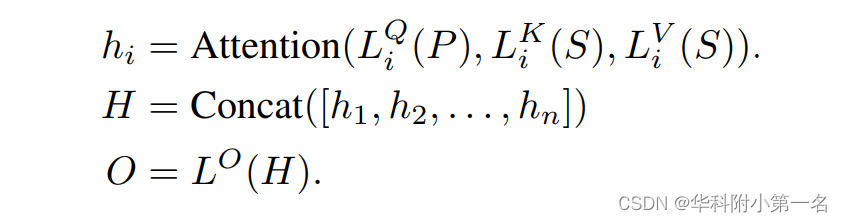
n是头数,L是线性投影函数。在实验中,设n =8, dk=d/n。
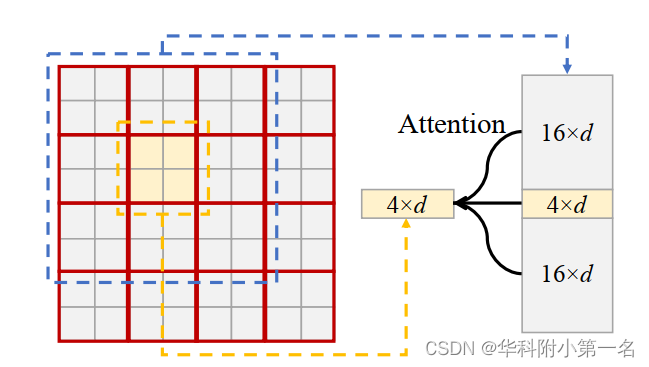
为什么POLA是一种改进的注意力方法。Swin Transformer有一个固定窗口和一个滑动窗口,而滑动窗口需要2个单独的注意力块来进行patch间信息的交换,这会导致信息丢失,不利于匹配,因为匹配严重依赖上下文信息来减少局部歧义。POLA在一个块内包含patch间的特征,直接进行信息交换,信息损失较小。与逐像素方式的相比,POLA的优势在于:消耗的内存更少;可以在现有的深度学习平台上高效实现;通过patch排列特征可以获得更好的性能。

4. 全局匹配
分别为第一个输入图像I1和第二个输入图像I2提取上下文特征F1和F2。然后,构建F1和F2的4D代价体。之后,在代价体中计算全局匹配,输出粗光流,作为优化的初始状态。
4D代价体计算。在输入分辨率的1/8上构建4D代价体。
匹配置信度计算。用双softmax算子将代价体转换为匹配置信度。该算子效率高,能够对匹配进行监督。匹配置信度Pc的计算公式为:
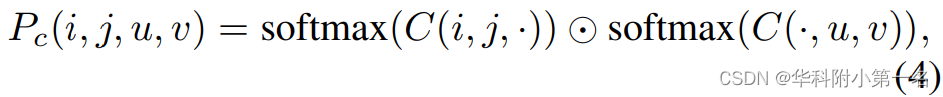
其中C(i,j; ·)指所有(u,V)给定(i,j),C(·,u,V)是相似的。
匹配的选择和流的生成。根据匹配置信度Pc,得到了I1在(i,j)处的匹配:
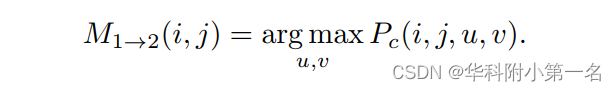
同样获得I2的M2→1。然后,选取满足M1→2(i,j)和M2→1(u,v),定义匹配集Mc:
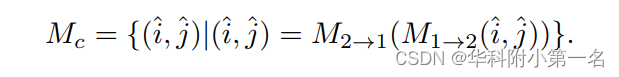
粗光流计算为:
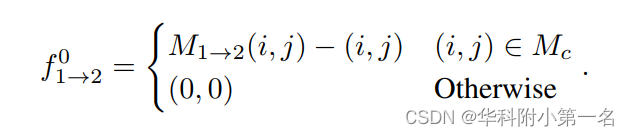
5. 优化
使用RAFT中现有的更新操作符作为我们的优化。这种优化预测一个增量光流,并将其添加到当前的光流估计中。它在这样的加法上迭代并输出一系列光预测。本文用粗光流f0代替RAFT中使用的零光来初始化优化。GMFlowNet的优化部分是可替换。本文采用RAFT,因为它达到了最好的性能。任何未来的优化都可以在这里应用以进一步改进。
6. 监督
匹配损失。将真实光流fgt轮合到像素级,收集真实匹配集Mgt。如果区域在两个帧中都出现,认为它们是匹配的,并将遮挡区域设置为不匹配的。作为特征匹配中的监督,将匹配区域Pc的负对数似然最小化为:
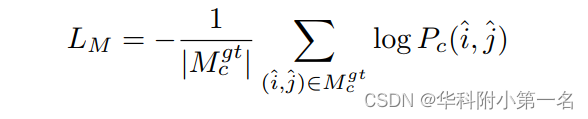
优化损失。遵循RAFT,并以预测光流与fgt之间的l1距离为监督优化。优化损失定义为:
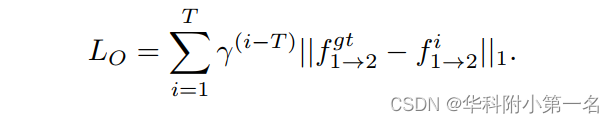
GMFlowNet的整体损失函数为:
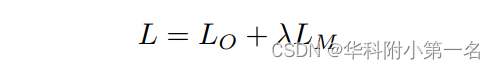
λ平衡不同的损失项。
7. 实验
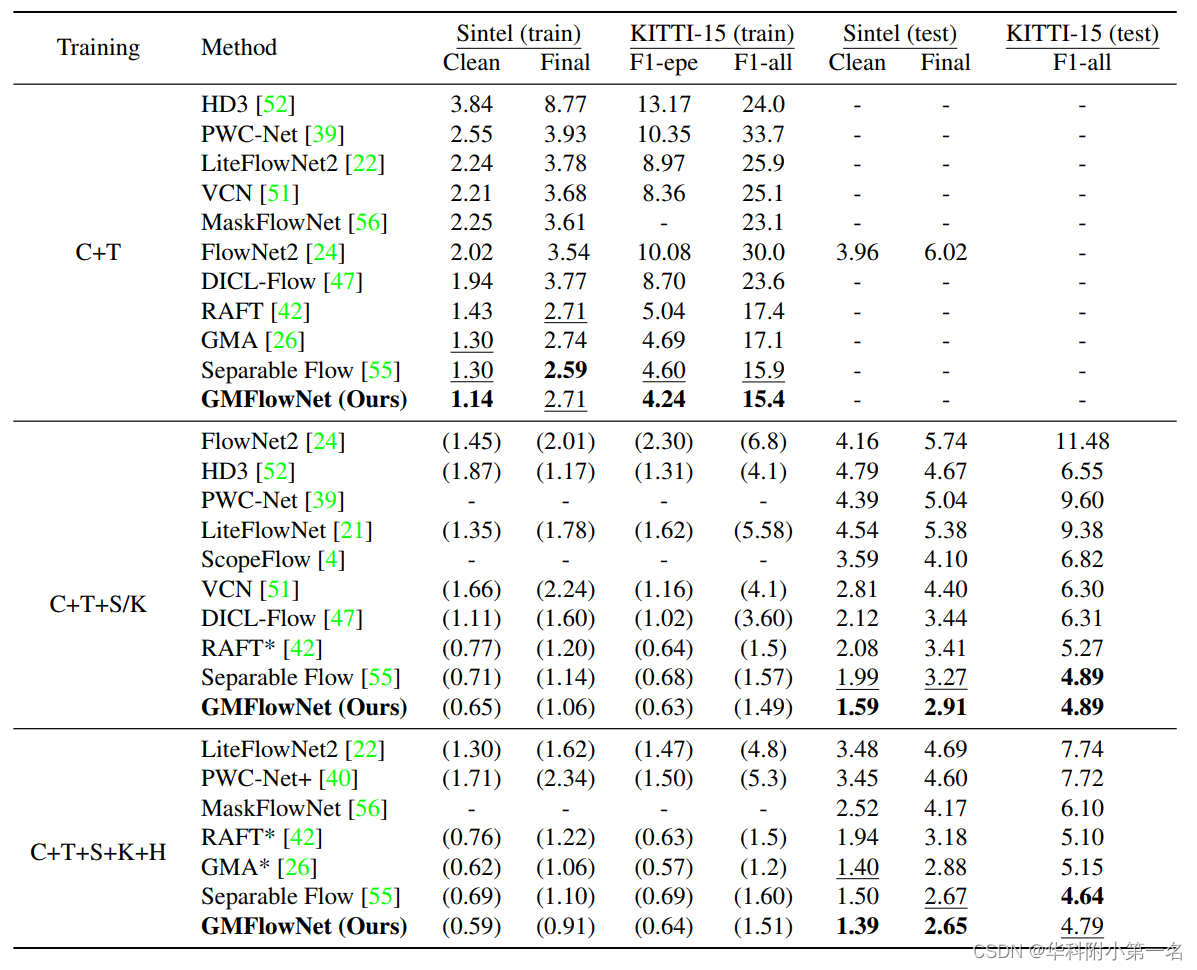
7.1. 定量评估
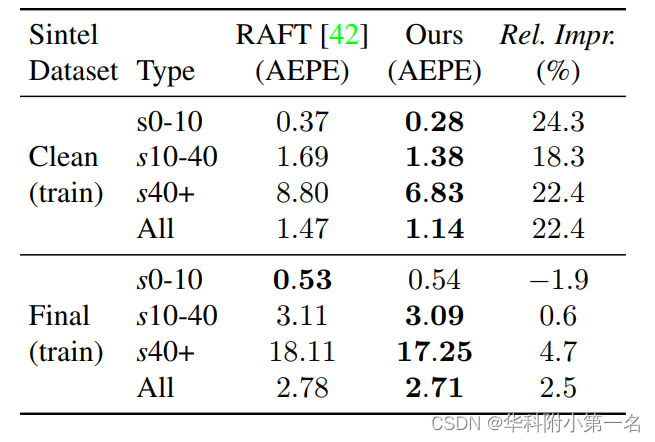
不同位移下的表现。将Sintel训练集划分为s10,s10-40,s40+子集,在C+T数据集上训练GMFlowNet,以RAFT为基准,在子集上评估,评价指标为AEPE。结果表明,GMFlowNet在位移极大的区域上有很大的改进,这说明具有大背景的全局匹配有利于处理较大的运动。
跨域评估/在标准基准上评估。在C+T数据集上训练,在S和K数据集上评估。结果表明GMFlowNet具有很好的泛化能力,将泛化能力的提高归功于全局匹配。
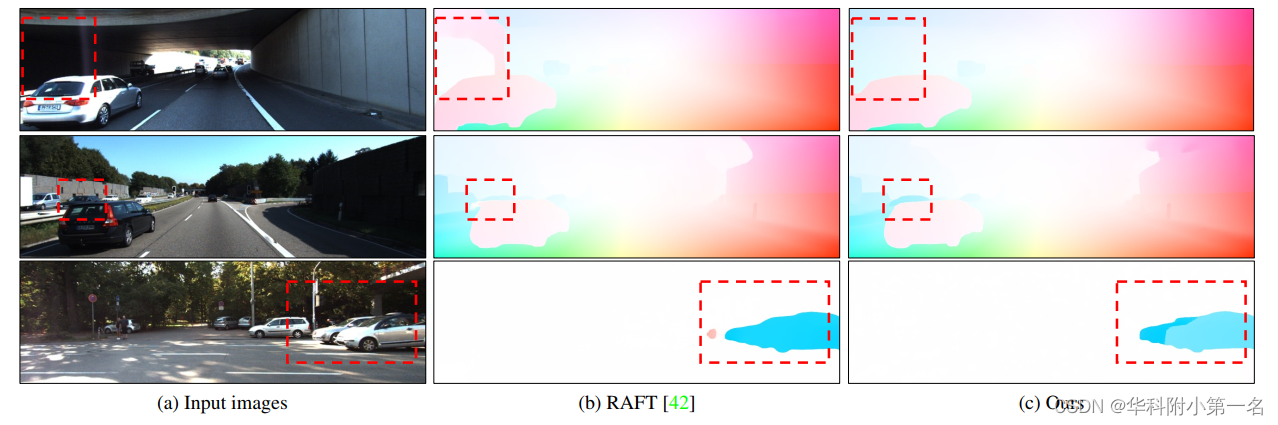
7.2. 定性评估
光流可视化。GMFlowNet对局部模糊区域,如无纹理区域提供了更好的预测.
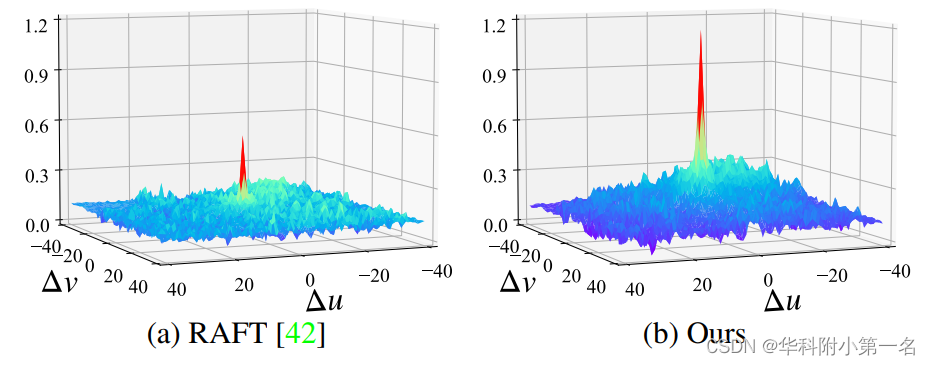
代价体可视化。GMFlowNet的代价体峰值远高于RAFT。
7.3. 消融实验
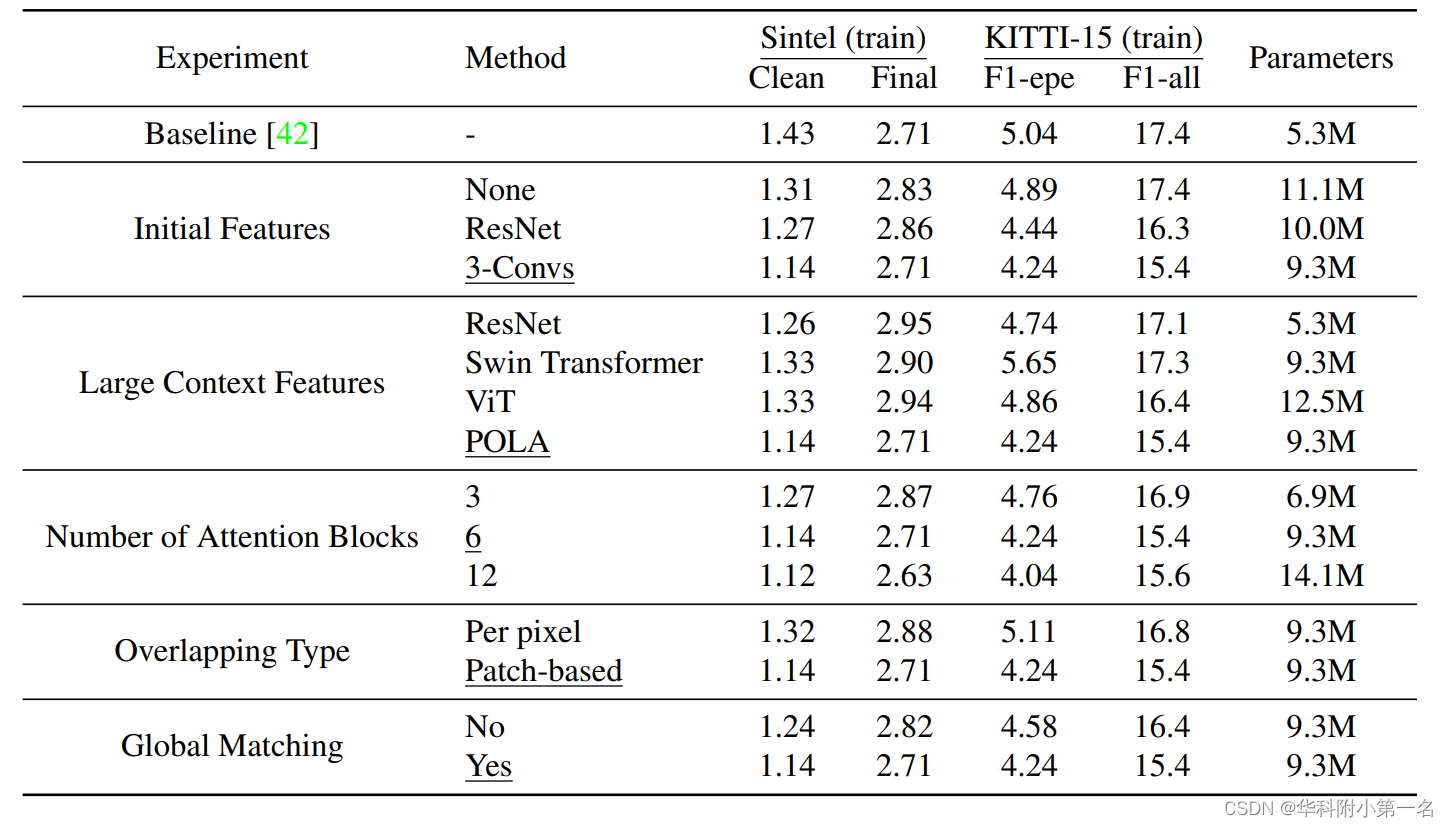
7.4. 效率
用RAFT和加入全局匹配的RAFT做对比试验,结果表明加入全局匹配后运行速度稍慢,但性能显著提高。与+Swin相比,GMFlowNet需要0.078秒的额外时间,考虑到性能的改进,这种开销是可以接受的。